qidao123.com技术社区-IT企服评测·应用市场
标题:
大型语言模型在网络安全范畴的应用综述
[打印本页]
作者:
火影
时间:
7 天前
标题:
大型语言模型在网络安全范畴的应用综述
简介
得益于大型语言模型(LLMs)的突破性进展,天然语言处理(NLP)在过去十年间实现了飞速发展。 LLMs 正徐徐成为网络安全范畴的一股强大力量,它们可以大概自动检测漏洞、分析恶意软件,并有效应对日益复杂的网络攻击。详细而言,LLMs 被广泛应用于
软件安全范畴
,可从代码和天然语言形貌中辨认漏洞,并生成相应的安全补丁。同时,LLMs 也被用于
分析安全策略和隐私政策
,帮助辨认潜在的安全违规举动。在网络安全范畴,LLMs 可以大概
检测和分类各种类型的攻击
,比方 DDoS 攻击和僵尸网络流量。此外,LLMs 还能根据文本报告和举动形貌
分析恶意软件
,检测恶意域名,并有效防御钓鱼攻击。总体而言,LLMs 通过处理和提取海量非布局化文本中的信息,从巨大数据库中学习模式,并生成相干的测试和训练样本,从而极大地提升网络安全实践的效率和效果,助力构建更加安全可靠的网络情况。
本报告基于一篇题为《Large Language Models for Cyber Security: A Systematic Literature Review》的系统文献综述,对 LLMs 在网络安全范畴的应用进行全面、深入的解析。报告起首介绍了 LLMs 的根本概念和发展历程,然后详细阐述了 LLMs 在软件和系统安全、网络安全、信息和内容安全、硬件安全、区块链安全等五大范畴的详细应用,并深入分析了差别 LLMs 架构(encoder-only、encoder-decoder、decoder-only)的特点和实用场景。报告还重点探究了 LLMs 应用于安全使命时所采用的范畴特定技术(如微调、提示工程、外部增强等)以及数据网络和预处理的方法。最后,报告总结了 LLMs 在网络安全范畴面临的挑衅,并预测了未来的研究方向和机遇。
论文所在:https://arxiv.org/html/2405.04760v3#S4
1. 弁言
1.1 背景与意义
网络安全威胁的演变:
随着互联网的普及和信息技术的快速发展,网络安全威胁日益复杂和多样化。传统的基于规则和特征的防御机制难以应对不停涌现的新型攻击手段,如零日漏洞攻击、高级持续性威胁(APT)等。
人工智能****在网络安全中的应用:
人工智能技术,特殊是机器学习和深度学习,为网络安全范畴带来了新的办理方案。比方,基于机器学习的入侵检测系统、恶意软件分类器等已经在实际应用中取得了一定的效果。
LLMs 的崛起:
比年来,大型语言模型(LLMs)的兴起为网络安全范畴带来了新的突破。LLMs 是基于 Transformer 架构并在海量文本数据上进行训练的深度学习模型,它们可以大概理解和生成人类语言,并在各种天然语言处理(NLP)使命中体现出色。
1.2 LLMs 的根本概念
Transformer 架构:
LLMs 的核心是 Transformer 架构,它采用自注意力机制(self-attention mechanism)来捕捉文本序列中差别单词之间的关系,从而实现对文本的深层理解。
预训练(Pre-training):
LLMs 通常在大规模无标注文本数据上进行预训练,学习通用的语言知识和模式。
微调(Fine-tuning):
预训练后的 LLMs 可以在特定使命的标注数据上进行微调,使其顺应特定使命的需求。
提示工程(Prompt Engineering):
通过计划合适的提示(prompt)来引导 LLMs 生成特定类型的输出。
1.3 LLMs 在网络安全中的优势
处理非布局化数据:
LLMs 可以大概处理大量的非布局化文本数据,如安全报告、漏洞形貌、恶意代码解释等,从中提取有价值的信息。
学习复杂模式:
LLMs 可以大概学习复杂的语言模式和语义关系,从而辨认潜在的安全威胁。
生成安全代码和报告:
LLMs 可以大概自动生成安全代码、漏洞修复补丁、安全报告等,进步安全工作的效率。
自动化安全使命:
LLMs 可以大概自动化执行各种安全使命,如漏洞检测、恶意软件分析、威胁谍报提取等,减轻安全职员的负担。
1.4 报告目标
本报告旨在对 LLMs 在网络安全范畴的应用进行全面、深入的解析,详细目标包括:
系统梳理 LLMs 在网络安全范畴的应用现状,涵盖差别安全范畴和详细使命。
分析差别 LLMs 架构的特点和实用场景,以及在网络安全使命中的应用情况。
探究 LLMs 应用于安全使命时所采用的范畴特定技术和数据处理方法。
总结 LLMs 在网络安全范畴面临的挑衅,并预测未来的研究方向和机遇。
2. 文献综述方法
本报告基于的系统文献综述采用了严格的流程来辨认、筛选和分析相干文献,以确保研究的全面性和客观性。
2.1 研究问题
文献综述围绕以下四个核心研究问题展开:
RQ1
:基于 LLM 的方法已对
哪些类型的网络安全使命
予以支持?在此,重点在于 LLM 在差别安全范畴应用的范畴与性质。目标是依据差别的安全范畴对先前的研究予以分类,并细致阐释每个安全范畴中运用 LLM 的多元安全使命。
RQ2
:哪些 LLM 被用于支持安全使命?此研究问题旨在列举在安全使命中所使用的详细 LLM。明晰所使用的 LLM 的多样性与特性,可以大概就其在差别安全应用中的机动性与实用性提供见解。我们将探究 LLM 的架构差异,并深入剖析
差别架构的 LLM 对差别时间段的网络安全研究
的影响。
RQ3
:有哪些范畴特定的技术被用于
使 LLM 适配于安全使命
?此研究问题探究了用于微调或适配 LLM 以用于安全使命的详细方法与技术。相识这些技术可以大概就增强 LLM 在特定使命中的有效性的定制流程提供宝贵见解。我们将通过剖析论文中应用于安全使命的 LLM,分析这些技术与特定安全使命之间的内在及特定关联。
RQ4
:在安全使命中应用 LLM 时,
数据网络和预处理
存在哪些差异?本研究问题旨在探寻数据处理和模型评估在安全情况中的独特挑衅与考量因素,考察 LLM 与特定使命所用数据之间的关联。我们将通过两个维度展现将 LLM 应用于安全使命时从数据中产生的挑衅:数据网络和数据预处理。此外,我们将总结数据、安全使命和 LLM 之间的内在关系。
2.2 文献检索策略
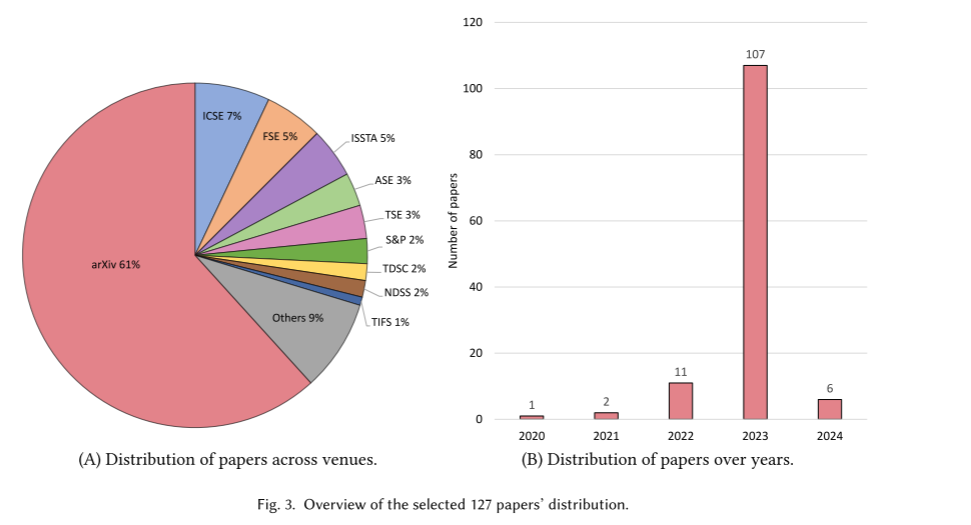
步骤 1: 确定相干会议和数据库。
在这个阶段,我们选择了
六项顶级网络安全会议和期刊
(即 S&
、NDSS、USENIX Security、CCS、TDSC 和 TIFS),以及
六项顶级软件工程会议和期刊
(即 ICSE、ESEC/FSE、ISSTA、ASE、TOSEM 和 TSE)。
鉴于LLMs在研究中的新兴性质,我们还在手动和自动搜索中包括了 arXiv,以便捕捉这个快速发展的范畴中最新的未发表研究。
对于自动搜索,我们选择了七个广泛使用的数据库,即 ACM 数字图书馆、IEEE Xplore、Science Direct、Web of Science、Springer、Wiley 和 arXiv。这些数据库提供了计算机科学文献的全面覆盖,并且在该范畴的系统评价中经常被使用。
步骤 2: 建立 QGS。
在这一步骤中,我们从细致筛选出的相干研究中创建了一份人工整理的研究集,以此形成 QGS。统共手动辨认出 41 篇与 LLM4Sec 相干的研究论文,这些研究论文与研究目标一致,并涵盖了各种技术、应用范畴和评估方法。
步骤 3: 界说搜索关键词。
自动搜索的关键词是从所选 QGS 论文的标题和摘要中通过词频分析得出的。搜索字符串由两组关键词组成:
关键词相干:LLM大型语言模型, LLM, 语言模型, LM, 预训练, CodeX, Llama, GPT-*, ChatGPT, T5, AIGC, AGI。
与安全使命相干的关键词:网络安全、网页安全、网络通信安全、系统安全、软件安全、数据安全、程序分析、程序修复、软件漏洞、CVE、CWE、漏洞检测、漏洞定位、漏洞分类、漏洞修复、软件错误、错误检测、错误定位、错误分类、错误报告、错误修复、安全运营、隐私泄露、服务拒绝、数据污染、后门、恶意软件检测、恶意软件分析、勒索软件、恶意命令、模糊测试、渗透测试、钓鱼、敲诈、诈骗、取证、入侵检测。
步骤 4: 进行自动化搜索。
找到的关键词逐一配对,并输入到上述七个广泛使用的数据库中进行自动化搜索。我们的自动化搜索集中在 2019 年及之后发表的论文,由于 GPT-2 的发布标志着大型语言模型发展中的一个紧张里程碑。搜索在每篇论文的标题、摘要和关键词字段中进行。详细来说,应用搜索查询和年份过滤(2019-2023)后,从每个数据库中检索到的论文数量如下:ACM 数字图书馆 3,398 篇,IEEE Xplore 2,112 篇,Science Direct 724 篇,Web of Science 4,245 篇,Springer 23,721 篇,Wiley 7,154 篇,arXiv 3,557 篇。
2.3 文献筛选标准
终极,这篇综述筛选并分析了 127 篇符合标准的论文。
3. LLMs 在网络安全范畴的应用
本节将详细介绍 LLMs 在网络安全范畴重要方向的详细应用。
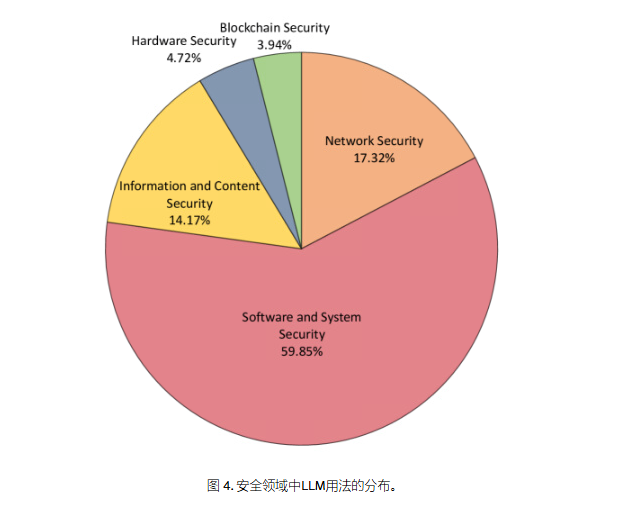
3.1 软件和系统安全 (Software and System Security)
软件和系统安全是 LLMs 应用最广泛的范畴,涵盖了从漏洞检测到恶意软件分析的各种使命。
漏洞检测与修复 (Vulnerability Detection and Repair):
原理:
LLMs 可以大概学习代码的语义和语法特征,辨认潜在的漏洞模式。通过在大量的漏洞代码和修复代码对上进行训练,LLMs 可以自动生成漏洞检测器和修复补丁。
模型:
CodeBERT, GraphCodeBERT, RoBERTa, CodeT5, GPT 系列等。
技术:
微调:
在特定类型的漏洞数据集上对 LLMs 进行微调,进步其检测和修复特定类型漏洞的能力。
提示工程:
计划合适的提示,引导 LLMs 生成漏洞检测报告或修复代码。
外部增强:
结合静态分析工具、符号执行等技术,进步 LLMs 的漏洞检测和修复能力。
案例:
LATTE:
将 LLMs 与程序分析技术相结合,实现自动化的二进制污点分析,发现了 37 个真实固件中的新漏洞。
VulRepair:
利用 T5 模型生成漏洞修复代码,并在多个基准数据集上取得了优异的性能。
ZeroLeak:
利用 LLMs 修复程序中的侧信道漏洞。
CVEDrill:
生成针对潜在网络安全威胁的优先级建议报告并预测其影响。
Bug 检测与修复 (Bug Detection and Repair):
原理:
与漏洞检测和修复类似,LLMs 可以大概学习代码中的错误模式,并自动生成修复代码。
模型:
CodeBERT, CodeT5, Codex, LLaMa, CodeLLaMa, CodeGEN, UniXcoder, T5, PLBART, GPT 系列等。
技术:
对比学习:
通过比较正确代码和错误代码之间的差异,进步 LLMs 的 bug 检测能力。
静态分析反馈:
将静态分析工具的反馈结果作为 LLMs 的输入,进步 bug 定位的准确性。
交互式反馈循环:
将 LLMs 与人工反馈相结合,进步 bug 修复的准确性。
案例:
RepresentThemAll:
提出了一种与软件无关的代码体现方法,基于对比学习和微调模块,实用于包括 bug 检测在内的各种下游使命。
Repilot:
一个基于 encoder-decoder 架构的框架,专门用于生成修复补丁。
ChatGPT:
通过与交互式反馈循环集成,明显进步了程序修复的准确性。
程序模糊测试 (Program Fuzzing):
原理:
LLMs 可以大概生成多样化的测试用例,覆盖更多的代码路径,从而发现更多的漏洞和错误。
模型:
GPT 系列等。
技术:
重复查询、示例查询和迭代查询:
通过差别的查询策略,引导 LLMs 生成更有效的测试用例。
从历史 bug 报告中学习:
利用历史 bug 报告中的信息,生成更有可能触发漏洞的测试用例。
案例:
GPTFuzzer:
基于 encoder-decoder 架构,生成针对 SQL 注入、XSS 和 RCE 攻击的有效负载。
CHATAFL:
利用 LLMs 生成布局化和有效的测试输入,用于缺乏机器可读版本的网络协议。
逆向工程和二进制分析 (Reverse Engineering and Binary Analysis):
原理:
LLMs 可以大概理解二进制代码的功能和举动,辅助逆向工程师进行代码分析。
模型:
CodeBERT, GraphCodeBERT, RoBERTa, CodeT5, GPT 系列等。
技术:
变量名规复:
利用 LLMs 规复二进制文件中的变量名。
反汇编:
将类型推断引擎与 LLMs 相结合,执行可执行文件的反汇编并生成程序源代码。
代码摘要:
生成二进制代码的功能摘要。
案例:
DexBert:
用于表征 Android 系统二进制字节码。
SYMC:
基于群论,保留了代码的语义对称性,在各种二进制分析使命中体现出出色的泛化性和鲁棒性。
恶意软件检测 (Malware Detection):
原理:
LLMs 可以大概学习恶意软件的语义特征,区分恶意软件和良性软件。
模型:
CodeBERT, RoBERTa, GPT 系列等。
技术:
特征提取:
利用 LLMs 提取恶意软件的语义特征。
多模态学习:
将 LLMs 与其他模态的信息(如图像、举动特征等)相结合,进步检测准确率。
案例:
AVScan2Vec:
将杀毒软件扫描报告转换为向量体现,用于恶意软件分类、聚类和近来邻搜索等使命。
系统日记分析 (System Log Analysis):
原理:
LLMs 可以大概理解系统日记中的文本信息,辨认异常举动和安全变乱。
模型:
GPT 系列等。
技术:
异常检测:
利用 LLMs 辨认与正常日记模式差别的异常日记条目。
根本原因分析:
利用 LLMs 分析日记信息,推断变乱发生的根本原因。
案例:
LLMs 被用于云服务器的日记分析,结合服务器日记来推断云服务变乱的根本原因。
3.2 网络安全 (Network Security)
LLMs 在网络安全范畴的应用重要集中在流量分析、入侵检测、威胁谍报等方面。
Web 模糊测试 (Web Fuzzing):
原理:
LLMs 可以大概生成针对 Web 应用程序的各种测试用例,如 SQL 注入、跨站脚本(XSS)、远程代码执行(RCE)等。
模型:
GPT 系列等。
技术:
强化学习:
利用强化学习算法对 LLMs 进行微调,使其可以大概生成更有效的攻击负载。
案例:
与软件和系统安全部分提到的 GPTFuzzer 和 CHATAFL 类似,这些模型也可以应用于 Web 模糊测试。
流量和入侵检测 (Traffic and Intrusion Detection):
原理:
LLMs 可以大概学习网络流量的特征,辨认恶意流量和入侵举动。
模型:
BERT 及其变体、GPT 系列等。
技术:
特征提取:
利用 LLMs 提取网络流量的特征。
多模态学习:
将 LLMs 与其他模态的信息(如流量统计信息、协议特征等)相结合,进步检测准确率。
意图形貌:
LLMs 不但可以检测异常,还能形貌入侵和异常举动的意图。
案例:
研究表明,LLMs 可以学习恶意流量数据的特征,并捕获用户举动中的异常。
LLMs 可以为已辨认的攻击类型提供相应的安全建议和响应策略。
有方法利用 LLMs 提取恶意 URL 的分层特征,将 LLMs 的应用扩展到用户级别。
网络威胁分析 (Cyber Threat Analysis):
原理:
LLMs 可以大概处理大量的网络安全文本信息(如威胁谍报报告、安全博客、消息等),从中提取关键信息,辅助安全分析师进行威胁评估和响应。
模型:
GPT系列、BERT及其变种
技术:
CTI 生成:
从网络安全文本信息(如书籍、博客、消息)中提取 CTI。
从非布局化信息生成布局化 CTI 报告。
从网络安全实体图中生成 CTI。
CTI 分析:
为潜在的网络安全威胁生成优先级建议报告。
预测网络安全威胁的影响。
案例:
CVEDrill:
可以生成针对潜在网络安全威胁的优先级建议报告,并预测其影响。
研究探索了 ChatGPT 在协助或自动化威胁举动响应决议方面的应用。
渗透测试 (Penetration Test):
原理:
LLMs 可以大概模仿攻击者的举动,自动执行渗透测试的各个步骤,如信息网络、漏洞扫描、漏洞利用等。
模型:
GPT 系列等。
技术:
信息网络:
利用 LLMs 网络目标系统的信息,如 IP 所在、域名、供应商技术、SSL/TLS 凭证等。
有效负载生成:
利用 LLMs 生成恶意有效负载,用于漏洞利用。
自动化测试:
将 LLMs 与自动化测试工具相结合,实现自动化渗透测试。
案例:
PentestGPT****:
一种基于 LLMs 的自动化渗透测试工具,在包含 13 个场景和 182 个子使命的渗透测试基准测试中取得了优异的性能。
3.3 信息和内容安全 (Information and Content Security)
LLMs 在信息和内容安全范畴的应用重要集中在虚假信息检测、有害内容辨认等方面。
网络钓鱼和诈骗检测 (Phishing and Scam Detection):
原理:
LLMs 可以大概辨认网络钓鱼邮件和诈骗信息中的欺骗性语言模式和语义特征。
模型:
GPT 系列、BERT 及其变体等。
技术:
提示工程:
计划合适的提示,引导 LLMs 检测网络钓鱼邮件。
微调:
在特定类型的网络钓鱼邮件数据集上对 LLMs 进行微调,进步其检测能力。
案例:
研究表明,LLMs 在垃圾邮件检测方面体现出比传统机器学习方法更明显的优势。
有研究表明,LLMs 可以模仿真实的人类与诈骗者互动,从而浪费诈骗者的时间和资源,减轻诈骗邮件的滋扰。
有害内容检测 (Harmful Contents Detection):
原理:
LLMs 可以大概辨认交际媒体上的有害内容,如仇恨言论、极度主义言论、网络暴力等。
模型:
GPT 系列、BERT 及其变体等。
技术:
多标签分类:
利用 LLMs 对有害内容进行多标签分类,辨认差别类型的有害内容。
上下文理解:
利用 LLMs 理解上下文信息,进步有害内容检测的准确性。
案例:
LLMs 用于检测极度政治立场、跟踪犯罪活动言论和辨认交际媒体机器人。
隐写术 (Steganography):
原理:
LLMs可以大概辅助生整天然语言载体文本,用于隐蔽加密信息
模型:
GPT系列
技术:
基于少量样本学习的语言隐写分析方法,利用少量标志样本和辅助未标志样本进步语言隐写分析的效率。
将密文编码为天然语言覆盖文本,允许用户控制公共平台上用于机密信息传输的密文的可观察格式。
案例:
研究职员利用 LLMs 生成与正常文本难以区分的隐写文本,进步了隐写术的潜伏性。
访问控制 (Access Control):
原理:
密码是访问控制的基础,LLMs可以辅助生成更强健的密码。
模型:
GPT系列
技术:
通过引导密码生成,根据用户界说的约束来生成密码。
案例:
PassGPT,一个利用LLMs的密码生成模型,引入了引导密码生成,其中PassGPT的采样过程生成的密码符合用户界说的约束。
取证 (Forensics):
原理:
LLMs可以大概对电子设备中的信息进行分析,辅助数字取证调查
模型:
GPT系列
技术:
文件辨认、证据检索和变乱响应。
案例:
研究探索了LLM在各种数字取证场景中的性能评估,包括文件辨认、证据检索和变乱响应
3.4 硬件安全 (Hardware Security)
LLMs 在硬件安全范畴的应用相对较少,重要集中在硬件漏洞检测和修复方面。
硬件漏洞检测 (Hardware Vulnerability Detection):
原理:
LLMs 可以大概分析硬件形貌语言(HDL)代码,辨认潜在的硬件漏洞。
模型:
BERT 及其变体、GPT 系列等。
技术:
代码分析:
利用 LLMs 分析 HDL 代码,辨认常见的硬件漏洞模式。
安全属性提取:
从硬件开发文档中提取安全属性。
案例:
HS-BERT****:
在 RISC-V、OpenRISC 和 MIPS 等硬件架构文档上进行训练,辨认了 OpenTitan SoC 计划中的 8 个安全漏洞。
硬件漏洞修复 (Hardware Vulnerability Repair):
原理:
LLMs 可以大概生成 HDL 代码补丁,修复硬件漏洞。
模型:
GPT 系列等。
技术:
代码生成:
利用 LLMs 生成 HDL 代码补丁。
漏洞信息利用:
利用硬件漏洞信息,引导 LLMs 生成更有效的修复代码。
案例:
研究表明,LLMs 可以在硬件代码生成过程中生成硬件级安全漏洞。
3.5 区块链安全 (Blockchain Security)
LLMs 在区块链安全范畴的应用也相对较少,重要集中在智能合约安全和交易异常检测方面。
智能合约安全 (Smart Contract Security):
原理:
LLMs 可以大概分析智能合约代码,辨认潜在的漏洞。
模型:
GPT 系列等。
技术:
漏洞检测:
利用 LLMs 检测智能合约中的常见漏洞,如重入攻击、整数溢出等。
代码生成:
利用 LLMs 生成更安全的智能合约代码。
案例:
GPTLENS:
将智能合约漏洞检测过程分为两个阶段:生成和辨别,以减轻误报。
交易异常检测 (Transaction Anomaly Detection):
原理:
LLMs 可以大概学习区块链交易的模式,辨认异常交易举动。
模型:
GPT 系列等。
技术:
序列分析:
利用 LLMs 分析交易序列,辨认异常交易模式。
图分析:
将 LLMs 与图神经网络相结合,分析交易网络中的异常关系。
案例:
研究职员利用 LLMs 实时、动态地检测区块链交易中的异常情况。
4. LLM类型被用于支持网络安全使命
本节将深入分析差别 LLMs 架构的特点和实用场景,并探究它们在网络安全使命中的应用情况。
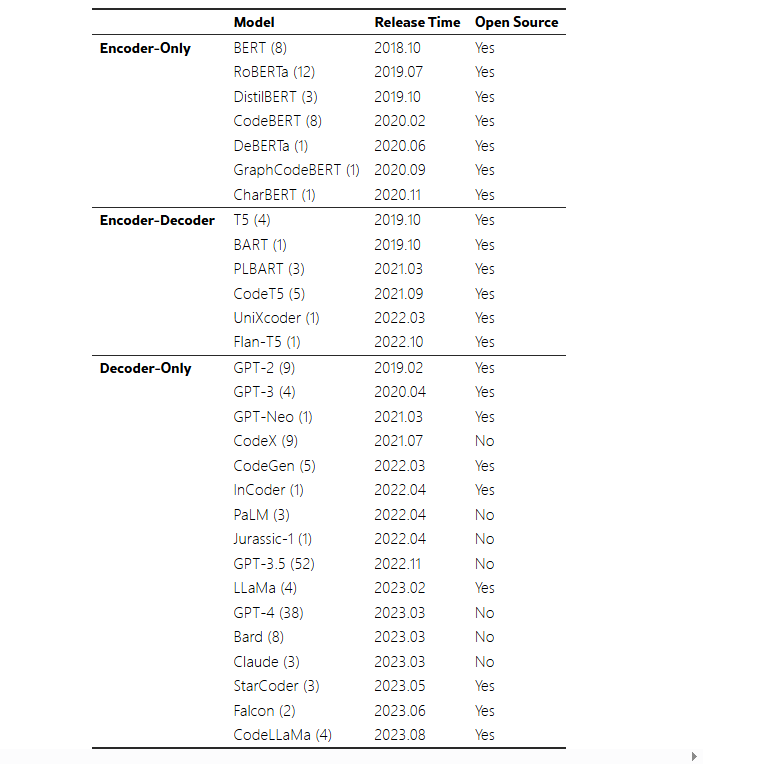
4.1 Encoder-only LLMs
架构特点:
只包含编码器(encoder)网络,善于理解和编码输入信息。
采用双向多层自注意力机制,可以大概捕捉全局上下文的语义特征。
通常用于文天职类、定名实体辨认等使命。
代表模型:
BERT (Bidirectional Encoder Representations from Transformers):
Google 提出的预训练语言模型,是 encoder-only LLMs 的代表。
CodeBERT:
针对代码数据的 BERT 变体,用于代码理解和生成。
GraphCodeBERT:
将代码的抽象语法树(AST)信息融入到 CodeBERT 中,进一步进步了代码理解能力。
RoBERTa (Robustly Optimized BERT Pretraining Approach):
对 BERT 的训练方法进行了优化,进步了模型的鲁棒性。
CharBERT:
字符级别的 BERT 模型。
DeBERTa:
使用解耦注意力机制的 BERT 模型。
DistilBERT:
通过知识蒸馏技术得到的轻量级 BERT 模型。
在网络安全中的应用:
重要用于需要理解输入信息的使命,如漏洞检测、恶意软件分析、流量分析等。
CodeBERT 及其变体在代码相干的安全使命中体现出色。
4.2 Encoder-decoder LLMs
架构特点:
包含编码器和解码器两部分,编码器负责将输入序列编码为潜在体现,解码器负责根据这些体现生成目标序列。
实用于序列到序列的使命,如机器翻译、文本摘要、代码生成等。
代表模型:
T5 (Text-to-Text Transfer Transformer):
Google 提出的预训练语言模型,将全部 NLP 使命都转换为文本到文本的格式。
BART (Bidirectional and Auto-Regressive Transformers):
结合了 BERT 和 GPT 的特点,既能进行双向编码,又能进行自回归生成。
PLBART:
针对编程语言和天然语言的预训练模型。
CodeT5:
针对代码数据的 T5 模型,用于代码生成、代码摘要等使命。
UniXcoder:
同一的跨模态预训练模型,可以处理多种编程语言和天然语言。
Flan-T5
谷歌提出的指令微调模型
在网络安全中的应用:
实用于需要生成文本或代码的使命,如漏洞修复、代码生成、钓鱼邮件检测等。
CodeT5 及其变体在代码相干的安全使命中体现出色。
4.3 Decoder-only LLMs
架构特点:
只包含解码器网络,通过预测后续 token 来生成文本。
擅永生成长文本,实用于需要详细分析、建议甚至代码生成的安全使命。
代表模型:
GPT 系列 (Generative Pre-trained Transformer):
OpenAI 提出的预训练语言模型,是 decoder-only LLMs 的代表。
GPT-2:
GPT 系列的第二个版本,具有更强的文本生成能力。
GPT-3:
GPT 系列的第三个版本,参数量达到了 1750 亿,是目前最大的 LLMs 之一。
GPT-3.5:
GPT-3 的改进版本,具有更强的对话能力。
GPT-4:
GPT 系列的最新版本,具有更强的多模态能力。
CodeX:
OpenAI 提出的针对代码生成的 LLMs。
CodeGen:
Salesforce 提出的针对代码生成的 LLMs。
InCoder:
Meta AI 提出的针对代码生成的 LLMs。
PaLM (Pathways Language Model):
Google 提出的预训练语言模型。
Jurassic-1:
AI21 Labs 提出的预训练语言模型。
LLaMa (Large Language Model Meta AI):
Meta AI 提出的开源 LLMs。
Bard:
Google 提出的对话式 AI 模型。
Claude:
Anthropic 提出的对话式 AI 模型。
StarCoder:
BigCode 项目提出的针对代码生成的开源 LLMs。
Falcon:
TII 提出的开源LLMs
CodeLLaMa:
Meta AI 提出的开源 LLMs, 针对代码数据微调
在网络安全中的应用:
险些涵盖全部网络安全应用,特殊是需要生成文本或代码的使命。
GPT-3.5 和 GPT-4 在网络安全研究中应用最为广泛。
4.4 趋势分析 (Trend Analysis)
时间线与趋势演变
2020-2021
应用情况
:
LLM 在网络安全范畴的应用有限,仅有 3 篇研究论文探究其潜力。
模型架构
:
2020
: 以编码器-解码器架构为主,因其在序列使命中的优异体现被研究。
2021
: 转向仅解码器架构,夸大其自回归生成能力和处理长文本查询的优势。
驱动因素
: LLM 在天然语言处理使命中的性能提升,以及架构创新(Kaplan 等人,2020;布朗等人,2020)。
2022
应用情况
:
相干研究激增至 11 篇论文,超过之前两年的总和。
模型架构多样化
:
编码器模型: 46%(5 篇论文)。
编码器-解码器模型: 18%(2 篇论文)。
仅解码器模型: 36%(4 篇论文)。
研究重点
: 差别架构用于满意网络安全范畴中表征学习、分类和生成等使命需求。
2023-2024
应用情况
:
仅解码器模型成为主导架构。
2023
: 占总研究的 68.9%。
2024
: 全部研究都采用仅解码器模型。
优势
: 强大的文本理解、推理能力、少样本学习能力以及实用于复杂、开放式使命的特性。
挑衅
: 仅解码器模型参数规模较大,对计算资源要求较高。
架构使用趋势与社区偏好
网络安全中的主流架构
:
仅解码器模型占主导地位,符合 LLM 社区的主流趋势。
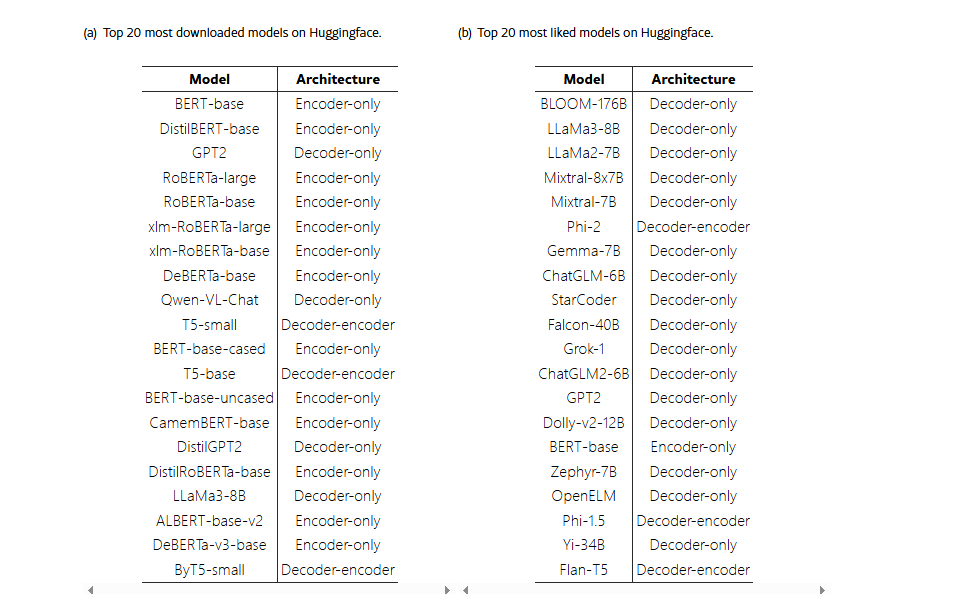
社区数据(Huggingface)
:
固然编码器模型(如 BERT)的下载量较高,但仅解码器模型也备受关注。
最受接待的 20 个模型中有 16 个为仅解码器架构。
偏好原因
: 生成能力、知识处理以及复杂使命顺应性使其更得当网络安全挑衅。
挑衅
: 参数规模较大,对计算资源需求高,影响部分应用场景
应用模式
基于代理的处理
方法
:
使用闭源 LLM(如 GPT 系列),通过调用模型发布者的 API 在线完成使命特定的处理。
典范应用
: 漏洞修复、渗透测试等实际使命。
研究示例
: Jiang 等人(2020);Dong 等人(2023);Madaan 等人(2023)。
针对特定使命的微调
方法
:
使用开源 LLM,针对定制数据集进行当地微调以提升特定使命性能。
研究示例
: Silva 等人(2024);杨等人(2023)。
5.使 LLM 顺应安全使命的范畴规范技术
本节将详细介绍 LLMs 应用于安全使命时所采用的范畴特定技术,包括微调、提示工程和外部增强。
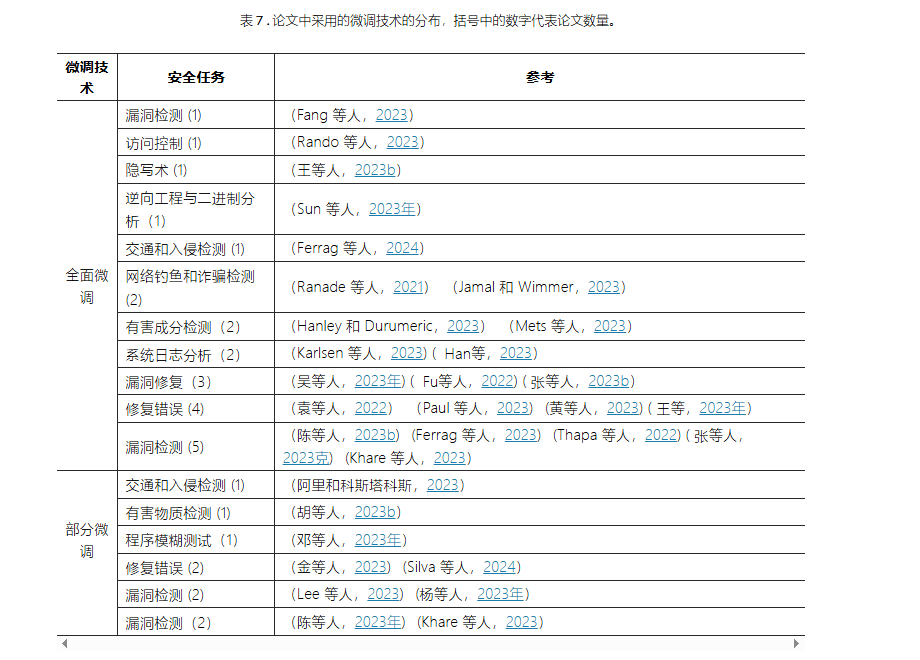
5.1 微调 (Fine-tuning)
微调是 LLMs 应用于下游使命的常用技术,通过在特定使命的标注数据上对 LLMs 进行训练,使其顺应特定使命的需求。
全参数微调 (Full Fine-tuning):
调整 LLMs 的全部参数,使其顺应目标使命。这种方法通常需要大量的计算资源和时间,但可以获得最佳的性能。
部分微调 (Partial Fine-tuning):
只调整 LLMs 的部分参数,如顶层或少数几层,以减少计算成本和训练时间。常用的部分微调技术包括:
API Fine-tuning:
通过调用云服务商提供的 API 进行模型微调。
Adapter-tuning:
在 LLMs 的每一层中插入小的适配器模块,只训练这些适配器模块的参数。
Prompt-tuning:
在输入序列中添加可学习的软提示(soft prompt),只训练这些软提示的参数。
LoRA (Low-Rank Adaptation):
通过低秩分解来近似参数更新,减少需要训练的参数量。
5.2 提示工程 (Prompt Engineering)
提示工程是通过计划合适的提示(prompt)来引导 LLMs 生成特定类型的输出。提示工程是 LLMs 应用于安全使命的关键技术,特殊是对于数据特征有限的安全使命。
提示计划:
提示计划需要考虑使命的目标、输入数据的特点、LLMs 的能力等因素。
提示示例:
漏洞检测:
“请检查以下代码是否存在 SQL 注入漏洞:[代码片段]”
恶意软件分析:
“请分析以下恶意软件样本的功能和举动:[恶意软件样本]”
威胁谍报提取:
“请从以下安全报告中提取关键信息:[安全报告]”
提示技巧:
零样本学习 (Zero-shot learning):
直接使用预训练的 LLMs,不进行任何微调。
少样本学习 (Few-shot learning):
提供少量示例作为提示,引导 LLMs 生成类似的结果。
思维链 (Chain-of-thought):
将复杂的使命分解为多个步骤,引导 LLMs 逐步推理。
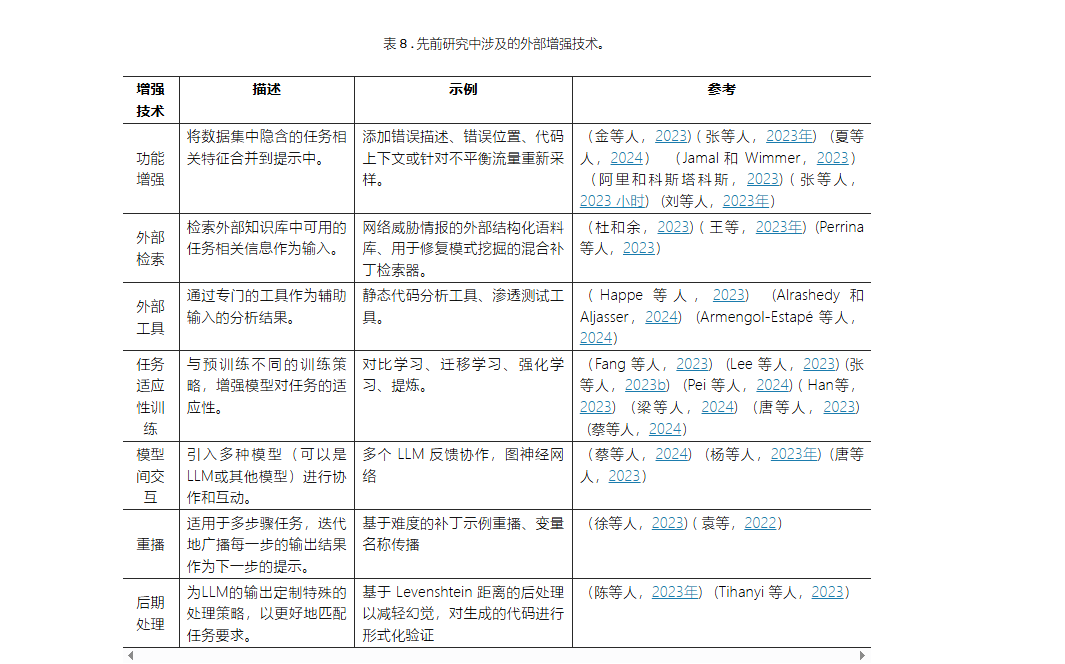
5.3 外部增强 (External Augmentation)
外部增强是通过结合外部知识、工具或模型来增强 LLMs 的能力。
特征增强 (Feature Augmentation):
将从原始数据中提取的上下文关系或其他隐含特征与原始数据一起整合到提示中,比方:漏洞形貌、bug位置、威胁流程图等。
外部检索 (External Retrieval):
从外部知识库(如安全文档、漏洞数据库等)中检索与使命相干的信息,作为 LLMs 的输入。
比方:网络威胁谍报的外部布局化语料库、用于修复模式发掘的混合补丁检索器。
外部工具 (External Tools):
利用专门工具(如静态分析工具、符号执行工具、渗透测试工具等)的分析结果作为 LLMs 的辅助输入。
比方: 静态代码分析工具、渗透测试工具。
使命自顺应训练 (Task-adaptive Training):
采用差别的训练策略(如对比学习、迁移学习、强化学习、蒸馏等)来增强模型对使命的顺应性。
比方: 对比学习、迁移学习、强化学习、蒸馏。
模型间交互 (Inter-model Interaction):
引入多个模型(可以是 LLMs 或其他模型)进行协作和交互,共同完成使命。
比方: 多个LLM反馈协作、图神经网络。
重播 (Rebroadcasting):
实用于多步使命,将每个步骤的输出结果作为下一步的提示的一部分,进行迭代。
比方:基于难度的补丁示例重播、变量名称传播。
后处理 (Post-process):
对 LLMs 的输出进行定制化处理,以满意特定使命的需求,如格式转换、错误校正、结果过滤等。
比方:基于Levenshtein距离的后处理以减轻幻觉、对生成的代码进行形式验证。
6. LLM 应用于安全使命时,数据网络和预处理有何差别
本节将探究 LLMs 应用于安全使命时的数据网络和预处理方法。
6.1 数据网络 (Data Collection)
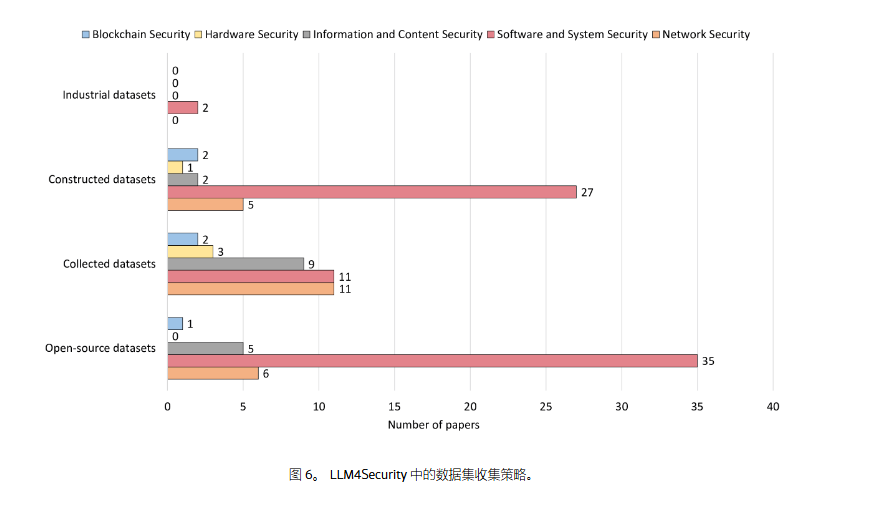
数据在 LLM 训练中起着不可或缺的关键作用,影响模型的泛化能力、有效性和性能 。充足、优质、多样化的数据对于模型全面理解使命特征和模式、优化参数、保证验证和测试的可靠性至关紧张。起首,我们探究了数据集的获取技术。通过对数据网络方法的考察,我们将数据源分为四类:开源数据集、网络的数据集、构建的数据集和工业数据集。
开源数据集 (Open-source Datasets):
特点:
公开可用,易于获取,通常具有较高的质量和可靠性。
泉源:
安全社区:如 OWASP、SANS Institute 等。
学术研究:如 NIST National Vulnerability Database (NVD)、MITRE CVE 等。
开源项目:如 GitHub、GitLab 等。
+ **案例:**
- **UNSW-NB15:** 包含网络连接记录,用于入侵检测研究。
- **CVE (Common Vulnerabilities and Exposures):** 包含已知漏洞的信息。
- **CWE (Common Weakness Enumeration):** 包含常见软件和硬件弱点的列表。
复制代码
网络的数据集 (Collected Datasets):
特点:
针对特定研究问题,从各种泉源网络的数据,可能需要进行洗濯和标注。
泉源:
网站、论坛、博客、交际媒体等。
安全厂商、安全服务提供商等。
案例:
从 GitHub 网络的代码解释。
从交际媒体网络的有害内容。
从 CVE 网站网络的漏洞信息。
构建的数据集 (Constructed Datasets):
特点:
通过修改或增强现有数据集,或重新开始创建的数据集,以满意特定研究需求。
方法:
手动标注、半自动标注、数据增强等。
案例:
创建针对特定范畴漏洞的测试集。
对现有数据集进行标注或修改。
生成合成数据。
工业数据集 (Industrial Datasets):
特点:
来自真实商业或工业情况的数据,通常包含敏感信息,难以公开获取。
泉源:
企业、构造、政府机构等。
案例:
工业应用程序、用户举动日记等。
6.2 数据类型 (Data Types)
LLMs 在网络安全范畴使用的数据类型重要包括:
基于代码的数据 (Code-based Data):
漏洞代码 (Vulnerable code):
包含已知漏洞的代码片段。
源代码 (Source code):
程序的完备源代码。
Bug 修复对 (Bug-fix pairs):
包含错误代码和修复后代码的配对数据。
Bug:
软件程序中存在的缺陷
流量数据包(Traffic packages):
网络传输的数据包
补丁(Patches):
用于修复漏洞或错误的代码补丁。
代码变动(Code Changes):
对源代码进行的修改
漏洞修复对(Vulnerability-fix pairs):
包含漏洞代码和修复后代码的配对数据。
修复提交信息(Bug fixing commits):
版本控制系统中,包含错误修复信息的提交纪录
Web攻击载荷(Web attack payloads):
用于进行Web攻击的恶意代码或数据
主题协议程序(Subject protocol programs):
形貌特定安全协议的程序
漏洞程序(Vulnerable programs):
包含已知漏洞的程序
基于文本的数据 (Text-based Data):
提示 (Prompts):
用于引导 LLMs 生成特定输出的文本。
日记消息 (Log messages):
系统或应用程序生成的日记信息。
交际媒体内容 (Social media contents):
来自交际媒体平台的文本、图像、视频等。
垃圾邮件(Spam messages):
不需要的或恶意的电子邮件
Bug报告(Bug reports):
形貌软件缺陷的报告
攻击形貌(Attack descriptions):
对网络攻击的形貌
CVE报告(CVE reports):
对已知漏洞的形貌
网络威胁谍报数据(Cyber threat intelligence data):
关于网络威胁的信息
顶级域名(Top-level domains):
顶级域名列表
安全报告(Security reports):
对安全变乱或漏洞的报告
威胁报告(Threat reports):
对特定威胁的报告
布局化威胁信息(Structured threat information):
以布局化格式体现的威胁信息
程序文档(Program documentations):
程序的文档
杀毒软件扫描报告(Antivirus scan reports):
杀毒软件的扫描结果
密码(Passwords):
用户密码
硬件文档(Hardware documentations):
硬件设备的文档
组合数据集 (Combined Datasets):
同时包含代码和文本数据,如漏洞代码及其对应的天然语言形貌。
漏洞代码和漏洞形貌(Vulnerable code and vulnerability descriptions)
研究表明,大多数研究依赖于基于代码的数据集,这凸显了 LLMs 在代码分析方面的优势。然而,文本数据在网络安全范畴也扮演着紧张的脚色,如安全报告、威胁谍报、日记分析等。
6.3 数据预处理 (Data Pre-processing)
数据预处理是 LLMs 应用于安全使命的关键步骤,其目标是将原始数据转换为得当 LLMs 处理的格式,并进步数据的质量。
代码数据预处理:
数据提取 (Data Extraction):
从代码库、漏洞数据库、bug 跟踪系统等泉源提取与安全使命相干的代码片段。提取粒度可以是 token 级别、语句级别、类级别或流量级别。
重复实例删除 (Duplicated Instance Deletion):
删除重复的代码片段,避免数据冗余,进步训练效率。
不合格数据删除 (Unqualified Data Deletion):
删除不符合质量标准的代码片段,如语法错误、不完备的代码等。
代码体现 (Code Representation):
将代码片段转换为 LLMs 可以大概处理的格式,通常是将代码转换为 token 序列。
数据分割 (Data Segmentation):
将数据集分别为训练集、验证集和测试集,用于模型的训练、调优和评估。
文本数据预处理:
数据提取 (Data Extraction):
从安全报告、威胁谍报、日记文件、交际媒体等泉源提取与安全使命相干的文本。
初始数据分割 (Initial Data Segmentation):
将文天职割为句子、单词或短语。
不合格数据删除 (Unqualified Data Deletion):
删除无效的文本数据,如特殊符号、停用词、低频词等。
文本体现 (Text Representation):
将文本转换为 LLMs 可以大概处理的格式,通常是将文本转换为 token 序列。
数据分割 (Data Segmentation):
将数据集分别为训练集、验证集和测试集,用于模型的训练、调优和评估。
数据预处理的详细步骤和方法取决于数据类型、安全使命和 LLMs 的特点。
7. 挑衅与机遇
只管 LLMs 在网络安全范畴取得了明显进展,但仍面临着一些挑衅,同时也存在着巨大的发展机遇。
7.1 挑衅
LLM 实用性挑衅
模型大小和部署 (Model Size and Deployment):
LLMs 的巨大参数量对计算资源和存储空间提出了很高的要求,限制了其在资源受限情况中的部署。
数据稀缺性 (Data Scarcity):
许多特定的安全使命缺乏高质量、大规模的公开数据集,限制了 LLMs 的训练和性能。
数据污染 (Data Contamination):
训练数据可能包含错误、私见或过时信息,导致 LLMs 产生禁绝确或误导性的结果。
LLM 泛化能力挑衅
范畴顺应性 (Domain Adaptation):
LLMs 在通用范畴预训练的知识可能无法直策应用于特定的安全范畴,需要进行范畴顺应。
使命特异性 (Task Specificity):
LLMs 需要针对特定的安全使命进行微调或调整,才能获得最佳性能。
对抗样本 (Adversarial Examples):
LLMs 容易受到对抗样本的攻击,攻击者可以通过经心计划的输入来欺骗 LLMs。
**LLM 可表明性、可信度和伦理使用挑衅 **
可表明性 (Interpretability):
LLMs 的“黑盒”特性使得难以理解其决议过程,限制了其在安全范畴的可信度。
可信度 (Trustworthiness):
LLMs 可能会生成虚假信息、泄露隐私或产生私见,需要采取措施来确保其可靠性和安全性。
伦理使用 (Ethical Usage):
LLMs 的滥用可能会导致严重的社会问题,如虚假信息传播、隐私陵犯、歧视等。
7.2 机遇
改进 LLM4Security:
安全使命的模型训练 :
开发更得当安全使命的 LLMs 架构和训练方法,如:
计划新的丧失函数,使其更符合安全使命的目标。
采用更有效的预训练策略,进步 LLMs 在安全范畴的知识水平。
开发更轻量级的 LLMs,降低其部署难度。
LLMs 的模型间交互 (Inter-model Interaction of LLMs):
探索多个 LLMs 或 LLMs 与其他模型(如传统的机器学习模型、符号执行工具等)的协作,进步复杂安全使命的处理能力。
ChatGPT 的影响和应用 (Impact and Applications of ChatGPT):
进一步研究 ChatGPT 等谈天机器人在网络安全范畴的应用,如:
自动化安全咨询和响应。
安全教育和培训。
威胁谍报分析和共享。
增强 LLM 在现有安全使命中的性能:
LLM 的外部检索和工具 (External Retrieval and Tools for LLM):
利用外部知识库和工具来增强 LLMs 的能力,减少幻觉和错误,进步其准确性和可靠性。比方:
将 LLMs 与漏洞数据库、威胁谍报平台等连接,使其可以大概获取最新的安全信息。
将 LLMs 与静态分析工具、动态分析工具等结合,进步其漏洞检测和分析能力。
范畴知识注入:
将安全范畴的专业知识融入到 LLMs 中,进步其在安全使命上的体现。
扩展 LLM 在更多安全范畴的能力:
整合新的输入格式 (Integrating New Input Formats):
除了文本和代码,还可以将 LLMs 与其他模态的数据(如图像、音频、视频等)相结合,实现多模态安全分析。
扩展 LLM 应用 (Expanding LLM Applications):
将 LLMs 应用于更多网络安全范畴,如物联网安全、工控系统安全、云安全等。
办理特定范畴的挑衅 (Addressing Challenges in Specific Domains):
针对特定范畴的特点,开发专门的数据集和技术方法,进步 LLMs 在这些范畴的应用效果。
7.3 研究门路
网络安全办理方案自动化(自动化)
目标
:
实现特定安全场景样本的自动分析、多场景安全态势感知、系统安全优化,以及为安全职员开发智能化和定制化的支持。
利用 LLM 生成能力
:
帮助安全职员快速理解需求并订定成本效益的安全办理方案,加快安全响应时间。
构建安全感知工具
:
利用 LLM 的天然语言处理能力实现与安全职员直观且灵敏的交互。
微调 LLM
:
定制自动化工作流程,进步对特定安全使命的精度与效率,满意差别项目与职员的需求。
将安全知识融入大型语言模型课程(RAG)
目标
:
降服模型幻觉和错误,将专门的安全办理方案和网络安全知识融入 LLM 中。
实用场景
:
渗透测试、硬件漏洞检测、日记分析
优势
:
嵌入安全范畴规则和最佳实践,增强模型生成强大且一致的安全使命办理方案能力。
关键方向
:
专注于范畴专业知识嵌入,尤其是需要大量范畴知识的安全使命。
安全代理:集成外部增强与 LLM(Agent)
现状与挑衅
:
LLM 在安全使命中潜力巨大,但缺乏范畴知识与幻觉限制了模型感知使命要求或情况的能力(Zhang et al., 2023)。
办理方案
:
使用 AI 安全代理感知情况、决议并采取办法,结合外部增强优化 LLM 性能
实现目标
:
安全运维职员可指定外部增强策略,与 LLM 集成,打造自动化与互动的安全 AI 代理。
用于安全的多模态大型语言模型 (多模态)
现状
:
当前 LLM4Security 依赖文本语言输入(如文本或代码)。
未来方向
:
引入视频、音频和图像等多模态输入和输出,增强对安全使命的理解与处理能力。
应用场景
:
渗透测试中使用的网络拓扑图或步骤截图作为输入;音频输入(如安全变乱灌音)提供背景信息。
优势
:
多模态数据可以提供更丰富的上下文,提升 LLM 在复杂安全使命中的体现。
大型语言模型的安全性 (Security4LLM)
现状与挑衅
:
LLM 的复杂性使其容易受到攻击,比方越狱和恶意提示注入
此类漏洞可能导致敏感数据暴露(如系统日记和漏洞代码)。
办理方向
:
使 LLM 自主检测和辨认其漏洞,生成底层代码补丁以强化安全性,而非仅在用户交互层实行限制。
平衡方法
:
同时关注两方面:利用 LLM 自动化和经济高效完成安全使命,以及开发掩护 LLM 自身的技术。
意义
:
这种双重关注对于增强网络安全和掩护模型自身敏感信息至关紧张。
8. 总结与预测
LLMs 的出现为网络安全范畴带来了革命性的变革,其强大的天然语言理解和生成能力为办理各种安全问题提供了新的思绪和工具。本报告基于一篇系统文献综述,全面、深入地解析了 LLMs 在网络安全范畴的应用现状、挑衅和机遇。
重要发现:
LLMs 已被广泛应用于软件和系统安全、网络安全、信息和内容安全等多个范畴,涵盖了漏洞检测、恶意软件分析、威胁谍报提取、安全代码生成等各种使命。
Decoder-only LLMs,特殊是 GPT 系列模型,在网络安全研究中占据主导地位。
微调、提示工程和外部增强是 LLMs 应用于安全使命的关键技术。
开源数据集是 LLMs 训练的重要数据泉源,但工业数据集的使用仍然有限。
LLMs 在代码分析方面体现出优势,但文本数据在网络安全范畴也扮演着紧张的脚色。
未来研究方向:
开发更得当安全使命的 LLMs 架构和训练方法。
探索多个 LLMs 或 LLMs 与其他模型的协作,进步复杂使命的处理能力。
利用外部知识库和工具增强 LLMs 的能力,减少幻觉和错误。
将 LLMs 应用于更多网络安全范畴,并办理特定范畴的挑衅。
研究 LLMs 的可表明性、可信度和伦理使用问题。
探索 Security4LLM,即 LLMs 本身的安全性问题。
总之,LLMs 在网络安全范畴具有巨大的潜力,但仍需要降服一系列挑衅。未来的研究应致力于进步 LLMs 的安全性、可靠性和可表明性,并将其应用于更广泛的网络安全场景,以构建更安全、更智能的网络空间。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4
 、NDSS、USENIX Security、CCS、TDSC 和 TIFS),以及六项顶级软件工程会议和期刊(即 ICSE、ESEC/FSE、ISSTA、ASE、TOSEM 和 TSE)。
、NDSS、USENIX Security、CCS、TDSC 和 TIFS),以及六项顶级软件工程会议和期刊(即 ICSE、ESEC/FSE、ISSTA、ASE、TOSEM 和 TSE)。