qidao123.com技术社区-IT企服评测·应用市场
标题:
【Hive入门】Hive性能调优之资源配置:深入解析实行引擎参数调优
[打印本页]
作者:
瑞星
时间:
2025-5-2 14:20
标题:
【Hive入门】Hive性能调优之资源配置:深入解析实行引擎参数调优
目次
前言
1 Hive实行引擎概述
2 MapReduce引擎调优
2.1 Map阶段资源配置
2.2 Reduce阶段资源配置
2.3 并发控制参数
3 Tez引擎调优
3.1 Tez架构概述
3.2 内存配置
3.3 并发与并行度
4 Spark引擎调优
4.1 Spark实行模子
4.2 内存管理
4.3 并行度配置
5 资源隔离与队列管理
5.1 YARN资源分配
6 实战调优案例
6.1 大型聚合查询优化
6.2 数据倾斜处置惩罚
7 监控与诊断
7.1 关键监控指标
7.2 诊断工具
8 总结
前言
在大数据领域,Hive作为基于Hadoop的数据仓库工具,被广泛应用于企业级数据分析场景。然而,随着数据量的不断增长,Hive查询性能问题日益凸显。公道的资源配置是Hive性能调优的基础,本文将深入探讨怎样通过调解MapReduce、Tez和Spark三种实行引擎的内存与并发参数来优化Hive查询性能。
1 Hive实行引擎概述
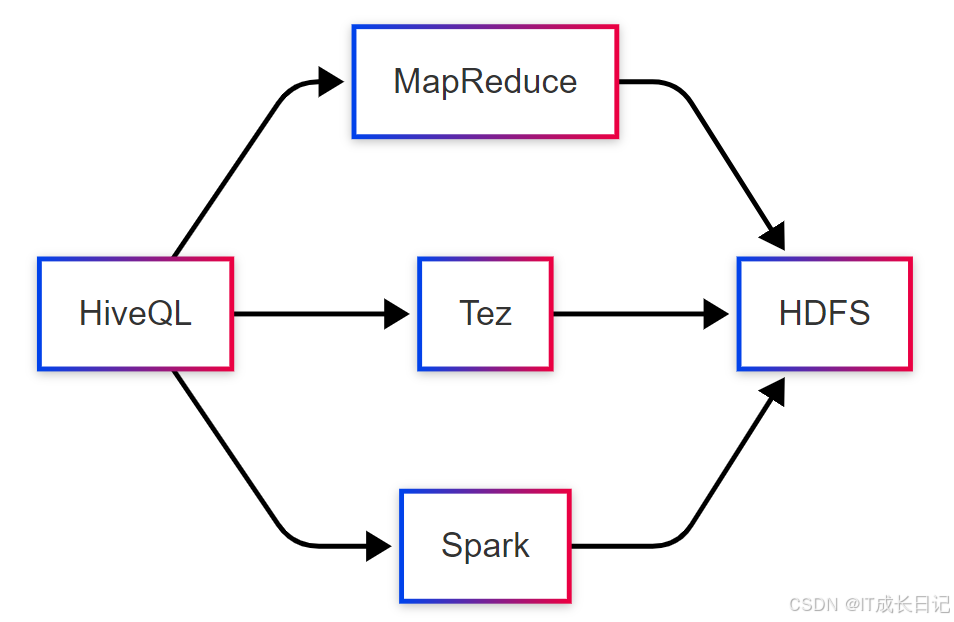
Hive支持多种实行引擎,每种引擎都有其独特的架构和适用场景:
实行引擎选择计谋
:
MapReduce
:适合稳定的批处置惩罚作业,资源斲丧可预测
Tez
:适合复杂DAG作业,淘汰中间结果落盘
Spark
:适合迭代计算和交互式查询,内存利用率高
2 MapReduce引擎调优
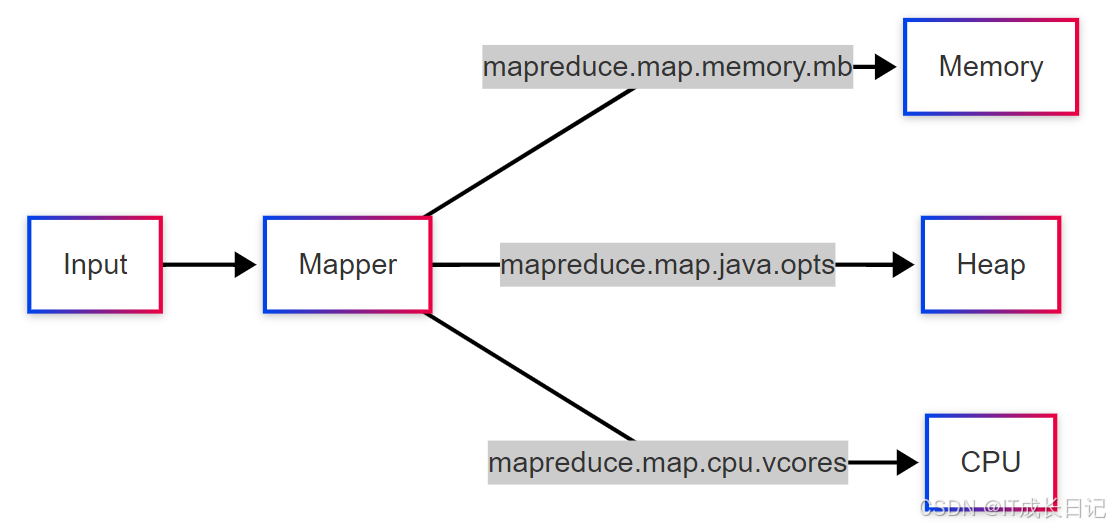
2.1 Map阶段资源配置
关键参数
:
mapreduce.map.memory.mb:单个Map任务分配的内存(MB)
mapreduce.map.java.opts:Map任务JVM堆内存(通常设为0.8*memory.mb)
mapreduce.map.cpu.vcores:每个Map任务分配的假造CPU核数
优化建议
:
对于CPU麋集型任务,增长vcores数量
对于内存麋集型任务,优先增长memory.mb
典范设置:memory.mb=4096,java.opts=-Xmx3276m
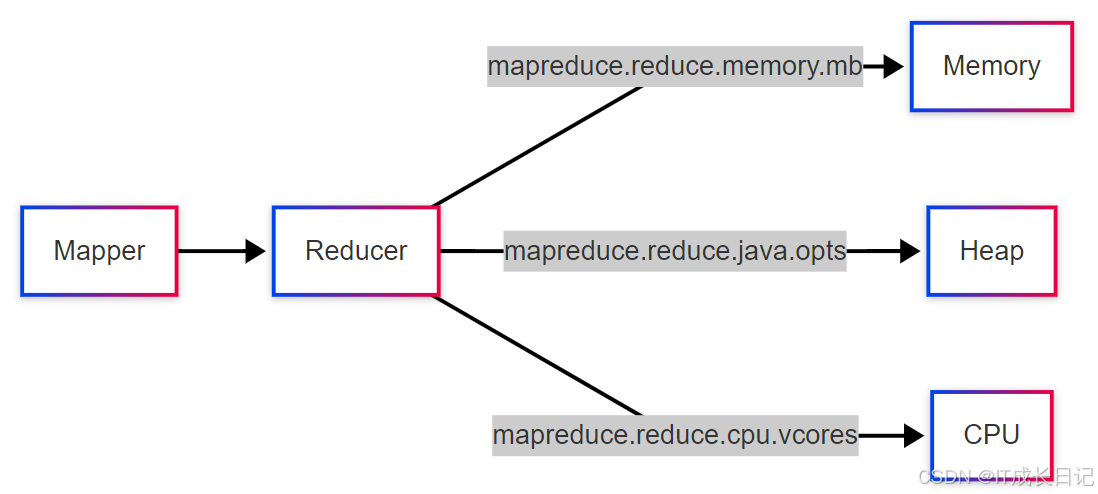
2.2 Reduce阶段资源配置
关键参数
:
mapreduce.reduce.memory.mb:单个Reduce任务分配的内存
mapreduce.reduce.java.opts:Reduce任务JVM堆内存
mapreduce.reduce.cpu.vcores:每个Reduce任务分配的假造CPU核数
优化原则
:
Reduce内存通常设置为Map内存的1.5-2倍
对于聚合操作多的查询,增长Reduce内存
典范设置:memory.mb=8192,java.opts=-Xmx6553m
2.3 并发控制参数
关键参数
:
mapreduce.job.maps:建议的Map任务数(实际由输入分片决定)
mapreduce.job.reduces:Reduce任务数(重要调优点)
hive.exec.reducers.bytes.per.reducer:每个Reducer处置惩罚的数据量
优化建议
:
对于大型聚合查询,得当淘汰bytes.per.reducer
对于数据倾斜场景,考虑设置hive.groupby.skewindata=true
3 Tez引擎调优
3.1 Tez架构概述
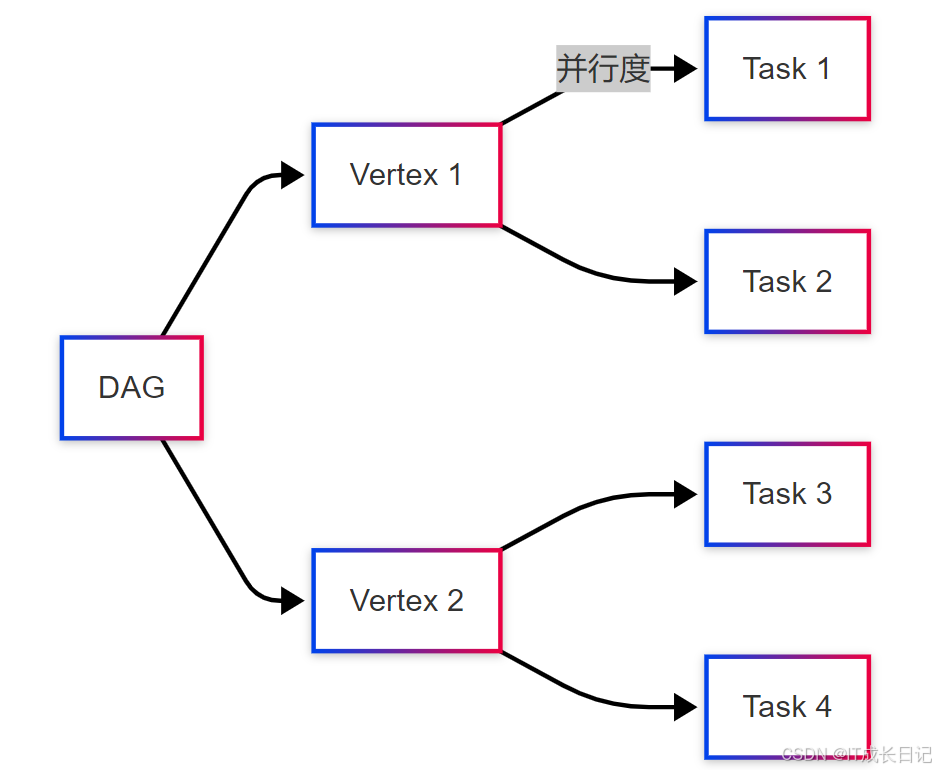
Tez通过DAG(有向无环图)实行计划,相比MapReduce淘汰了中间结果的落盘操作。
3.2 内存配置
关键参数
:
tez.am.resource.memory.mb:Application Master内存
tez.task.resource.memory.mb:每个任务容器内存
tez.runtime.io.sort.mb:排序时内存缓冲区巨细
优化建议
:
AM内存通常设置为4GB-8GB
任务内存根据操作复杂度设置,通常4GB-16GB
对于复杂查询,增长tez.runtime.io.sort.mb(默认100MB)
3.3 并发与并行度
关键参数
:
hive.execution.engine=tez
tez.grouping.split-count:控制Map任务数
tez.grouping.max-size:每个任务最大输入巨细
tez.grouping.min-size:每个任务最小输入巨细
优化本领
:
对于小文件问题,调解min-size/max-size归并输入
设置hive.tez.auto.reducer.parallelism=true自动优化Reduce并行度
4 Spark引擎调优
4.1 Spark实行模子
Spark通过内存中的RDD(弹性分布式数据集)实现高效迭代计算。
4.2 内存管理
关键参数
:
spark.executor.memory:每个Executor内存
spark.driver.memory:Driver内存
spark.memory.fraction:用于实行和存储的内存比例
spark.executor.memoryOverhead:堆外内存
优化建议
:
Executor内存通常设置为8G-32G
内存Overhead设为Executor内存的10%-15%
对于缓存麋集型作业,增长memory.fraction(默认0.6)
4.3 并行度配置
关键参数
:
spark.executor.instances:Executor数量
spark.executor.cores:每个Executor的核数
spark.default.parallelism:默认分区数
spark.sql.shuffle.partitions:Shuffle分区数
并行度计算公式
:
总并发数 = spark.executor.instances * spark.executor.cores
优化原则
:
每个Executor配置4-8个core为宜
shuffle.partitions通常设为executor.instances
executor.cores
2-3
避免单个Executor内存过大导致GC瓶颈
5 资源隔离与队列管理
5.1 YARN资源分配
关键配置
:
mapreduce.job.queuename:指定作业队列
yarn.scheduler.capacity.maximum-am-resource-percent:AM资源占比上限
最佳实践
:
根据业务优先级分别资源队列
设置队列最小/最大资源包管
限制单个作业资源使用量
6 实战调优案例
6.1 大型聚合查询优化
场景
:10TB数据表GROUP BY操作
优化步调
:
设置hive.exec.reducers.bytes.per.reducer=256MB
增长Reducer内存:mapreduce.reduce.memory.mb=12288
启用Map端聚合:hive.map.aggr=true
对于Tez:设置hive.tez.auto.reducer.parallelism=true
6.2 数据倾斜处置惩罚
解决方案
:
识别倾斜键:hive.skewjoin.key=100000
启用倾斜优化:hive.optimize.skewjoin=true
对倾斜键单独处置惩罚
使用随机前缀分散负载
7 监控与诊断
7.1 关键监控指标
资源利用率
:CPU、内存、IO
作业进度
:Map/Reduce完成百分比
Shuffle性能
:传输数据量、耗时
GC环境
:Full GC频率、耗时
7.2 诊断工具
EXPLAIN
:分析实行计划
日志分析
:查找OOM或长尾任务
YARN UI
:监控资源使用环境
Spark UI
:分析Stage实行详情
8 总结
资源配置黄金法则
:
内存配置
:预留足够堆外内存,避免OOM
并行度
:根据数据量和集群规模公道设置
引擎选择
:批处置惩罚用Tez,交互式用Spark
监控迭代
:持续监控,渐渐调优
参数模板示例(Tez引擎)
:
SET hive.execution.engine=tez; SET tez.am.resource.memory.mb=8192;
SET tez.task.resource.memory.mb=4096; SET hive.tez.container.size=4096;
SET hive.exec.reducers.bytes.per.reducer=268435456;
SET hive.tez.auto.reducer.parallelism=true;
复制代码
实际应用中,需要结合具体业务场景和数据特点,不断试验和调解参数,才能获得最佳性能表现。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4