qidao123.com技术社区-IT企服评测·应用市场
标题:
从零开始:用PyTorch构建CIFAR-10图像分类模型到达接近1的准确率
[打印本页]
作者:
宝塔山
时间:
7 天前
标题:
从零开始:用PyTorch构建CIFAR-10图像分类模型到达接近1的准确率
为了加强代码可读性,代码均使用Chatgpt给每一行代码都参加了注释,方便各人在本文代码的底子上举行改进优化。
本文是搭建了一个稍微优化了一下的模型,训练200个epoch,准确率到达了
99.74%
,简朴完成了一下CIFAR-10数据集的实验,再调调参可能就到100%了吧,算是一个入门学习吧 ~
完整代码链接: MachineLearningCourseWork
数据: data5 - CIFAR10
完整代码ipynb格式文件: work5-CIFAR10.ipynb
【本文参考资料】
CIFAR-10 官方网站:由数据集创建者 Alex Krizhevsky 维护,提供了数据集的下载链接、格式阐明等详细信息。
Deep Learning with Python:由 Francois Chollet 撰写的深度学习册本,此中使用 CIFAR-10 数据集作为案例解说图像分类模型的构建和训练方法。
CS231n: Convolutional Neural Networks for Visual Recognition:斯坦福大学的CV课。
1. 数据集介绍
1.1 数据集概述
数据集名称:CIFAR-10
官方链接:https://www.cs.toronto.edu/~kriz/cifar.html
数据集简介:
CIFAR-10 数据集是一个广泛用于图像分类使命的基准数据集,由 Alex Krizhevsky 在 2009 年创建,是计算机视觉范畴最常用的数据集之一。它包罗 60000 张 32x32 彩色图像,分为 10 个差别的种别,每个种别有 6000 张图片,此中 50000 张用于训练模型,10000 张用于测试模型性能。
1.2 数据集结构
训练集:包罗 5 个批次,每个批次有 10000 张图像。固然训练批次内图像顺序是随机的,但各批次间图像分布可能存在不均衡,即某些批次可能包罗某一种别更多的图片,但总体来说所有训练批次合起来每个种别有 5000 张图片。
测试集:包罗 1 个批次,有 10000 张图像,每个种别在测试集中正好有 1000 张随机选择的图片。
数据集示例:
CIFAR-10 的图像涵盖了多种常见的物体种别,具体种别包括:
plane(飞机):例如各种型号的飞机在差别场景下的图片,如在天空飞行、停在机场等。
car(汽车):涵盖差别品牌、款式和颜色的汽车,可能在门路上行驶或停在停车场。
bird(鸟):包罗多种鸟类的图片,如麻雀、鸽子等,可能处在飞翔或栖息状态。
cat(猫):有差别品种、毛色和姿态的猫的图像,好比家猫、波斯猫等。
deer(鹿):展示在野外情况中的鹿,如梅花鹿等。
dog(狗):包罗各种品种的狗,如金毛犬、哈士奇等在差别场景下的图片。
frog(蛙类):有差别种类田鸡的图片,可能在水中、岸边等情况。
horse(马):展示差别品种马的图片,如在草原上奔跑或被饲养的场景。
ship(船):包罗各种船只,如货船、游轮等在水中的图片。
truck(卡车):有差别类型的卡车,如货运卡车、油罐车等的图片。
1.3 数据集格式
图像像素:每个图像都是 32x32 像素的彩色图像,具有 RGB 三个通道(数据集中自己是 BGR 通道,但在使用时通常会转换为 RGB 通道)。
存储格式:数据以 Python 拾取(pickle)文件的情势存储,包罗字典对象,此中包罗图像数据和标签等信息。在使用时,通常需要通过 Python 的 pickle 库加载数据,并将其转换为 NumPy 数组等常用数据格式以便举行处理和训练模型。
1.4 数据集应用场景
图像分类:CIFAR-10 最常见的应用场景是作为图像分类使命的数据集,用于训练和测试各种卷积神经网络(CNN)模型,如 LeNet、AlexNet、ResNet 等,评估模型对差别种别图像的识别准确率。
模型评估与比力:作为标准数据集,方便研究者和开辟者对比差别模型的性能,推动图像识别技术的发展。
迁移学习:可以作为预训练模型的底子数据集,通过在 CIFAR-10 上训练得到的模型参数,迁移到其他雷同的图像分类使命中,减少新使命的数据量需求和计算资源消耗。
深度学习研究:为深度学习算法的研究提供实验平台,例如研究新的网络架构、优化算法、正则化方法等在 CIFAR-10 数据集上的效果。
1.5 数据集特点
优势:
典范性和代表性:涵盖了多种常见的物体种别,能够反映一样平常生存中的一些根本图像分类场景,适用于研究和测试底子的图像识别模型。
规模适中:60000 张图像的数量对于现代计算资源来说既足够大以提供有代表性的数据集,又不至于过于庞大而难以处理,适合在个人计算机或小型服务器上举行实验和研究。
数据多样性:固然图像尺寸较小,但包罗差别种别、颜色、姿态和配景的图片,具有肯定的数据多样性,有助于模型学习到更通用的特征。
范围性:
图像尺寸较小:32x32 像素的图像尺寸可能限定了模型对图像细节的捕获能力,对于一些需要精细识别的使命来说,可能不敷准确,例如对于图像中一些微小特征或复杂纹理的识别。
种别相对简朴:相较于一些更复杂的图像数据集(如 ImageNet),CIFAR-10 的种别较为底子,可能无法充分测试模型在面临高度复杂、多样化的图像内容时的性能。
配景简朴:图像中的物体通常具有相对简朴的配景,这可能使模型在处理更复杂配景或具有遮挡的图像时表现不佳。
2. 实验流程
2.1 导包
import torch # 导入 PyTorch 框架,用于构建和训练深度学习模型
import torch.nn as nn # 导入 PyTorch 的神经网络模块,用于定义神经网络结构
import torch.optim as optim # 导入 PyTorch 的优化器模块,用于定义优化算法(如 SGD、Adam 等)
import torchvision # 导入 torchvision 库,提供图像处理和预训练模型等功能
import torchvision.transforms as transforms # 导入 torchvision 的数据预处理模块,用于对图像数据进行变换(如归一化、裁剪等)
from torch.utils.data import DataLoader # 导入 PyTorch 的数据加载器模块,用于批量加载和管理数据集
from datetime import datetime
import time
# 画图相关
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np # 数据计算
from torch.nn.functional import softmax #softmax函数
复制代码
2.2 数据获取与加载
# 定义一个数据预处理的组合操作
transform = transforms.Compose([
transforms.ToTensor(), # 将图像数据从 PIL 图像格式转换为 PyTorch 张量(Tensor),并将其值归一化到 [0, 1] 范围
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 对图像的每个通道进行标准化处理,均值为 0.5,标准差为 0.5
])
# 加载 CIFAR-10 训练数据集
trainset = torchvision.datasets.CIFAR10(
root='./data4', # 数据集存储的根目录路径
train=True, # 指定加载训练集
download=False, # 不从网络下载数据集(假设数据已经下载到本地)
transform=transform # 应用上面定义的预处理操作
)
# 加载 CIFAR-10 测试数据集
testset = torchvision.datasets.CIFAR10(
root='./data4', # 数据集存储的根目录路径
train=False, # 指定加载测试集
download=False, # 不从网络下载数据集(假设数据已经下载到本地)
transform=transform # 应用上面定义的预处理操作
)
复制代码
# 定义每个批次的大小
batch_size = 64 # 每个批次包含 64 张图像
# 创建训练数据的 DataLoader
trainloader = DataLoader(
trainset, # 指定加载的训练数据集
batch_size=batch_size, # 每个批次的大小
shuffle=True, # 在每个 epoch 开始时随机打乱数据顺序
num_workers=2 # 使用 2 个子进程加载数据,加速数据读取
)
# 创建测试数据的 DataLoader
testloader = DataLoader(
testset, # 指定加载的测试数据集
batch_size=batch_size, # 每个批次的大小
shuffle=False, # 测试时不需要打乱数据顺序
num_workers=2 # 使用 2 个子进程加载数据,加速数据读取
)
复制代码
2.3 界说网络
这里我界说的是一个比力简朴的卷积神经网络模型,包罗特征提取层和分类器层,但是团体的效果也还行了,可以改成ResNet18或ResNet34
# 定义一个简单的卷积神经网络模型
class TestNet(nn.Module):
def __init__(self, dropout_rate=0.5):
super(TestNet, self).__init__() # 调用父类的初始化方法
# 特征提取部分
self.features = nn.Sequential( # 定义特征提取层的序列
nn.Conv2d(3, 64, kernel_size=3, padding=1), # 第一层卷积,输入通道数为3,输出通道数为64,卷积核大小为3x3,边缘填充为1
nn.BatchNorm2d(64), # 对64个通道进行批量归一化
nn.ReLU(inplace=True), # ReLU激活函数,inplace=True表示直接在原变量上操作,节省内存
nn.Conv2d(64, 64, kernel_size=3, padding=1), # 第二层卷积,输入输出通道数均为64
nn.BatchNorm2d(64), # 批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.MaxPool2d(2, 2), # 最大池化,池化窗口大小为2x2,步长为2
nn.Dropout2d(p=dropout_rate/2), # 二维Dropout,随机丢弃一半的特征图,防止过拟合
nn.Conv2d(64, 128, kernel_size=3, padding=1), # 第三层卷积,输入通道数为64,输出通道数为128
nn.BatchNorm2d(128), # 批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.Conv2d(128, 128, kernel_size=3, padding=1), # 第四层卷积,输入输出通道数均为128
nn.BatchNorm2d(128), # 批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.MaxPool2d(2, 2), # 最大池化
nn.Dropout2d(p=dropout_rate), # Dropout
nn.Conv2d(128, 256, kernel_size=3, padding=1), # 第五层卷积,输入通道数为128,输出通道数为256
nn.BatchNorm2d(256), # 批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.Conv2d(256, 256, kernel_size=3, padding=1), # 第六层卷积,输入输出通道数均为256
nn.BatchNorm2d(256), # 批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.MaxPool2d(2, 2), # 最大池化
)
# 分类器部分
self.classifier = nn.Sequential( # 定义分类器层的序列
nn.Linear(256 * 4 * 4, 512), # 全连接层,输入特征数为256*4*4,输出特征数为512
nn.BatchNorm1d(512), # 一维批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.Dropout(p=dropout_rate), # Dropout
nn.Linear(512, 256), # 全连接层,输入特征数为512,输出特征数为256
nn.BatchNorm1d(256), # 批量归一化
nn.ReLU(inplace=True), # ReLU激活
nn.Dropout(p=dropout_rate/2), # Dropout
nn.Linear(256, 10) # 最后一层全连接层,输出10个类别
)
def forward(self, x):
x = self.features(x) # 将输入数据通过特征提取层
x = torch.flatten(x, 1) # 将特征图展平为一维向量,从第1维开始展平
x = self.classifier(x) # 将展平后的特征通过分类器层
return x # 返回最终的输出
复制代码
2.4 加强的数据预处理
# 定义训练集的数据预处理操作
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), # 随机裁剪,裁剪大小为32x32,边缘填充为4
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2), # 随机调整亮度、对比度和饱和度
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # 标准化,均值和标准差分别为CIFAR-10数据集的均值和标准差
])
# 定义测试集的数据预处理操作
transform_test = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), # 标准化
])
复制代码
net = TestNet() # 初始化
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # GPU
net.to(device)
复制代码
2.5 模型训练
# 开始训练模型
start_time = time.time() # 记录训练开始时间
for epoch in range(10): # 训练 10 个 epoch
running_loss = 0.0 # 初始化每轮的累计损失
for i, data in enumerate(trainloader, 0): # 遍历训练数据加载器
inputs, labels = data[0].to(device), data[1].to(device) # 将输入数据和标签移动到指定设备(如 GPU)
optimizer.zero_grad() # 清零梯度,避免梯度累积
outputs = net(inputs) # 前向传播,计算模型输出
loss = criterion(outputs, labels) # 计算损失值
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累加损失值
# 每 100 批次打印一次详细信息
if i % 100 == 99:
avg_loss = running_loss / 100 # 计算平均损失
print(f'[Epoch {epoch + 1}/{10}, Batch {i + 1}/{len(trainloader)}] '
f'Average Loss: {avg_loss:.4f} | '
f'Current Batch Loss: {loss.item():.4f} | '
f'Running Loss: {running_loss:.4f}')
running_loss = 0.0 # 重置累计损失
scheduler.step() # 更新学习率
end_time = time.time() # 记录训练结束时间
elapsed_time = end_time - start_time # 计算总耗时
print(f'Finished Training. Total time taken: {elapsed_time:.2f} seconds')
# 保存模型
timestamp = datetime.now().strftime("%y-%m-%d-%H-%M-%S") # 获取当前时间戳
model_name = f"CIFAR10Net-{timestamp}.pth"
torch.save(net.state_dict(), model_name)
print(f"Model saved successfully as {model_name}")
复制代码
2.6 测试准确率
# 初始化正确预测的数量和测试数据的总数
correct_predictions = 0
total_samples = 0
# 禁用梯度计算,节省内存和计算资源
with torch.no_grad():
for data in testloader: # 遍历测试数据加载器
images, labels = data[0].to(device), data[1].to(device) # 将图像和标签移动到指定设备
outputs = net(images) # 前向传播,获取模型的输出
_, predicted_labels = torch.max(outputs.data, 1) # 获取预测的类别(概率最高的类别)
total_samples += labels.size(0) # 累加测试数据的总数
correct_predictions += (predicted_labels == labels).sum().item() # 累加正确预测的数量
# 计算准确率
accuracy = 100 * correct_predictions / total_samples
print(f'Accuracy: {accuracy:.2f}%') # 打印准确率
复制代码
2.7 收集所有样本的猜测概率
import numpy as np
from torch.nn.functional import softmax
# 初始化两个列表,用于保存所有样本的预测概率和真实标签
all_preds = [] # 保存所有样本的预测概率
all_labels = [] # 保存所有真实标签
# 使用torch.no_grad()上下文管理器,这可以暂时禁用计算图中的梯度计算,节省内存和计算资源
with torch.no_grad():
for data in testloader: # 遍历测试数据加载器testloader
images, labels = data[0].to(device), data[1].to(device) # 将图像和标签数据移动到指定的设备(如GPU)
outputs = net(images) # 通过神经网络模型net获取预测输出
probabilities = softmax(outputs, dim=1) # 将输出转换为概率分布,dim=1表示在类别维度上进行softmax操作
all_preds.append(probabilities.cpu().numpy()) # 将概率分布转移到CPU并转换为numpy数组,然后添加到all_preds列表中
all_labels.append(labels.cpu().numpy()) # 将标签数据转移到CPU并转换为numpy数组,然后添加到all_labels列表中
# 合并所有批次的结果,使用numpy的concatenate函数沿着第一个轴(axis=0)合并数组
all_preds = np.concatenate(all_preds, axis=0) # 形状 [N, 10],其中N是样本总数,10是类别数
all_labels = np.concatenate(all_labels, axis=0) # 形状 [N, ],其中N是样本总数
复制代码
2.8 评价一下
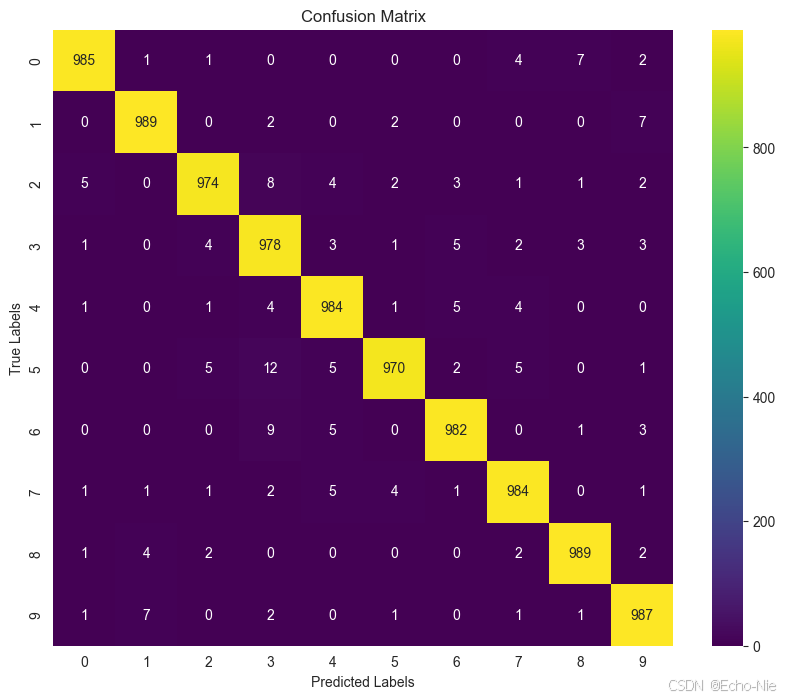
2.8.1 混淆矩阵
from sklearn.metrics import confusion_matrix # 导入混淆矩阵计算函数
import seaborn as sns # 导入seaborn库,用于绘制热图
import matplotlib.pyplot as plt # 导入matplotlib库,用于绘图
# 初始化两个列表,用于存储模型预测的标签和真实标签
all_preds, all_labels = [], []
# 使用torch.no_grad()来禁用梯度计算,因为在测试阶段不需要计算梯度
with torch.no_grad():
# 遍历测试数据加载器
for data in testloader:
# 将图像数据和标签数据移动到设备上(如GPU)
images, labels = data[0].to(device), data[1].to(device)
# 将图像数据输入模型进行预测
outputs = net(images)
# 获取模型输出中概率最大的索引,即预测的类别
_, predicted = torch.max(outputs, 1)
# 将预测的类别和真实类别添加到列表中
all_preds.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
# 计算混淆矩阵
cm = confusion_matrix(all_labels, all_preds)
# 设置图形的大小
plt.figure(figsize=(10, 8))
# 使用seaborn库绘制热图,显示混淆矩阵
# annot=True表示在每个单元格中显示数值,fmt='d'表示数值格式为整数
# cmap='viridis'指定使用viridis配色方案
sns.heatmap(cm, annot=True, fmt='d', cmap='viridis')
plt.title('Confusion Matrix')
plt.xlabel('Predicted Labels')
plt.ylabel('True Labels')
plt.show()
复制代码
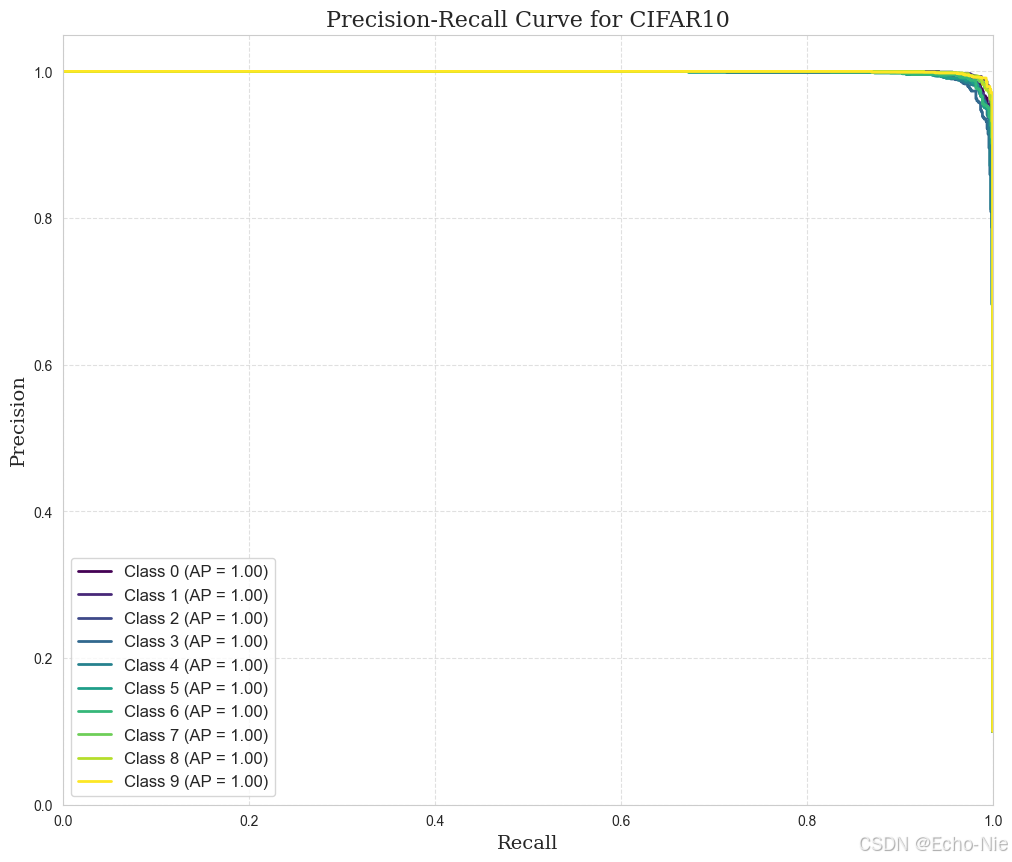
2.8.2 准确 - 召回
from sklearn.metrics import precision_recall_curve, auc
import matplotlib.pyplot as plt
import numpy as np
n_classes = 10 # CIFAR10数据集有10个类别
# 初始化字典来存储每个类别的精确度、召回率和平均精确度
precision = dict()
recall = dict()
average_precision = dict()
# 遍历所有类别
for i in range(n_classes):
# 提取第i类的概率作为预测分数,并生成对应的二分类标签
precision[i], recall[i], _ = precision_recall_curve(
(all_labels == i).astype(int),
all_preds[:, i]
)
average_precision[i] = auc(recall[i], precision[i])
plt.figure(figsize=(12, 10), dpi=100)
colors = plt.cm.viridis(np.linspace(0, 1, n_classes))
for i in range(n_classes):
plt.plot(recall[i], precision[i], color=colors[i], lw=2, label=f'Class {i} (AP = {average_precision[i]:.2f})')
plt.xlabel('Recall', fontsize=14, fontfamily='serif')
plt.ylabel('Precision', fontsize=14, fontfamily='serif')
plt.title('Precision-Recall Curve for CIFAR10', fontsize=16, fontfamily='serif')
plt.legend(loc='best', fontsize=12, frameon=True)
plt.grid(True, linestyle='--', alpha=0.6)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.savefig('precision_recall_curve.png', bbox_inches='tight')
plt.show()
复制代码
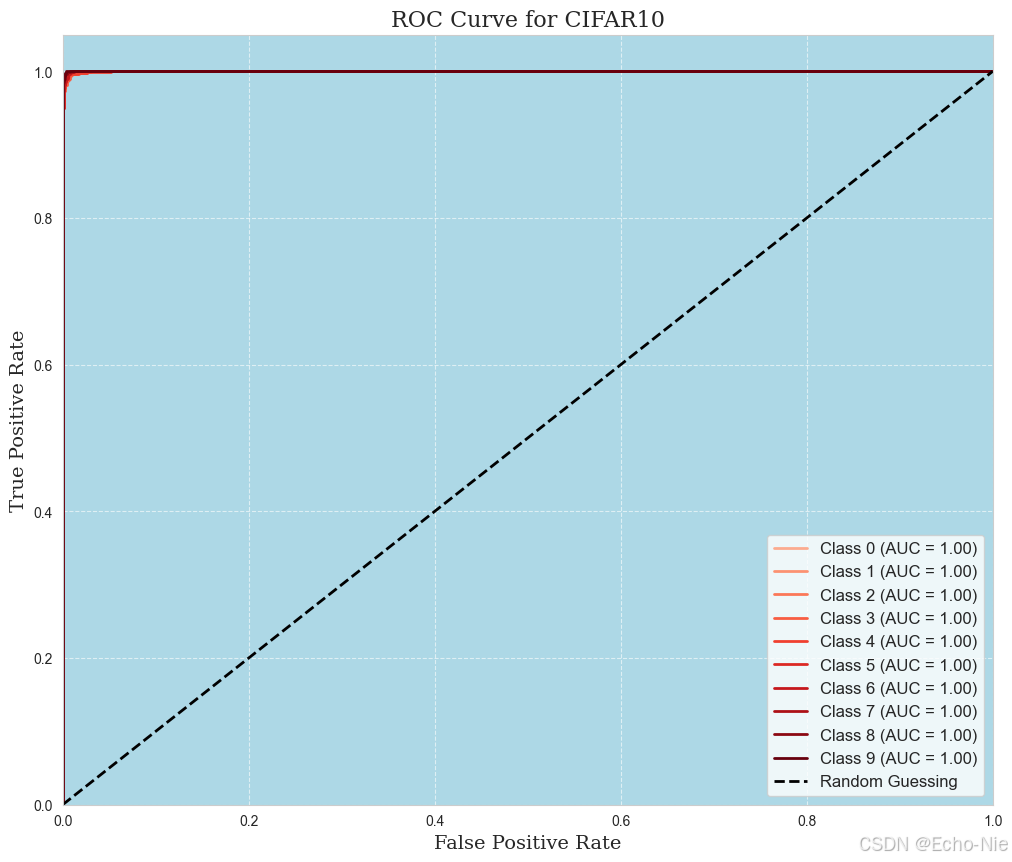
2.8.3 ROC曲线
from sklearn.preprocessing import label_binarize
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
import numpy as np
# ROC曲线
all_labels_binarized = label_binarize(all_labels, classes=np.arange(n_classes))
all_preds_binarized = all_preds
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(all_labels_binarized[:, i], all_preds_binarized[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
plt.figure(figsize=(12, 10), dpi=100)
plt.gca().set_facecolor('#ADD8E6')
colors = plt.cm.Reds(np.linspace(0.3, 1, n_classes))
for i in range(n_classes):
plt.plot(fpr[i], tpr[i], color=colors[i], lw=2, label=f'Class {i} (AUC = {roc_auc[i]:.2f})')
plt.plot([0, 1], [0, 1], 'k--', lw=2, label='Random Guessing')
plt.xlabel('False Positive Rate', fontsize=14, fontfamily='serif')
plt.ylabel('True Positive Rate', fontsize=14, fontfamily='serif')
plt.title('ROC Curve for CIFAR10', fontsize=16, fontfamily='serif')
plt.legend(loc='best', fontsize=12, frameon=True)
plt.grid(True, linestyle='--', alpha=0.6, color='white')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.savefig('roc_curve_red.png', bbox_inches='tight')
plt.show()
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4