qidao123.com技术社区-IT企服评测·应用市场
标题:
【深度学习】目标检测算法大全
[打印本页]
作者:
温锦文欧普厨电及净水器总代理
时间:
前天 11:08
标题:
【深度学习】目标检测算法大全
目录
一、R-CNN
1、R-CNN概述
2、R-CNN 模子总体流程
3、核心模块详解
(1)候选框天生(Selective Search)
(2)深度特性提取与微调
2.1 特性提取
2.2 网络微调(Fine-tuning)
(3)后端分类与边框回归
3.1 SVM 分类器
3.2 边框回归(BBox Regression)
4、训练与推理流程一览
5、模子性能与瓶颈
6、对后续模子的启示
二、SPPNet
1、模子动机
2、网络团体结构
3、数学原理与细节
4、训练与微调计谋
5、性能评估
6、优缺点与局限
(1)长处
(2)缺点
7、对后续模子的启示
三、FastRCNN
1、Fast R-CNN 概述
2、网络结构
3、关键技能点
4、训练与推理流程
5、优缺点分析
6、后续演进
四、FasterRCNN
1、Faster R-CNN 概述
2、团体网络结构
3、关键技能点
(1)区域建议网络(RPN)
(2)多任务联合训练
(3)RoI Pooling 与后端 Head
4、训练与推理流程
(1)训练阶段
(2)推理阶段
5、优势与挑战
(1)长处
(2)缺点
6、后续演进
五、YOLO
1、YOLO 概述
2、基础网络结构(以 YOLOv1 为例)
3、关键技能点
4、训练与推理流程
5、优缺点分析
6、后续演进与分支
六、SSD
1、模子动机
2、网络团体结构
3、关键技能点
4、训练与推理流程
5、性能与优缺点
6、后续演进
七、DETR
1、动机背景
2、团体架构概览
3、核心组件详解
(1)Object Queries
(2)注意力机制
(3)位置编码(Positional Encoding)
(4)匈牙利匹配(Hungarian Matching)
(5)Set Prediction Loss
4、训练与推理流程
5、优缺点对比
6、后续改进与演进
一、R-CNN
1、R-CNN概述
R-CNN由Ross Girshick等人在2014年提出,是首批将深度卷积神经网络引入目标检测的经典方法。它将对象检测题目分解为“候选区域天生+分类+回归”三步走流程,有效地使用了深度特性,明显提升了检测精度,但也袒露出计算效率低的题目。
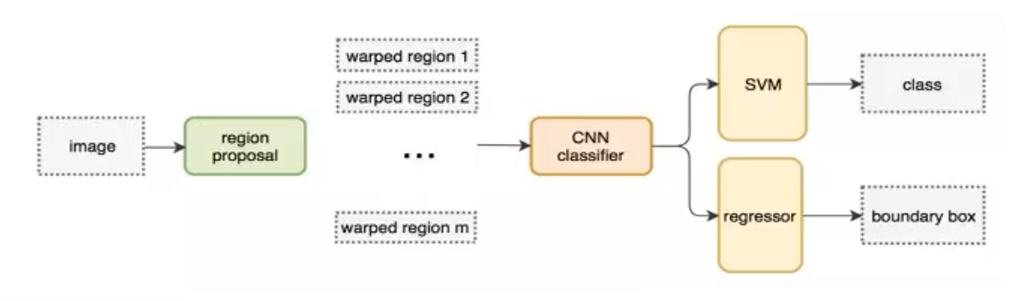
2、R-CNN 模子总体流程
R-CNN 将目标检测拆分为三大阶段:
候选框天生
(Selective Search)
深度特性提取 & 微调
(CNN + Fine-tune)
后端分类与回归
(SVM + BBox Regression)
在推理时,依次执行以上三步,最终得到检测框与种别。
3、核心模块详解
(1)候选框天生(Selective Search)
原理
:结合图像分割(Felzenszwalb 算法)和贪心区域合并,先基于颜色、纹理、尺寸、添补比等多种相似度逐层合并超像素;
输出
:每幅图约 2,000 个高召回率的候选框,IoU 覆盖率可达 90% 以上。
loU:交并比
复杂度
:O(n log n),在 CPU 上每图耗时 ≈2 秒。
(2)深度特性提取与微调
2.1 特性提取
网络结构
:采用 ImageNet 上预训练的 AlexNet 或 ZF-Net,去掉最后的分类层,仅保留到 fc7(4096 维特性)。
输入处置惩罚
:对每个候选框执行:
裁剪
:从原图裁剪出 bbox 区域;
Warp
:双线性插值将裁剪区域缩放至固定的 227×227;
前向流传
:单独将每个 patch 送入 CNN,提取 fc7 特性。
计算量
:每个候选框一次完整的 227×227→conv→pool→fc 计算,推理时≈2,000次,导致极高的计算开销。
2.2 网络微调(Fine-tuning)
目标
:使预训练分类网络更顺应目标检测的特性分布;
流程
:
用候选框 patch 及其对应的真实标签(正样本 IoU ≥0.5,负样本 IoU ≤0.3)构成训练集;
定义多分类交织熵损失,微调网络最后两层(fc6、fc7)及分类层;
学习率较小(如原 lr 的 0.1–0.01),以防过拟合。
效果
:特性在检测任务上表现更优,但训练时间仍需数小时至十数小时。
(3)后端分类与边框回归
3.1 SVM 分类器
训练
:对每个种别训练一个 one-vs-all 线性 SVM,损失:
xi:CNN 提取的 4096 维特性;
:正负样本标签;
C:正则化权重。
样本
:正样本 IoU ≥0.5,负样本 IoU ∈ [0.1, 0.5);对负样本进行难例挖掘(bootstrapping),过滤易分类样本。
3.2 边框回归(BBox Regression)
目标
:将候选框
校正到更精确的 ground-truth 框
;
回归参数
:
学习
:对每个种别训练一个线性回归器,最小化平滑 L1 损失:
4、训练与推理流程一览
阶段步骤
训练
1. 天生候选框;
2. 裁剪 Warp → CNN 微调;
3. 提取 fc7 特性 → 训练 SVM;
4. 用正样本训练边框回归器。
推理
1. 天生候选框;
2. 对每个框 Warp → CNN 前向 → 提取特性;
3. SVM 分类得分 + 回归偏移;
4. NMS 去重。
5、模子性能与瓶颈
检测精度
在 PASCAL VOC 2007 上,R-CNN mAP 可达 58.5%(AlexNet)、62.2%(ZF-Net);
速率与资源
训练
:微调+特性提取+SVM 训练,整个流水线需数天;
推理
:每张图约需 47s(CPU)或 10s(GPU);
存储
:需缓存全部候选框的 4096D 特性(数 GB)。
瓶颈分析
重复卷积
:2000 个候选框各自前向,卷积计算完全冗余;
多阶段训练
:微调、特性提取、SVM、回归器四步差别目标,难以端到端优化;
候选框依靠
:Selective Search 慢且无法并行 GPU 加速。
6、对后续模子的启示
共享特性计算
:Fast R-CNN 引入 RoI Pooling,整图一次卷积后共享特性,办理了重复计算;
端到端训练
:Fast R-CNN 及 Faster R-CNN 通过多任务损失实现单阶段训练;
候选框网络化
:Faster R-CNN 的 RPN 将 region proposal 也集成到网络,进一步加速;
空间对齐精度
:Mask R-CNN 用 RoIAlign 消除量化误差,提升小目标检测与分割精度。
二、SPPNet
1、模子动机
传统 CNN(如 AlexNet、ZF-Net)在处置惩罚目标检测或图像检索时,必要将输入裁剪或变形到固定尺寸,才能接入全毗连层。这带来两个重要题目:
形变失真
:对长宽比差异大的图像或候选区域,Warp 变形会丢失部门多少信息;
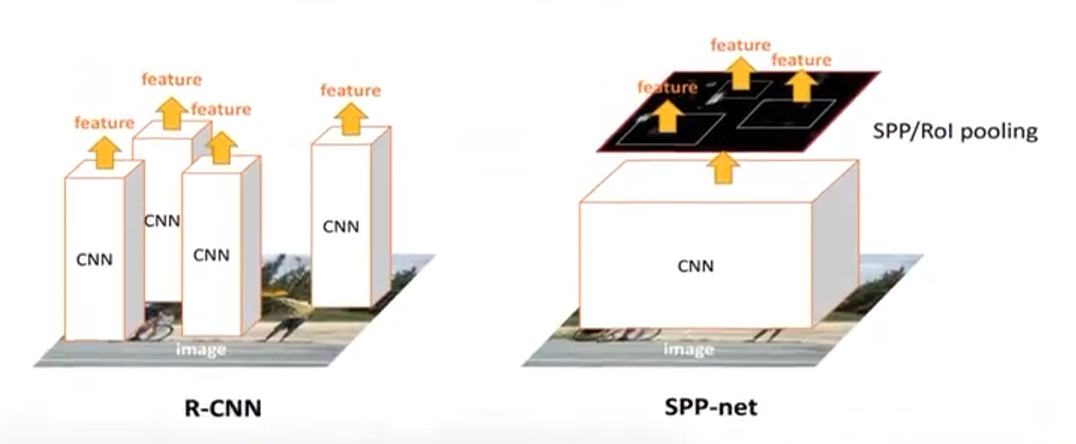
重复计算
:R-CNN 对每个候选框都要做一次完整的前向流传,极其低效。
SPPNet 的核心动机便是:
一张图片直接全部进行卷积,卷积后再思量从特性图上裁剪2000个子特性图,比R-CNN计算2000次卷积计算量减少了很多。裁剪子特性图是依照原图的2000个候选框地点原图的位置,在总的特性图上进行裁剪作为某个候选框的特性图。这时候,差别候选框的特性图的大小是不类似的。
多尺度池化
统一特性图大小。
解除输入尺寸限定;
在
卷积特性图
上直接进行多尺度池化,实现对差别大小 ROI 的统一表征;
保留 CNN 的强大特性表达,同时大幅减少重复计算。
2、网络团体结构
输入:任意尺寸图像
│
多层卷积 + 池化 → 特征图 F(尺寸为 H×W×C)
│
┌──────────────────────────────────────────┐
│ 空间金字塔池化层 SPP(F) │
│ ┌── Level 1: 1×1 划分 → 每格 max-pool │
│ ├── Level 2: 2×2 划分 → 每格 max-pool │
│ ├── Level 3: 3×3 划分 → 每格 max-pool │
│ └── Level 4: 6×6 划分 → 每格 max-pool │
└──────────────────────────────────────────┘
│
向量拼接 → 固定长度特征向量
│
FC6 → FC7 → 分类 & 边框回归
复制代码
卷积主干
:通常使用与 R-CNN 类似的预训练网络(AlexNet、ZF-Net),只去掉最后的 FC 层。
SPP 层
:在 F 上以多种网格尺寸(如 1×1、2×2、3×3、6×6)做 max-pooling,每个尺度产生
个区域的池化值,并将全部尺度效果串联。
输出维度
:若 F 的通道数为 C,则各尺度输出通道总数为
该固定长度特性向量即可接入后续 FC。
3、数学原理与细节
SPP 池化区域计算
对于特性图大小为 (H,W),在第
级金字塔(划分为
)中,第
个子网格的空间范围为
对此区域在通道维做 max-pooling,得到一个长度为 C 的向量。
梯度反向流传
SPP 层中每个子网格的 max-pooling 对应一个可微分的操纵,最大值地点位置在反向时得到梯度,其他位置梯度为 0。如许上层的损失能正确传至主干网络。
与单尺度池化的比力
传统 RoI Pooling 仅做单个尺度(如 7×7)池化;
SPP 在多个尺度融合上下文信息,兼具全局与局部表征,有助于多尺寸目标的检测。
4、训练与微调计谋
预训练
在 ImageNet 上训练主干卷积部门,得到基础权重。
候选框天生
使用 Selective Search 或 EdgeBoxes 等算法天生 Region Proposals。
共享卷积特性提取
整图一次前向卷积,得到特性图 F;
对每个 RoI 在 F 上进行 SPP 池化,制止了 R-CNN 对每个 RoI 重复前向。
FC 层微调
将 SPP 层输出送入 FC6、FC7,联合微调这些层及主干的后几层;
损失函数同 Fast R-CNN,包含分类交织熵与回归平滑 L1,两者加权求和。
学习率与训练批次
通常先冻结 backbone,仅微调 FC;
再放开 backbone 后几层,使用较小学习率(如 0.001→0.0001)做细调;
每批采样多少图像和多少 RoI(例如 2 图 × 128 RoI)。
5、性能评估
方法PASCAL VOC07 mAPGPU 推理速率R-CNN58.5% (AlexNet)≈0.5 FPSSPPNet59.2% (ZF-Net)≈8 FPSFast R-CNN66.9% (ZF-Net)≈5 FPS
SPPNet 相比 R-CNN,在 mAP 上持平或略增,同时速率提升约
16 倍
。
与后来端到端的 Fast R-CNN 相比,SPPNet 在速率上仍有优势,但准确率略低,因为 RoI Pooling 的设计及训练流程更成熟。
6、优缺点与局限
(1)长处
恣意尺寸支持
:无需裁剪 Warp,图像及 RoI 保持原始比例;
多尺度上下文融合
:差别金字塔层分身全局与细节;
高效共享计算
:整图卷积一次完成,大幅低落重复量。
(2)缺点
外部候选框依靠
:仍需 Selective Search,速率瓶颈未彻底办理;
金字塔固定模式
:预设的层数和网格尺寸不够自顺应;
内存与计算
:SPP 输出维度大(如 C×50),大概导致 FC 计算量和内存占用增加。
7、对后续模子的启示
RoI Pooling
:Fast R-CNN 将 SPP 简化为单尺度,使代码实现更直观;
RPN
:Faster R-CNN 继承 SPPNet 的共享特性头脑,把候选框天生也 “网络化”;
RoIAlign
:Mask R-CNN 在 Pooling 对齐上更精致,办理量化误差;
自顺应池化
:后续工作(如 TridentNet)探索动态或可学习的多尺度池化方案。
三、FastRCNN
1、Fast R-CNN 概述
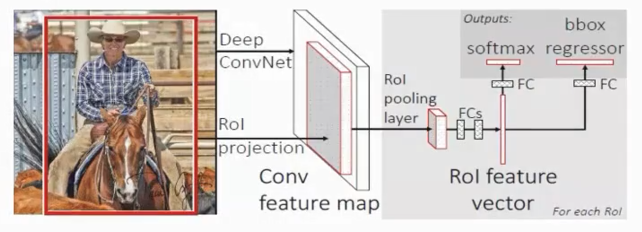
Fast R-CNN 由 Ross Girshick 于 2015 年提出,旨在在保持高精度的同时,进一步加速 R-CNN 系列模子的检测速率。它结合了 R-CNN 和 SPPNet 的头脑,引入了
RoI Pooling
操纵,使得全部候选区域共享整图一次卷积特性,并能在网络端到端地联合训练分类和回归分支。
改进点:提出一个Rol pooling,然后整合整个模子,把CNN、SPP变换层、分类器、bbox回归几个模块一起训练。
2、网络结构
团体可分为以下几个模块(见下图示意):
输入图像─────────────────────────────────┐
│ │
卷积 / 池化 层(backbone,如 VGG16)
│ 候选框
特征图 ──────┐
│ │
RoI Pooling ───────────────────┴
│
全连接层(FC6→FC7)
│
┌────────┴────────┐
│ │
分类分支 (Softmax) 边框回归分支 (BBox Regression)
复制代码
Backbone(主干网络)
常用 VGG16、ZFNet 等预训练网络的前多少层(直到 conv5)
对整张图只做一次前向流传,输出高维特性图。
Region Proposals
输入:使用外部算法(如 Selective Search)天生约 2,000 个候选框。
这些候选框具有相对原图的坐标位置。
RoI Pooling 层
输入
:主干网络产生的特性图 + 各 ROI 坐标
操纵
:将每个 ROI 在特性图上按照预定分辨率(如 7×7)划分网格,并在每个网格中进行最大池化。
输出
:对于每个 ROI 都得到一个固定尺寸(7×7×C)的特性块。
全毗连层 & Head
Flatten → FC6 → FC7
:将每个 ROI 的池化特性扁平化,经两层全毗连得到 4096 维向量。
双分支输出
:
分类分支
:Softmax 输出 K+1 种别(K 个目标种别 + 背景)。
回归分支
:每个前景种别都有一组 4 维回归参数,用于微调 ROI 的坐标。
3、关键技能点
RoI Pooling
核心价值
:使得来自差别大小 ROI 的特性都能被池化为类似尺寸,简化后续全毗连处置惩罚;
高效共享
:全部 ROI 共享同一次卷积特性,大幅减少重复计算,团体速率可提升到 5–10 FPS。
端到端多任务联合训练
损失函数
p:预测的种别概率分布;
u:真实种别标签;
t:预测的回归偏移;
v:真实偏移目标;
:交织熵损失,
:平滑 L1 损失,只对前景 ROI 生效(u≥1指示函数)。
优势
:分类和回归在同一网络中共同优化,特性能同时分身两者需求。
Mini-batch 设计
每次迭代从多少图像中采样固定数量的 RoI(如 2 图像、每图 128 个 RoI),保持训练稳定;
正负样本比通常设为 1:3,并使用 IoU 阈值(正样本 IoU ≥ 0.5,负样本 IoU ≤ 0.5)。
Backpropagation 流向
RoI Pooling 可视为可微分操纵,其梯度能“准确地”分配回对应的特性图单元;
既更新全毗连层,也更新 backbone 的卷积层,实现真正的端到端微调。
4、训练与推理流程
训练阶段
预训练
:在 ImageNet 上训练 backbone 网络;
天生候选框
:对训练集产生 RoI;
特性与 RoI Pooling
:整图卷积 → RoI Pooling 得到固定特性;
前向+损失
:过 FC → 计算分类与回归损失;
反向流传
:梯度通过 FC、RoI Pooling 传至卷积层,联合更新全部参数。
推理阶段
对输入图像天生 RoI;
整图一次卷积 → 特性图;
对每个 RoI 做 Pooling → FC → 得到各种别得分和回归偏移;
对每个种别应用偏移校正并执行 NMS,输出最终检测效果。
5、优缺点分析
长处
速率大幅进步
:共享卷积计算 + RoI Pooling,团体检测速率可达 5–10 FPS;
端到端训练
:分类与回归任务在同一框架内联合优化,简化流程;
简朴素用
:只需替换 R-CNN 中的特性抽取与 SVM、回归器,结构清晰。
缺点
仍依靠外部候选框
:Selective Search 速率瓶颈未解;
Pool 格网量化误差
:RoI Pooling 的离散网格大概丢失对齐精度,尤其对细小目标不友好;
内存与计算
:处置惩罚数千 RoI 时,后端 FC 计算仍旧较重。
6、后续演进
Faster R-CNN
(2015)
用 RPN 代替外部候选框,真正实现端到端、及时化的候选区域天生。
Mask R-CNN
(2017)
引入
RoIAlign
,消除量化误差;新增实例分割分支。
Cascade R-CNN
、
Libra R-CNN
等
针对差别 IoU 阈值的多级检测头设计;对样本分布进行平衡处置惩罚。
四、FasterRCNN
1、Faster R-CNN 概述
Faster R-CNN 由 Shaoqing Ren 等人在 2015 年提出,可看作 Fast R-CNN 与
区域建议网络
(RPN, Region Proposal Network)的有机结合。相比于依靠外部候选框天生(Selective Search)的 Fast R-CNN,Faster R-CNN 通过 RPN 在共享特性上及时天生高质量的候选区域,
真正实现了端到端、近及时的目标检测。
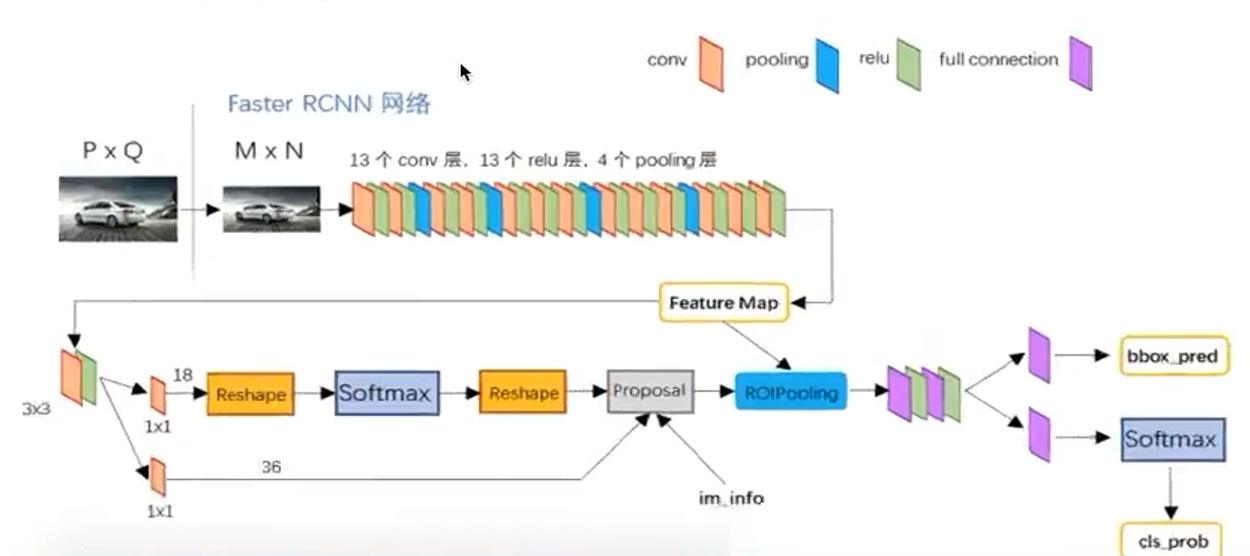
2、团体网络结构
Backbone
:常用 VGG16、ResNet-50/101 等,提取整图卷积特性。
RPN(Region Proposal Network)
:在特性图上滑动窗口,天生候选框及其前景概率和边框回归偏移。
RoI Pooling
:对 RPN 输出的候选框,在共享特性图上做固定尺寸(如 7×7)的池化。
FC Head
:对每个 RoI 池化特性颠末两层全毗连后,分别输出种别概率和更精致的边框回归。
3、关键技能点
(1)区域建议网络(RPN)
滑动窗口与 Anchor
在特性图的每个位置,用大小(如 128²、256²、512² 像素)和比例(1:1、1:2、2:1)预定义 9 个 anchor。
每个 anchor 对应两个任务:对象/背景分类、4 个坐标偏移的边框回归。
共享特性
RPN 与后续检测头共享 backbone 提取的特性,制止重复计算。
RPN 损失
:第 i 个 anchor 预测为前景的概率;
:真实标签(前景=1/背景=0);
vs.
:预测与真实的边框偏移;
只对前景 anchor 计算回归损失。
(2)多任务联合训练
端到端优化
:RPN 与 Fast R-CNN 检测头可瓜代迭代训练,也可使用“近端微调”方式在一次网络中联合优化。
共享梯度
:RPN 的梯度会反向传至 backbone,检测头的梯度同样更新 backbone,共享特性更加顺应检测任务。
(3)RoI Pooling 与后端 Head
RoI Pooling
:将恣意尺寸的候选框映射到特性图后,以固定网格(一般为 7×7)做 max-pooling,输出尺寸一致的特性块。
FC Head
:两层全毗连后分出两个分支——分类分支(Softmax over K+1 类)与回归分支(每类 4 维偏移)。
4、训练与推理流程
(1)训练阶段
预训练 Backbone
:在 ImageNet 分类数据集上预训练。
训练 RPN
:在 detection 数据集上,仅微调 RPN 分支与 backbone,天生高质量 proposals。
训练检测头
:用 RPN 提供的 proposals 训练 Fast R-CNN Head,微调 backbone & FC Head。
迭代优化
:可瓜代重复上两步,使 RPN 与检测头协同进化,最终得到统一网络。
(2)推理阶段
整图卷积
:输入一次图像,得到特性图。
RPN 预测
:在特性图上滑窗,输出候选框及前景分数,颠末 NMS 筛选前 300–600 个 proposals。
RoI Pooling + FC Head
:对每个 proposal 池化并过 FC,输出最终种别分数与回归偏移,并再次做 NMS,输出最终检测效果。
5、优势与挑战
(1)长处
速率提升
:RPN 轻量高效,可达 5–7 FPS(ResNet-50),极大优于前代。
端到端训练
:检测网络完整一体,特性更具针对性;
高精度
:基于 anchor 的多尺度、多长宽比设计,对各种尺寸目标均表现精良。
(2)缺点
Anchor 设计依靠
:必要手动设定 anchor 尺度与比例,差别数据集需调参;
RoI Pooling 对齐误差
:离散量化导致精度损失,尤其小物体,后续 Mask R-CNN 引入 RoIAlign 予以改进;
训练复杂度
:RPN 与检测头的多阶段或瓜代训练流程较 Fast R-CNN 略繁琐。
6、后续演进
Mask R-CNN(2017)
用 RoIAlign 代替 RoI Pooling,消除量化误差;
在检测基础上增加实例分割分支。
RetinaNet(2017)
单阶段检测网络,引入 Focal Loss 处置惩罚正负样本极度不平衡题目。
Cascade R-CNN(2018)
多级检测头,逐级进步 IoU 阈值,增强高质量检测框性能。
DetectoRS、HTC、Sparse R-CNN…
持续在 backbone、proposal-free 设计、注意力机制等方面探索,推动检测性能与效率双提升。
五、YOLO
1、YOLO 概述
YOLO 系列模子由 Joseph Redmon 等人在 2016 年初次提出,其核生理念是将目标检测视为一个单一的回归题目——从整张图像直接回归出边界框坐标和种别概率,无需候选区域天生或后续分类器,因而具有极高的推理速率。自第一代 YOLO(YOLOv1)以来,YOLO 在速率与精度的权衡上持续改进,目前已发展到 YOLOv5、YOLOX、YOLOv7 乃至 Ultralytics 等多个分支。
2、基础网络结构(以 YOLOv1 为例)
YOLOv1 网络可分为三部门:
输入:整张 RGB 图像(例如 448×448)
│
24 层卷积 + 若干池化 → 特征图(7×7×1024)
│
卷积层降维(1×1 conv) → (7×7×B*(5+C))
│
重塑 → → S × S × (B×5 + C) 输出张量
复制代码
S×S 网格划分
将输入图像划分为 S×S(如 7×7)个网格,每个网格只预测 B(如 2)个边界框及对应置信度,以及 C(如 20)类的条件概率。
每个网格输出
边界框参数
:4 个坐标 (x,y,w,h),相对于网格单元归一化;
置信度
:
;
种别概率
:
,通过 Softmax 输出。
3、关键技能点
单阶段回归检测
与两阶段(R-CNN 系列)差别,YOLO 仅一次网络前向就直接预测边框与种别,制止重复特性计算,极大进步速率。
统一损失函数
通过对坐标、置信度、种别三部门加权求和,实现回归与分类的联合优化。
采用
和
调治正负样本损失权重。
多尺度预测
后续版本(YOLOv2、YOLOv3)在差别尺度上预测特性图(如 13×13、26×26、52×52),更好地检测大、中、小目标。
引入 Feature Pyramid Network(FPN)头脑,通过上采样与跳跃毗连融合多层特性。
Anchor 机制(YOLOv2 及之后)
为每个网格预定义 K 个 anchor(典型为 5),每个 anchor 预测偏移量,增强对差别长宽比目标的顺应性。
Anchor 尺度通过 k-means 聚类数据集标注框得到。
Darknet 主干网络
YOLOv2 引入 Darknet-19,YOLOv3 升级为 Darknet-53,均采用大量 3×3、1×1 卷积与残差毗连,分身速率与表达能力。
4、训练与推理流程
训练阶段
数据增强
:随机缩放、裁剪、翻转、色彩变换等,提升鲁棒性;
预训练
:先在 ImageNet 上预训练主干网络;
微调
:在 COCO 或 VOC 等检测数据集上微调全网权重;
学习率计谋
:采用阶梯衰减或余弦退火等动态调解。
推理阶段
输入预处置惩罚
:统一缩放到固定尺寸(如 416×416)并归一化;
单次前向
:网络输出多尺度或单尺度预测张量;
解码边框
:根据网格、anchor 与网络预测偏移,规复为原图坐标;
置信度过滤 & NMS
:剔除低置信度(如 <0.5)预测,按种别进行非极大值抑制,输出最终检测效果。
5、优缺点分析
长处
极高速率
:YOLOv3 在 GPU 上可达 45 FPS(416×416),恰当及时应用;
端到端训练
:无须外部候选框算法,框架简便;
统一回归
:检测与定位同框完成,模子紧凑。
缺点
定位精度较低
:尤其小目标与重叠目标,因网格划分粗糙导致漏检或定位毛病;
种别不平衡
:前背景样本差异大,YOLOX 等后续通过 Decoupled Head、SimOTA 计谋改进;
尺度泛化
:早期版本单尺度预测,对差别分辨率目标兼容性差。
6、后续演进与分支
YOLOv4 / YOLOv5
(2020)
引入 CSPDarknet、Mosaic 数据增强、CIoU Loss、SPP 模块、PANet 等技能,进一步提升精度与速率平衡。
YOLOX
(2021)
采用 anchor-free 设计,Decoupled Head、SimOTA 训练方案、EMA、SiLU 激活;
在 COCO 上取得 AP 50:50–95 达到 50+ 的水平。
YOLOv7 / YOLOv8
(2022–2023)
发布多项结构与训练本领创新,如 E-ELAN、Dynamic Head、自动混合精度;
Ultralytics YOLOv8 以 PyTorch 实现,接口友好并支持多任务(分类、检测、分割、分割跟踪)。
六、SSD
1、模子动机
SSD 于 2016 年由 Wei Liu 等人提出,旨在在保持较高检测精度的同时,实现真正的单阶段、单次前向检测。相比于两阶段方法(Faster R-CNN)和早期单阶段方法(YOLOv1/2):
两阶段
:精度高但慢;
YOLOv1
:速率快但对小目标、聚集目标精度不敷;
SSD
:引入多尺度特性图与多比例默认框(default boxes),在速率和精度间取得平衡。
2、网络团体结构
主干网络(Backbone)
通常选用 VGG16 (去掉最后的池化层和全毗连层)作为基础特性提取器。
在 conv4_3、fc7(通过 1×1+3×3 conv 将原 fc6/fc7 转为卷积层)等多层均保留特性。
附加特性层(Extra Feature Layers)
在 backbone 之后,依次添加多少卷积层(例如 conv8_2、conv9_2、…conv11_2),每层特性图分辨率依次减半。
例如 SSD300 在输入 300×300 时,依次产生 38×38、19×19、10×10、5×5、3×3、1×1 的特性图。
多尺度预测(Multi-scale Prediction)
每个特性图位置
天生多少个默认框(Default Boxes,也称 anchor):
差别宽高比(如 1:1、2:1、1:2、3:1、1:3);
差别尺度(结合当前层与下一层分辨率计算)。
并行预测
:在每个位置,通过 3×3 卷积同时输出种别得分分支(K+1 个通道)和边框偏移分支(4 个通道 × default boxes 数量)。
输出张量
将全部尺度、全部位置、全部默认框的预测拼接,形成一个统一的输出向量,然后进行后处置惩罚(置信度过滤+NMS)。
3、关键技能点
Default Boxes 的设计
在第 m 个尺度特性图(大小
)上,定义 k 个默认框;每个默认框对应特定的尺度
和一组长宽比
。
默认框中央与特性图网格中央对齐,尺度按公式
线性计算。
多尺度、多比例覆盖
差别层的差别分辨率、差别框比例,联合覆盖各类大小和形状的目标。
conv4_3 层对小目标敏感;更深层对大目标更具语义。
端到端多任务损失
:平滑 L1 损失,对预测框偏移与对应 ground-truth 回归;
:分类交织熵,对正负样本种别预测;
:指示默认框 i 与真实框 j 的匹配关系;
通过硬负例挖掘(Online Hard Example Mining)将负样本比例限定在正样本的 3 倍内,平衡训练。
硬负例挖掘
对全部未匹配正样本的默认框,按分类损失排序,挑选前
剩余框数
作为负样本,用于训练。
尺度归一化
对 conv4_3 层特性做 L2 正则化并乘以可学习缩放因子,以缓解浅层特性通道数较小、梯度流传不均的题目。
4、训练与推理流程
训练阶段
默认框与真实框匹配
:IoU ≥ 0.5 的默认框标为正样本;后者随机补足。
计算损失
:多任务损失按正负样本加权求和;
反向流传
:同时优化 backbone、附加层、输出分支;
数据增强
:随机裁剪、颜色抖动、翻转、缩放,进步模子鲁棒性。
推理阶段
单次前向
:输入整图(如 300×300)→ 特性图 → 并行预测;
解码偏移
:将网络学到的偏移还原到默认框,得到最终预测框坐标;
置信度过滤
:抛弃低于阈值(如 0.5)的预测;
NMS
:对每个种别执行非极大抑制,保留最高置信度的多少框。
5、性能与优缺点
模子输入尺寸PASCAL VOC07 mAPCOCO AP@[.5:.95]推理速率(FPS@Titan X)SSD300300×30077.5%23.2%~59SSD512512×51279.5%26.8%~22
长处
真正单阶段
:无外部 proposal,速率快;
多尺度特性融合
:对各大小目标均有较好覆盖;
端到端训练
:简朴统一的多任务优化。
缺点
小目标检测弱
:300×300 分辨率下,对极小目标仍旧不够敏感;
长尾样本不平衡
:种别不平衡需额外计谋;
依靠锚框设计
:手工设定尺度与比例,需针对数据集调优。
6、后续演进
DSSD(2017)
在 SSD 基础上加入多尺度 deconvolution 和扩张卷积,提升小目标检测精度。
RefineDet(2018)
两段式单阶段:先粗略筛选,然后精致定位并分类,结合了两阶段与单阶段长处。
RetinaNet(2017)
引入 Focal Loss,办理极度正负样本不平衡,AP 表现超越 SSD。
YOLO 系列进化
后缀如 YOLOv4/5/6/7 在 anchor-free、解耦头、SimOTA 等方面不断优化,进一步推动单阶段检测性能。
七、DETR
1、动机背景
传统目标检测框架(R-CNN 系列、SSD、YOLO 等)大多依靠先验框(anchor)或候选区天生,并通过 NMS(非极大值抑制)来去重,实现复杂且多阶段的流水线训练。DETR(End-to-End Object Detection with Transformers)由 Facebook AI Research 于 2020 年提出,首创将 Transformer 架构直接应用于目标检测,实现端到端、无锚框、无 NMS 的统一检测框架。
2、团体架构概览
输入图片 → Backbone CNN → Flatten+Position Embedding → Transformer Encoder
↓
Transformer Decoder (object queries)
↓
线性头:分类分支 + 边框回归分支
↓
Hungarian Matcher + Set Prediction Loss → 端到端优化
复制代码
Backbone CNN
通常使用 ResNet-50/101 等提取二维特性图(如 1/32 下采样尺寸的 C×H×W)。
位置编码与扁平化
将特性图扁平为长度为
的序列,并加上可学习的 2D 位置编码。
Transformer Encoder
多层自注意力(Multi-Head Self-Attention)+ 前馈网络,对图像特性进行全局上下文建模。
Transformer Decoder
预设 M 个
object queries
(可学习向量),每个 query 通过交织注意力(Cross-Attention)“查询”编码器输出,天生对一个目标的预测。
输出 Head
对每个 query 输出一个 (C+1)-维分类分数(包含背景类“无目标”)和一个 4 维边框坐标(归一化到 [0,1])。
集匹配损失(Set Prediction Loss)
采用匈牙利算法(Hungarian Matching)将 M 个预测与真实目标进行逐一匹配;
匹配后,对分类和回归损失进行加权求和,端到端反向流传,无需 NMS。
3、核心组件详解
(1)Object Queries
预定义 M 个长度为 d 的向量(如 M=100,d=256),并随训练学习;
每个 query 在 decoder 中与编码器特性做多轮交互,最终对应一个检测框或“空”(no object)。
(2)注意力机制
自注意力(Self-Attention)
:在 encoder/decoder 内部,建模各位置与各 query 之间的全局关系;
交织注意力(Cross-Attention)
:decoder 中,query 对编码器全部位置的加权聚合,学习“在哪里有物体”。
(3)位置编码(Positional Encoding)
将二维网格位置映射为与特性同维度的向量,并与特性相加;
保持空间位置信息,使注意力机制区分差别区域。
(4)匈牙利匹配(Hungarian Matching)
对 M 个预测与 K 个 ground-truth 目标,构建 M×K 的匹配本钱矩阵:
结合分类是否正确与边框回归误差,用匈牙利算法求最优逐一匹配对;
未匹配的预测被视为背景(种别损失只计算为“无目标”)。
(5)Set Prediction Loss
匹配后,对每对 (i,j) 预测与真实目标计算:
分类损失
:交织熵;
回归损失
:平滑
+ GIoU Loss(在 DETR 后续版本中引入)。
损失总和:
4、训练与推理流程
训练
将批量图像送入 backbone,提取特性并加位置编码;
编码器多层自注意力处置惩罚,得到全局特性表示;
decoder 交织注意力将 object queries 转化为 M 条预测;
匈牙利匹配,计算 set prediction loss;
端到端反向流传,更新 backbone、Transformer、object queries。
推理
单次前向得到 M 个分类分数与边框;
选取分类分数最高的前 N′ 条(如 top-100)非背景预测;
直接输出,无需 NMS。
5、优缺点对比
方面优势局限
简便性
端到端一体化,无需候选框、锚框、NMS 等繁琐步骤训练收敛慢,需大批量数据和更长训练
全局交互
Transformer 自注意力学习全局上下文,利于复杂场景下检测计算与内存开销高,尤其大分辨率/大特性图尺寸时
可扩展性
轻易结合多任务(如 Mask DETR、Deformable DETR、Conditional DETR 等)原始 DETR 在小目标检测、密集目标场景(人群、车流)效果欠佳
推理效率
无需 NMS,后处置惩罚简朴Transformer decoder 层数和 query 数量直接影响推理速率
6、后续改进与演进
Deformable DETR
引入可学习的可变形 attention,仅在多少关键位置采样特性,大幅加速收敛和推理。
Conditional DETR
将位置信息条件化注入 decoder 查询,增强查询与特性的对齐,加速训练收敛。
DN-DETR (Denoising DETR)
在训练中加入带噪声的查询与目标标签对,用“去噪”任务辅助收敛。
Mask-DETR
在 DETR 基础上加上实例分割分支,实现端到端的检测+分割。
Sparse DETR / Efficient DETR
通过稀疏化多头注意力或采用更轻量设计,低落计算量,提升推理速率。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4