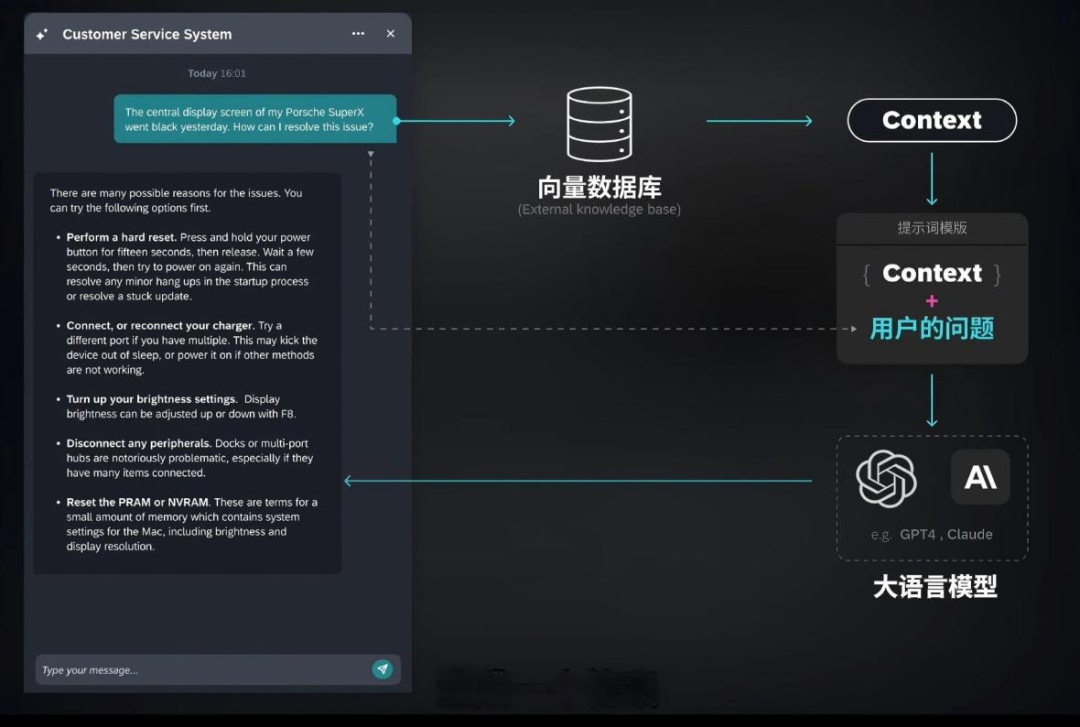
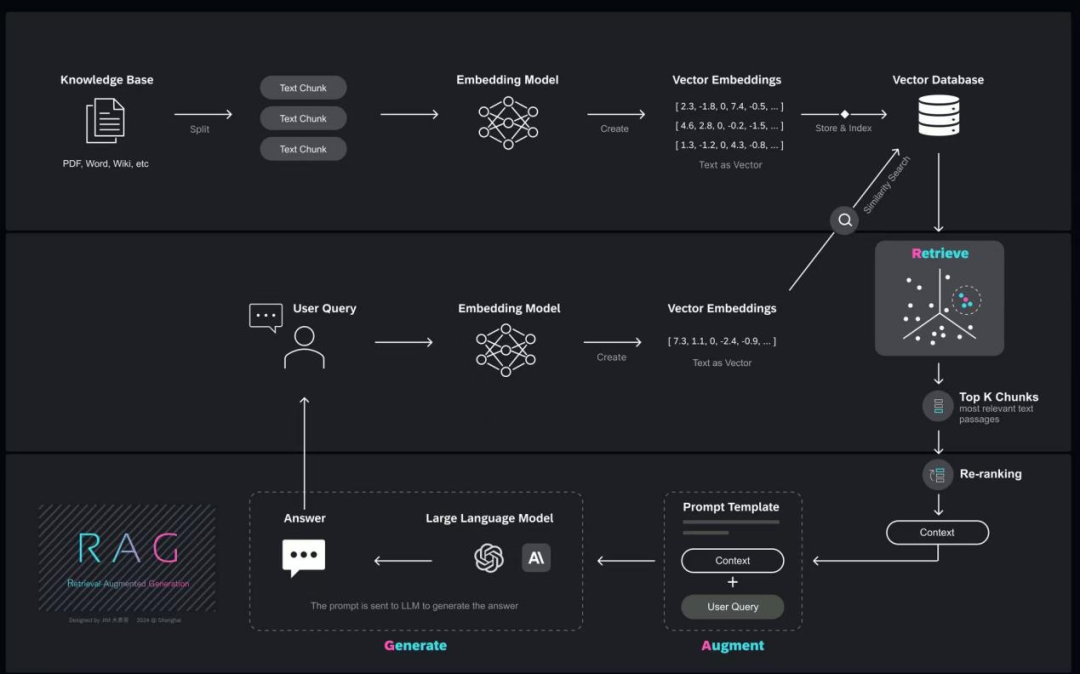
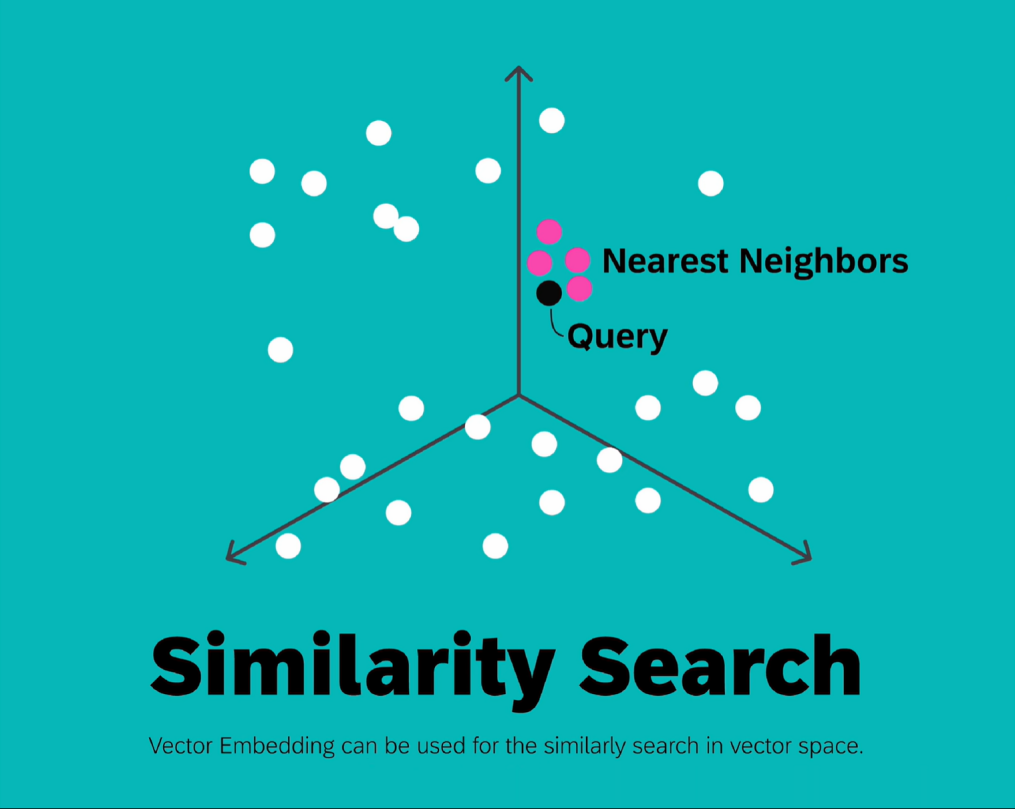
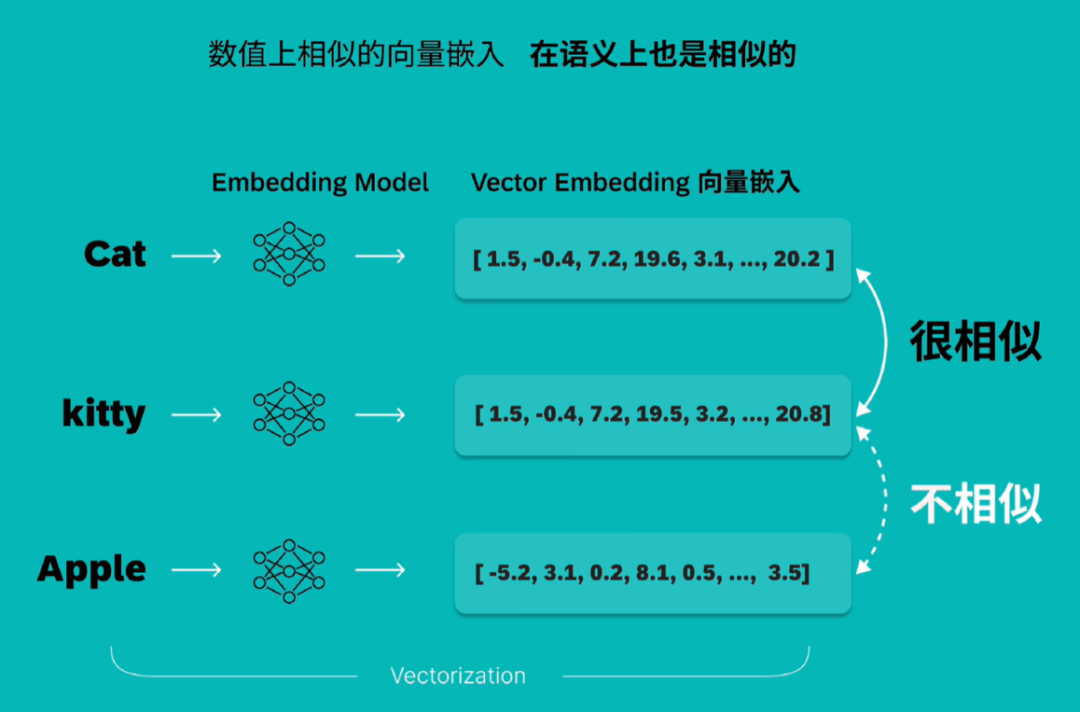
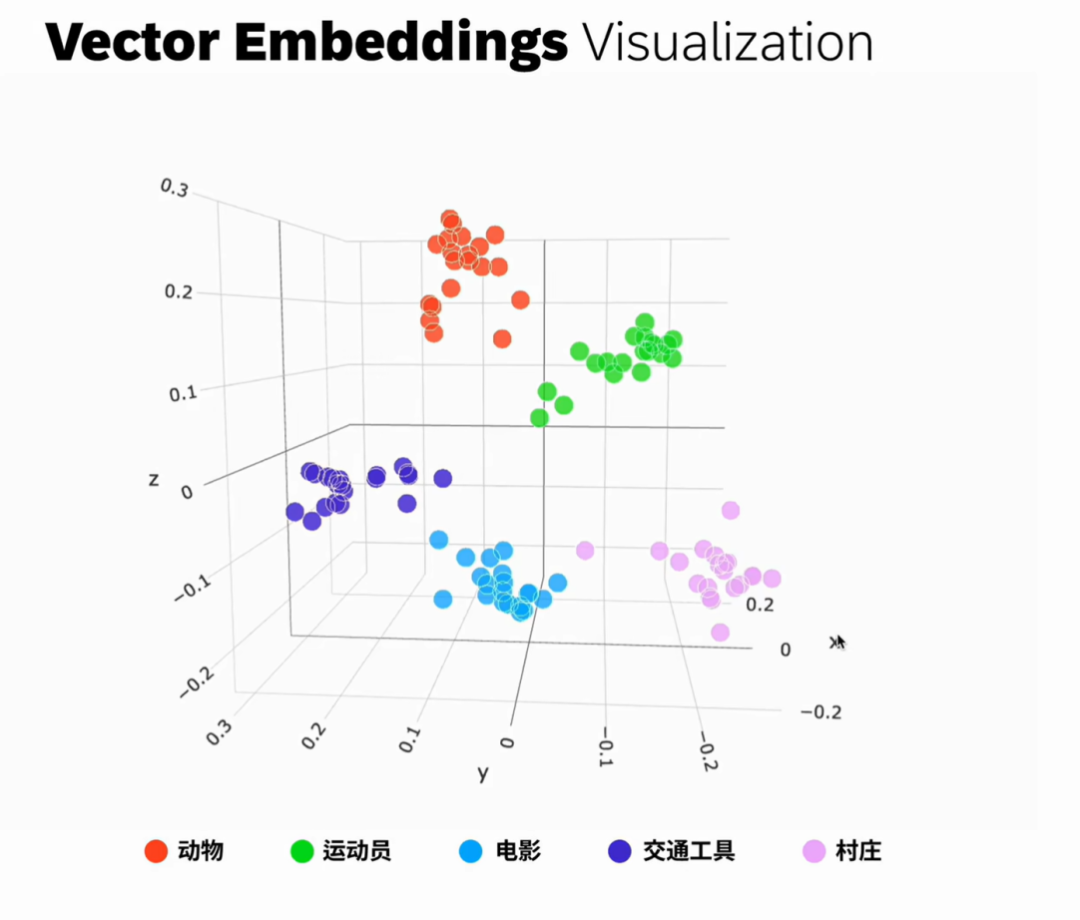
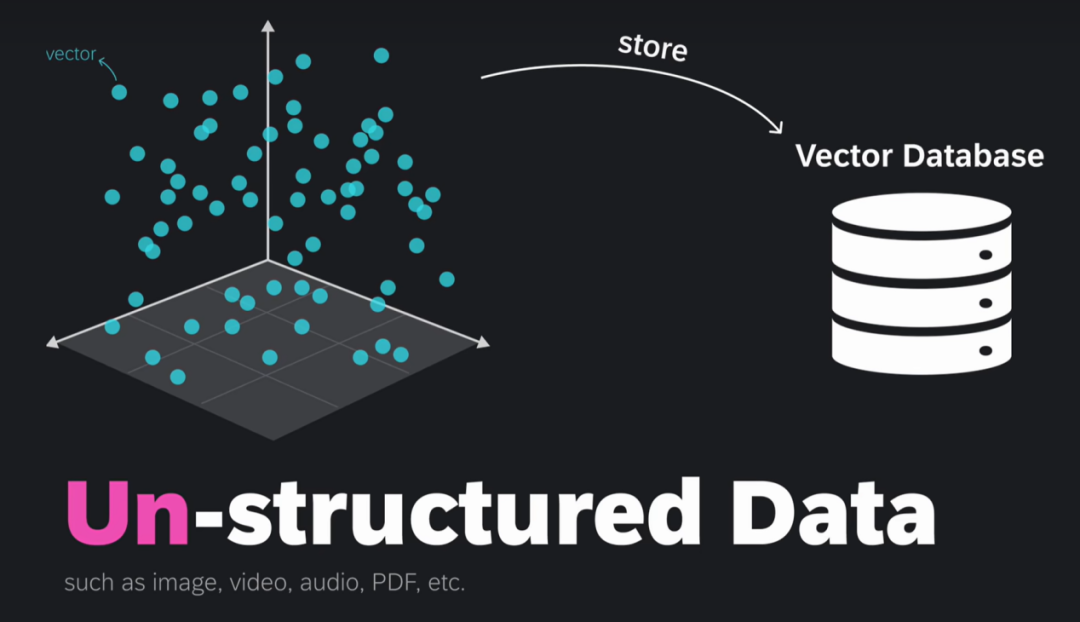
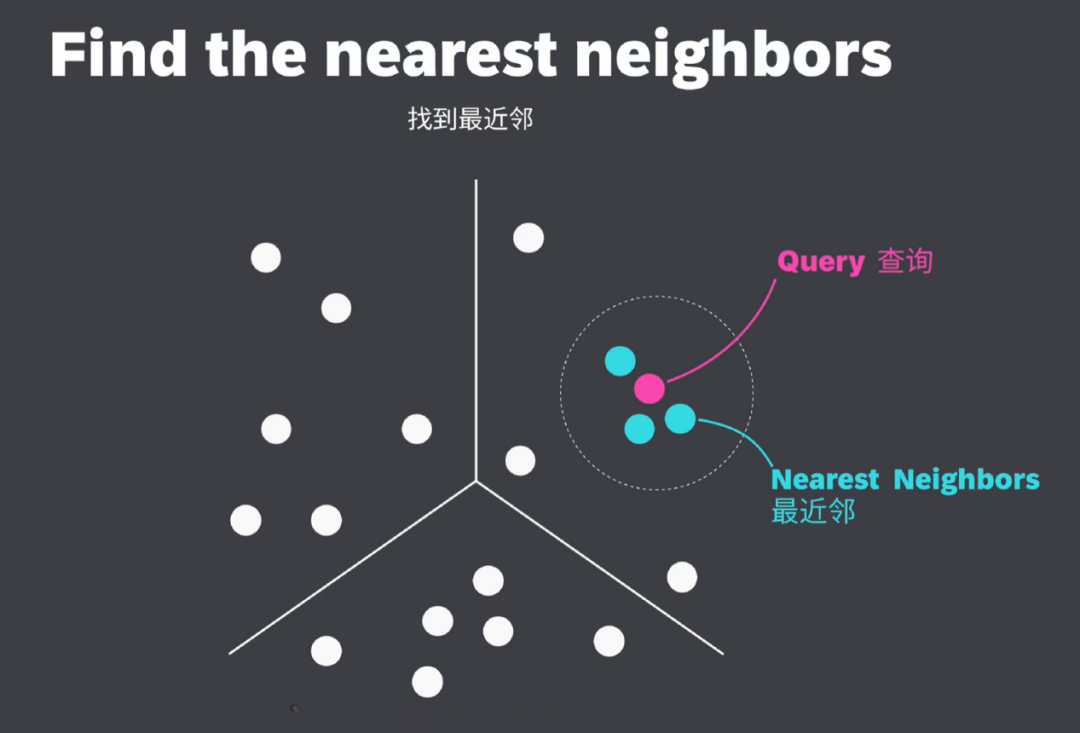
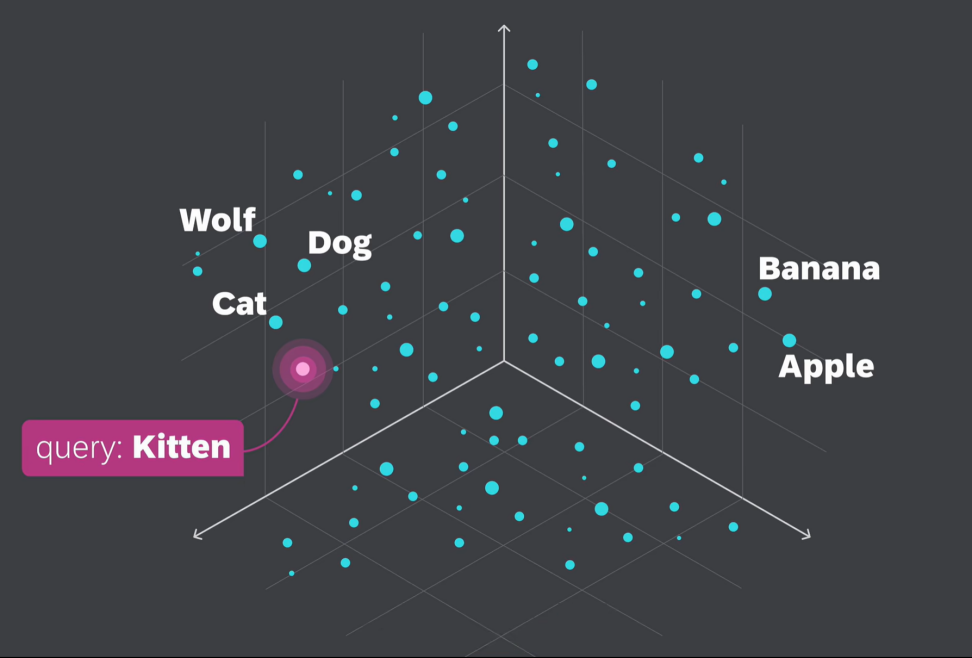
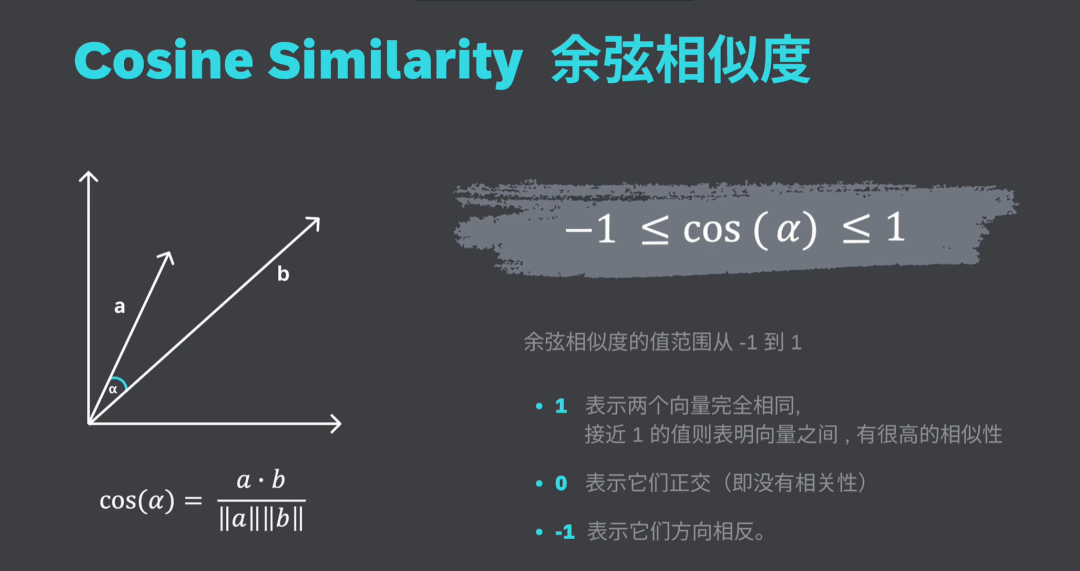
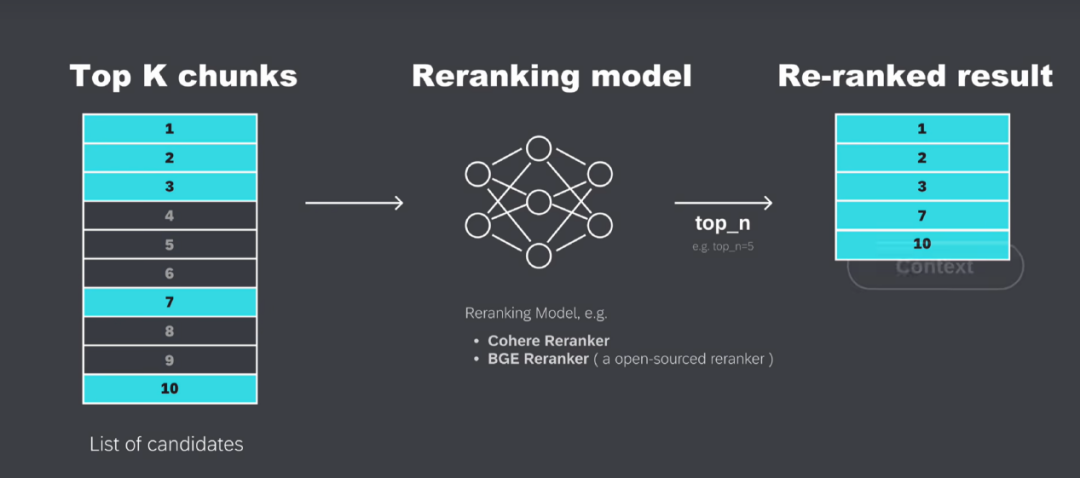
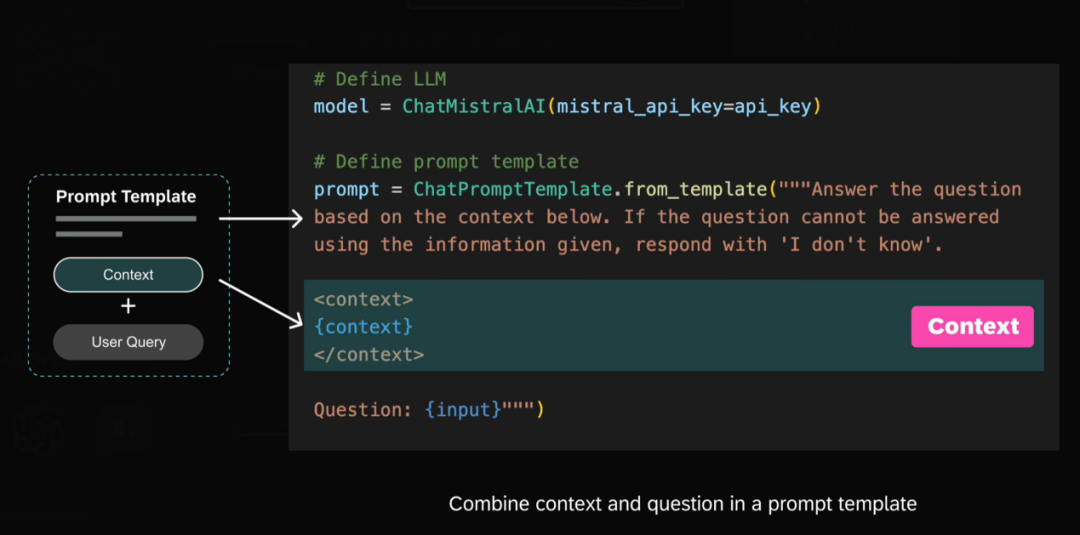
向量嵌入是用一组数值表现的数据对象,在多维空间中捕捉文本、图像或音频的语义和关联,可以让呆板学习算法可以或许更轻松地对其进行处理和解读。
比如:I love Tennis.我们先把I love Tennis.转换为几个token,再用Embeddings Model嵌入模子来生成embeddins。比如:单词I就转换为向量嵌入,所谓向量就是一个数字数组。其中每个数值表现对象在特定维度上的特性或属性,这就是I love Tennis.这句话的Vector Embeddings。
对全球大模子从性能、吞吐量、资本等方面有一定的认知,可以在云端和本地等多种情况下部署大模子,找到适合本身的项目/创业方向,做一名被 AI 武装的产物经理。
硬件选型
带你相识全球大模子
利用国产大模子服务
搭建 OpenAI 代理
热身:基于阿里云 PAI 部署 Stable Diffusion
在本地计算机运行大模子
大模子的私有化部署
基于 vLLM 部署大模子
案例:如何优雅地在阿里云私有部署开源大模子
部署一套开源 LLM 项目
内容安全
互联网信息服务算法存案
…
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的本身。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模子 AI 的正确特性了。
这份完整版的大模子 AI 学习资料已经上传CSDN,朋友们如果须要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】