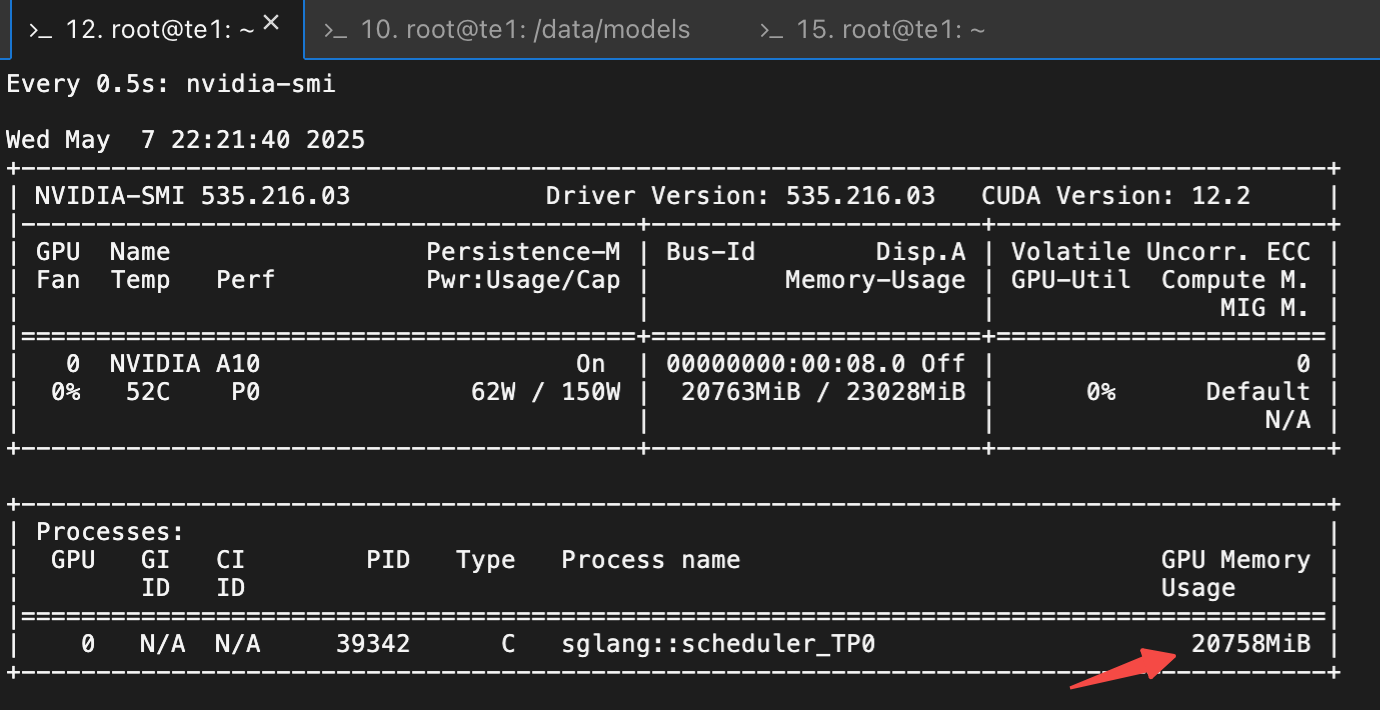
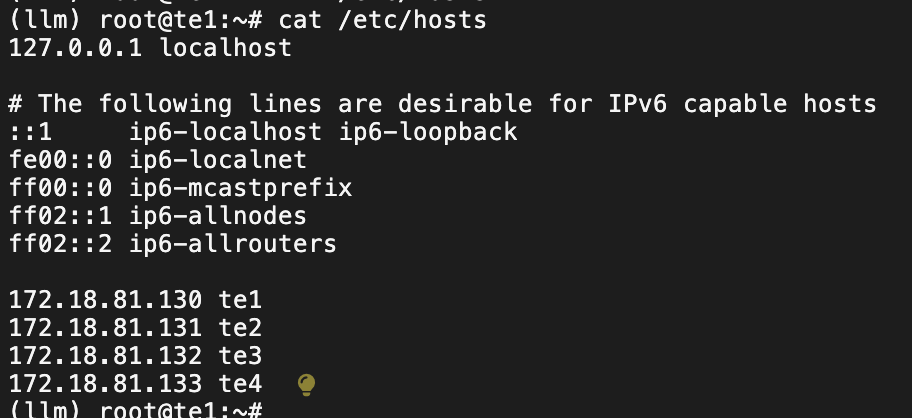
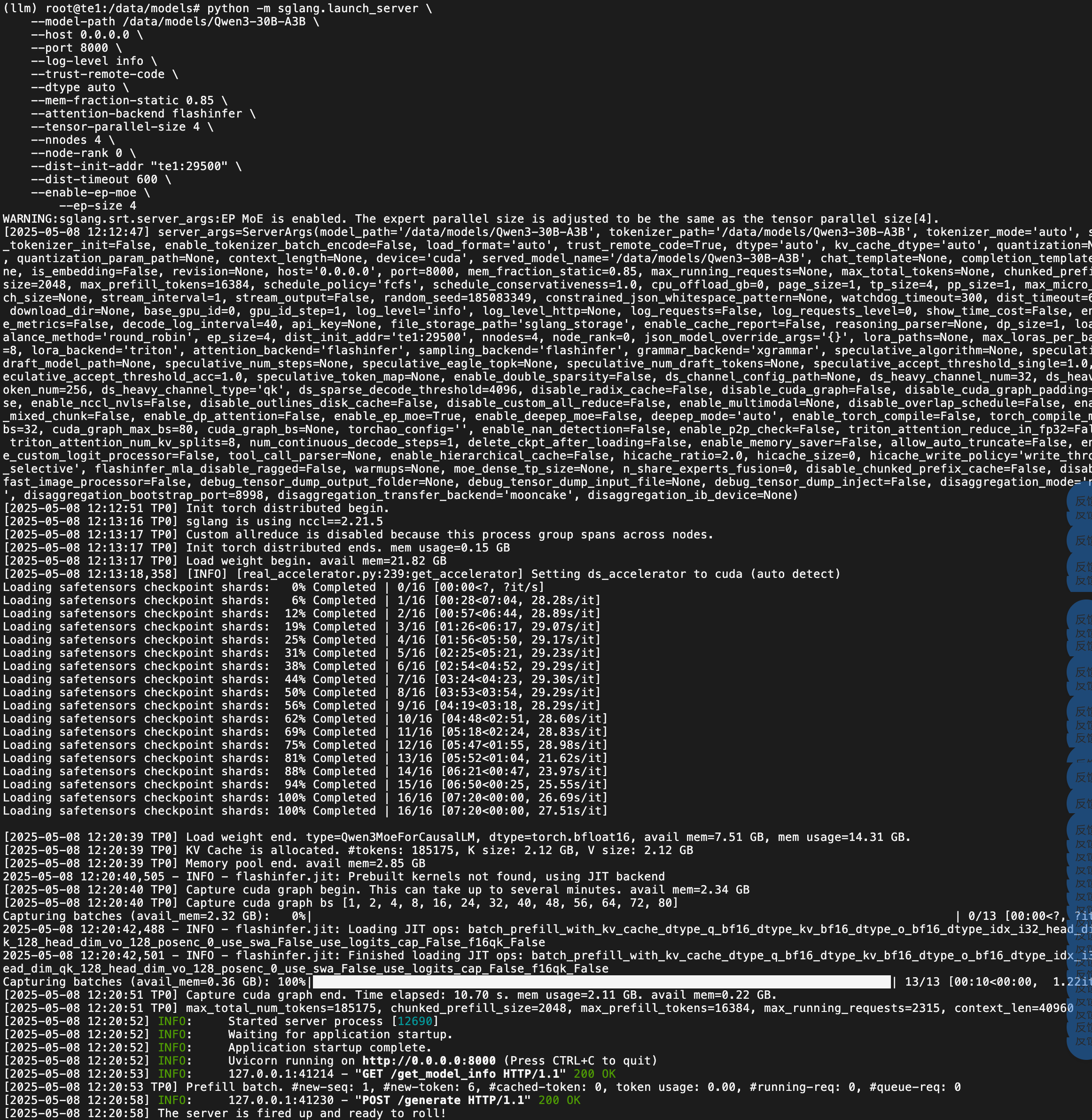
https://docs.sglang.ai/backend/server_arguments.htmlGitHub - sgl-project/sglang: SGLang is a fast serving framework for large language models and vision language models.SGLang is a fast serving framework for large language models and vision language models. - sgl-project/sglang
https://github.com/sgl-project/sglangLarge Language Models — SGLang