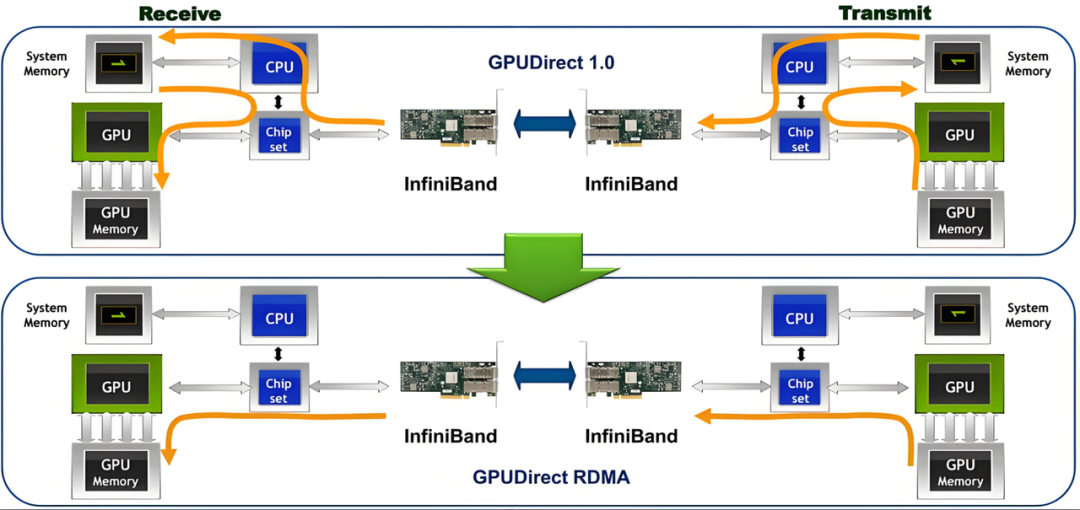
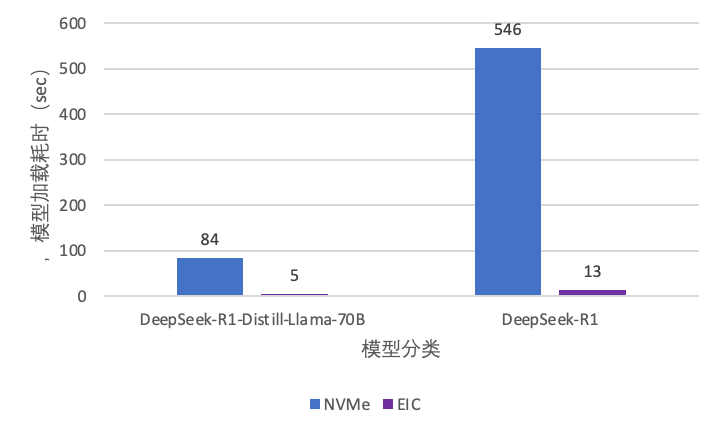
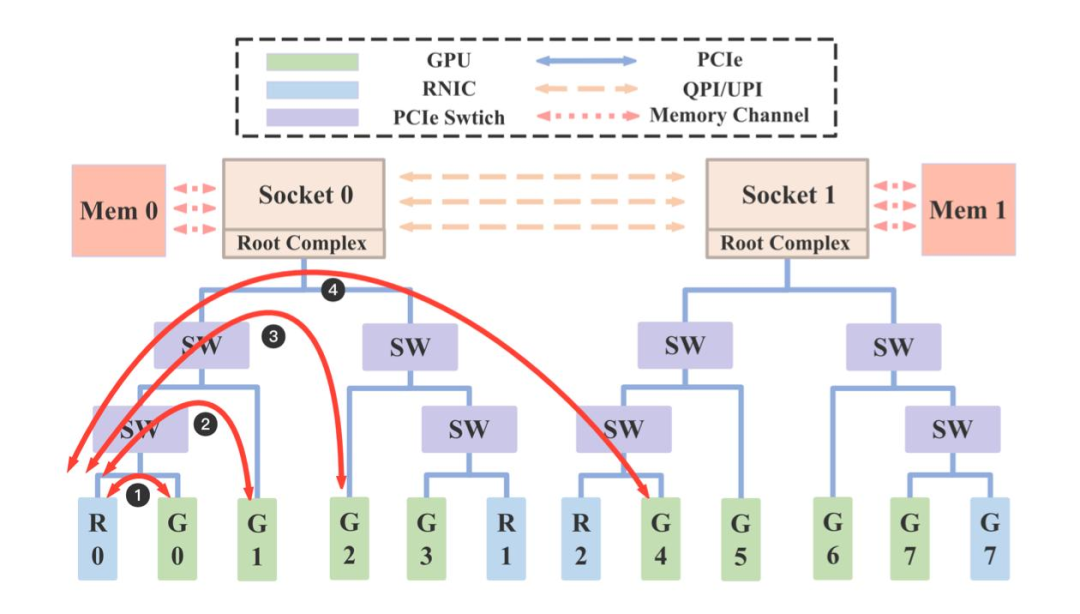
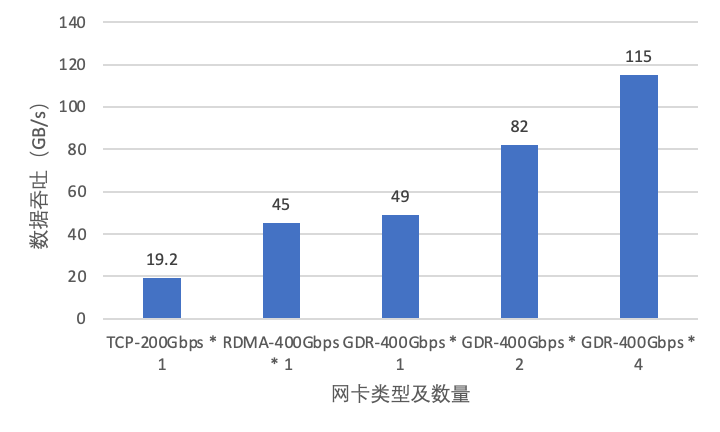
GPU Direct:GPU Direct 是 NVIDIA 开发的一项技术,可实现 GPU 与其他设备(例如网络接口卡 GPU Direct RDMA和存储设备 GPU Direct Storage)之间绕过 CPU 的直接通信和数据传输。该技术允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介,可以大概明显减少传输时延提高传输带宽,尤其适用于高吞吐、低耽误的 AI 推理场景。
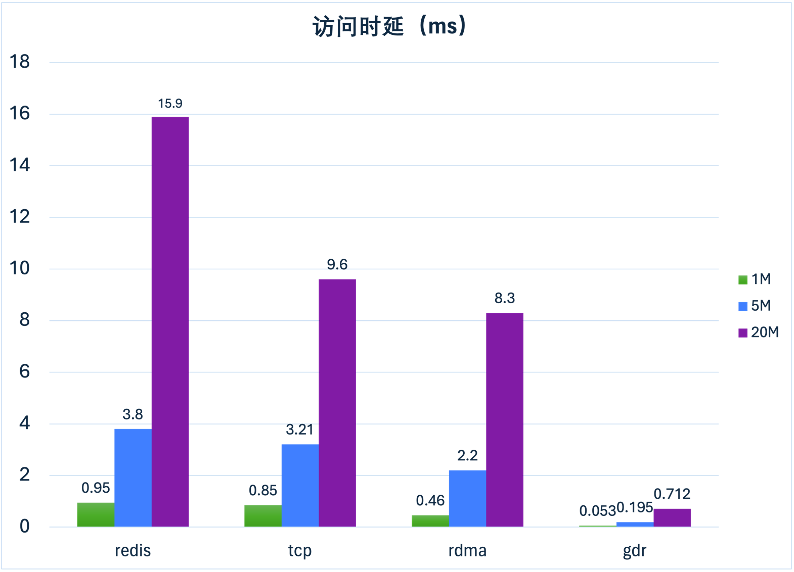
多协议兼容性:EIC 支持内核态TCP、用户态TCP、RDMA 及 GPU Direct RDMA 访问,适配各种硬件环境。