IT评测·应用市场-qidao123.com技术社区
标题:
一文读懂K-Means原理与Python实现
[打印本页]
作者:
涛声依旧在
时间:
2022-6-26 03:19
标题:
一文读懂K-Means原理与Python实现
目录
一、K-Means原理
1.聚类简介
①分层聚类
②质心聚类
③其他聚类
2.K-means的原理
3.K-means的应用场景
二、K-Means的案例实战
1.数据查看
①数据导入及结构查看
②查看数据描述
2.数据可视化及预处理
①条形图
②热力图
③核密度图
④散点图
⑤箱型图
3.模型训练与精度评价
①样本选择
②模型训练
③精度评价
④模型调参
三、结论
在本文中,你将学会:
0 K-means的数学原理
1 K-means的Scikit-Learn函数解释
2 K-means的案例实战
一、K-Means原理
1.聚类简介
机器学习算法中有 100 多种聚类算法,它们的使用取决于手头数据的性质。我们讨论一些主要的算法。
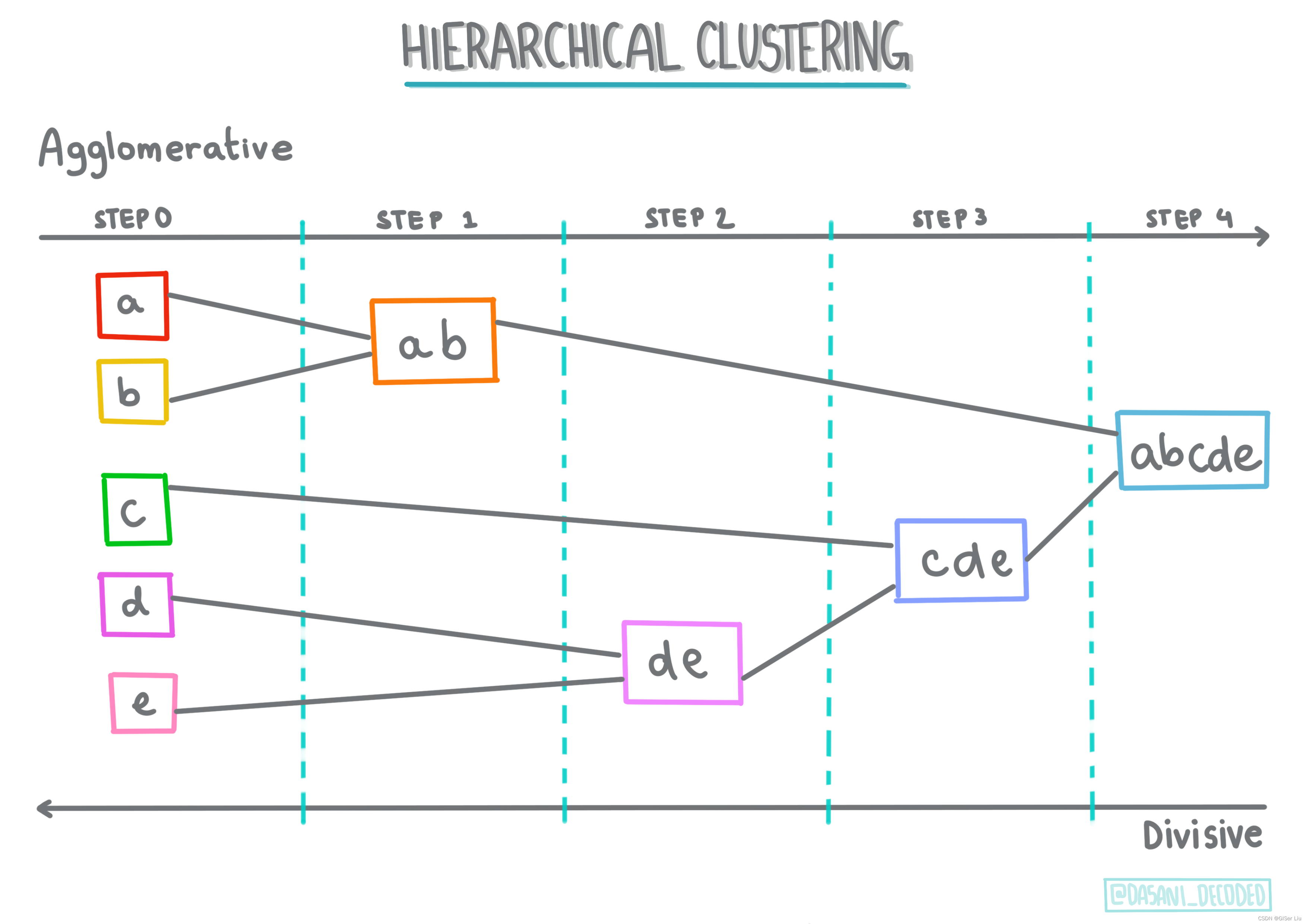
①分层聚类
分层聚类
。如果一个物体是按其与附近物体的接近程度而不是与较远物体的接近程度进行分类的,则根据其成员与其他物体之间的距离形成聚类。
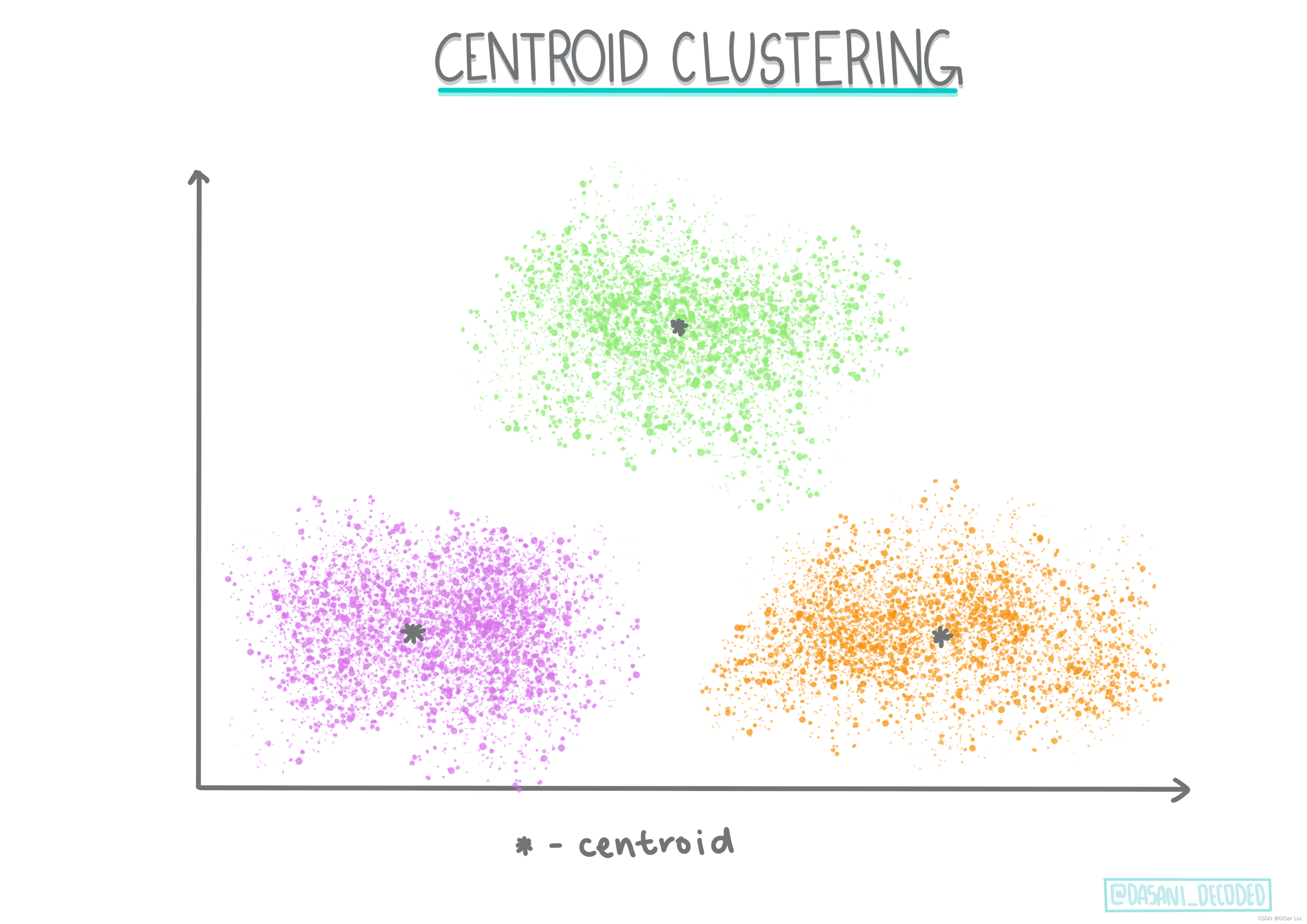
②质心聚类
质心聚类
。这种流行的聚类算法需要选择K(聚类数),之后算法确定聚类的质心点并围绕该点收集数据。
K 均值聚类
是质心聚类的流行版本。质心由其类别所有样本点之间的均值确定,因此得名。
③其他聚类
基于分布的聚类
。基于统计建模,基于分布的聚类分析侧重于确定数据点属于聚类的概率,并相应地分配它。高斯混合方法属于这种类型。
基于密度的聚类
。数据点根据其密度或彼此之间的分组分配给聚类。远离组的数据点被视为异常值或噪声。DBSCAN、均值偏移等都属于这种类型的聚类。
基于网格的群集
。对于多维数据集,将创建一个网格,并在网格的单元之间划分数据,从而创建聚类。
方便学习起见,本文中我们只讨论K-Means算法,其他聚类算法我会另外撰文讲解。
2.K-means的原理
先讲一个经典的K-means故事:
0
从前,有四个牧师去郊区步道,一开始牧师随便选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的居民,于是每个居民到离自己家最近的布道点去听课。
1
听课以后,大家觉得距离太远了,于是每个牧师统计了以下自己的课上所有的居民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
2
牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动后自己还不如去B牧师处听课更近,于是每个居民又去了离自己最近的布道点...就这样,牧师每个礼拜更新自己的位置,居民根据自己的情况选择布道点,最终稳定了下来。
这是K-means的计算步骤:
0
先定义总共有多少个类别(簇)
1
将每个簇心(质心)随机分配坐标位置
2
将每个样本数据点关联到离该样本点距离最近的质心上,即分配其类别
3
对于每个簇找到所有关联点的中心点(样本与质心欧氏距离的均值)
4
将该均值点作为该类别新的质心
5
如此训练,直到每个簇所拥有的点位置不在改变
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/)
Powered by Discuz! X3.4