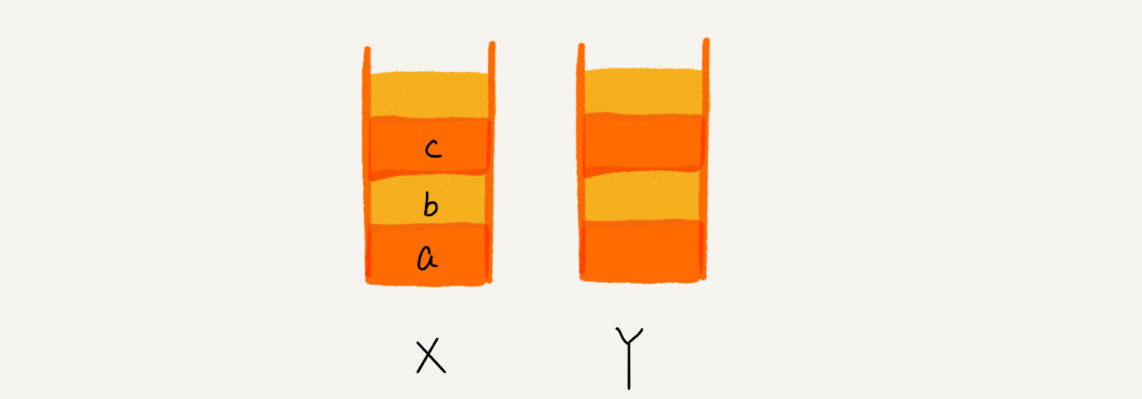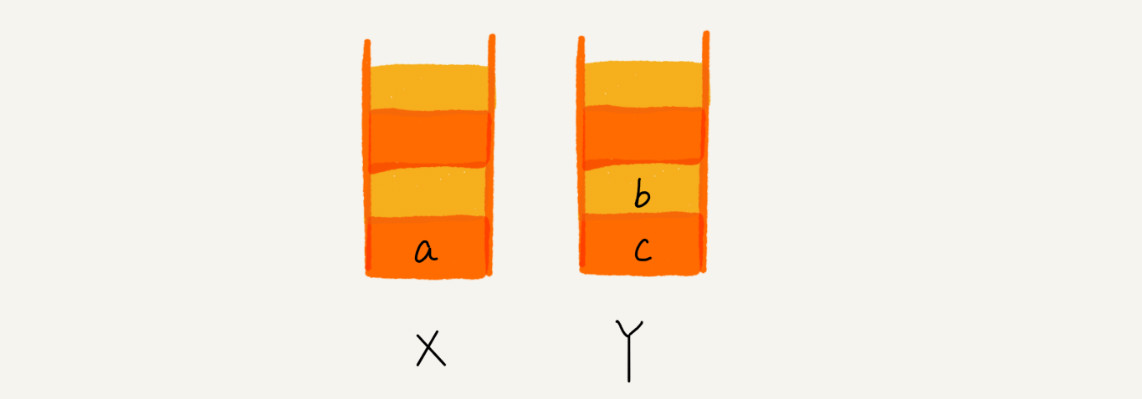qidao123.com技术社区-IT企服评测·应用市场
标题:
数据布局:栈和队列
[打印本页]
作者:
冬雨财经
时间:
5 天前
标题:
数据布局:栈和队列
目次
1. 栈:如何实现浏览器的进步和后退功能?
1.1. 如何理解“栈”?
1.2. 如何实现一个“栈”?
1.3. 栈在软件工程中的实际应用
1.3.1. 栈在函数调用中的应用
1.3.2. 栈在表达式求值中的应用
1.3.3. 栈在括号匹配中的应用
2. 队列:队列在线程池等有限资源池中的应用
2.1. 如何理解“队列”?
2.2. 如何实现一个“队列”?
2.3. 循环队列、阻塞队列和并发队列
2.3.1. 循环队列
2.3.2. 阻塞队列和并发队列
2.4. 栈和队列代码随想录
1. 栈:如何实现浏览器的进步和后退功能?
利用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。
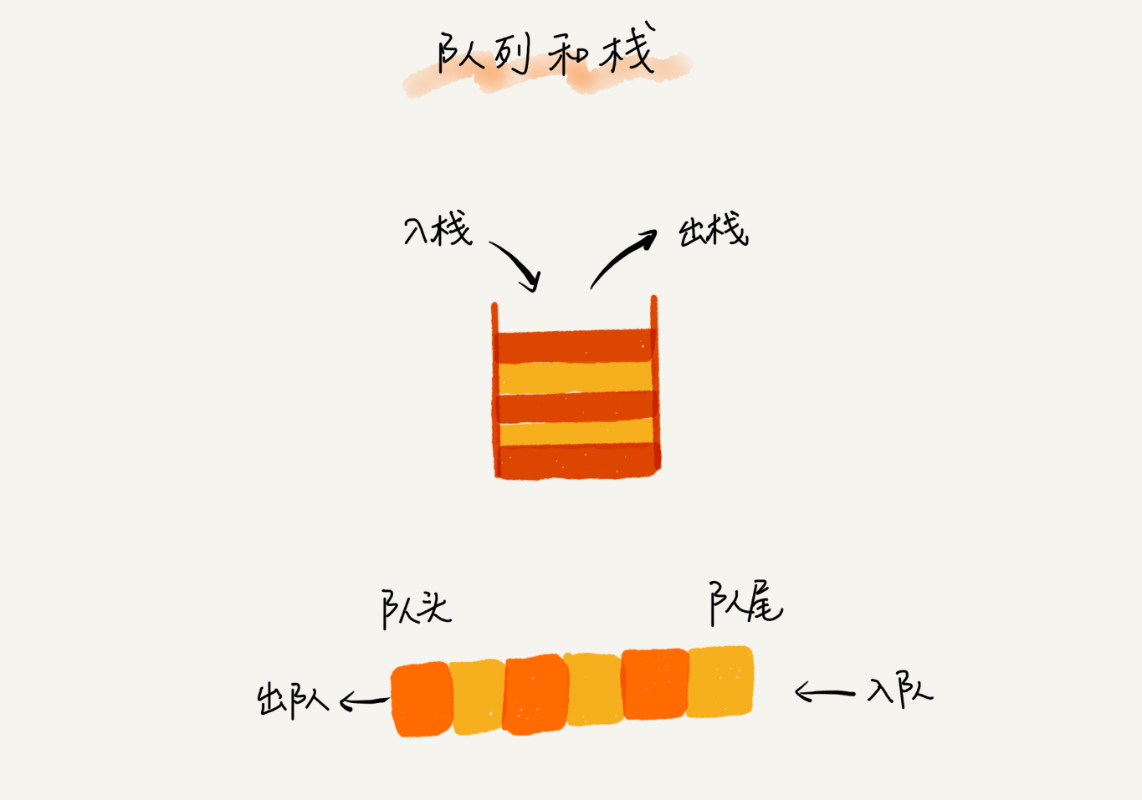
1.1. 如何理解“栈”?
后进者先出,先辈者后出
,这就是典范的“栈”布局。
从栈的操作特性上来看,
栈是一种“操作受限”的线性表
,只答应在一端插入和删除数据。
栈只支持两个基本操作:
入栈
push()和
出栈
pop()。
当某个数据集合只涉及在一端插入和删除数据,而且满足后进先出、先辈后出的特性,我们就应该首选“栈”这种数据布局。
1.2. 如何实现一个“栈”?
栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
在Python中,虽然我们可以很方便地利用collections模块中的deque类来实现栈的功能,但事实上,我们无需额外引入任何库就能实现一个栈。Python的标准库collections模块中的deque类是一个双端队列,它可以很方便地被转换为栈利用。
from collections import deque
class Stack:
def __init__(self):
self._stack = deque()
def push(self, item): # 元素入栈
self._stack.appendleft(item)
def pop(self): # 移除栈顶元素,并返回该元素的值。
return self._stack.popleft() if self._stack else None
def peek(self): # 返回栈顶的元素,但不会从栈中移除这个元素。
return self._stack[0] if self._stack else None
def is_empty(self): # 判断栈是否为空
return len(self._stack) == 0
def size(self): # 获取栈的大小
return len(self._stack)
复制代码
也可以
利用列表(List)来实现栈
功能。
class Mystack:
def __init__(self):
self.stack = []
def push(self, val):
self.stack.append(val)
def is_empty(self):
return len(self.stack) == 0
def peek(self):
return self.stack[-1] if not self.is_empty() else None
def pop(self):
return self.stack.pop() if self.stack else None
复制代码
1.3. 栈在软件工程中的实际应用
1.3.1. 栈在函数调用中的应用
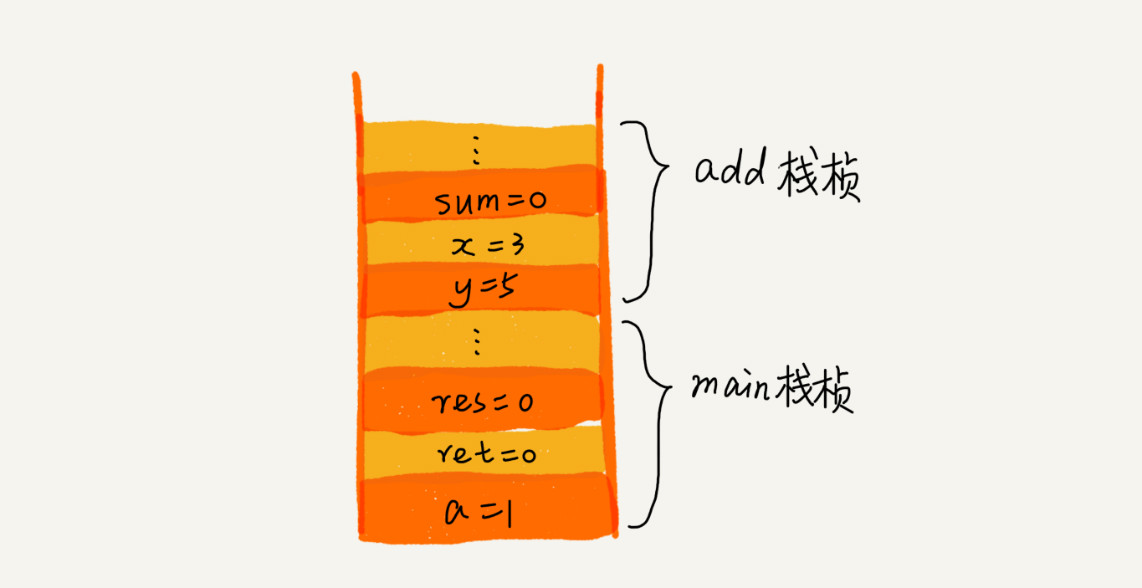
操作体系给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种布局, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
1.3.2. 栈在表达式求值中的应用
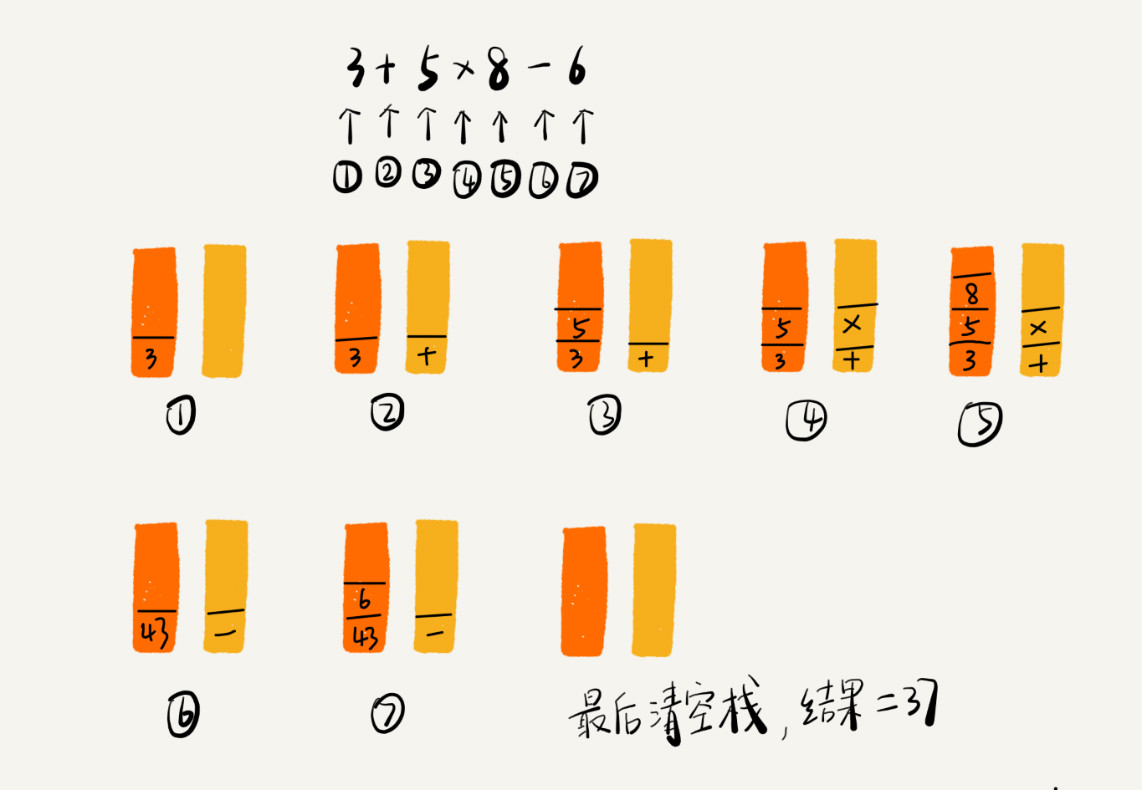
编译器通过两个栈来实现的。其中一个生存操作数的栈,另一个是生存运算符的栈。我们从左向右遍历表达式,当碰到数字,我们就直接压入操作数栈;当碰到运算符,就与运算符栈的栈顶元素举行比较。
假如比运算符栈顶元素的优先级高,就将当前运算符压入栈;假如比运算符栈顶元素的优先级低大概相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后举行盘算,再把盘算完的结果压入操作数栈,继续比较。
1.3.3. 栈在括号匹配中的应用
我们用栈来生存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。假如能够匹配,则继续扫描剩下的字符串。假如扫描的过程中,碰到不能配对的右括号,大概栈中没有数据,则说明为非法格式。
当所有的括号都扫描完成之后,假如栈为空,则说明字符串为正当格式;否则,说明有未匹配的左括号,为非法格式。
2. 队列:队列在线程池等有限资源池中的应用
实际上,对于大部分资源有限的场景,当没有空闲资源时,基本上都可以通过“队列”这种数据布局来实现请求排队。
2.1. 如何理解“队列”?
先辈者先出,这就是典范的“队列”。
最基本的操作有两个:
入队
enqueue(),放一个数据到队列尾部;
出队
dequeue(),从队列头部取一个元素。
队列跟栈一样,也是一种操作受限的线性表数据布局。
2.2. 如何实现一个“队列”?
deque 和 Python 的内置列表(list)在利用和功能上有着显着的区别,特别是在性能方面:
从两头添加或删除元素: 对于 deque,无论是从前端照旧后端添加或删除元素,时间复杂度都是 O(1)。列表在尾部添加或删除元素(利用 append 和 pop)的服从也很高(O(1)),但在列表的开头插入或删除元素(如利用 insert(0, value) 或 pop(0))时,性能会显著下降,因为这涉及到移动列表中的所有其他元素,时间复杂度为 O(n),其中 n 是列表的长度。
内存服从: deque 在内存利用上通常比列表更加高效,因为它在两头的操作淘汰了内存重新分配的次数。列表在到达其容量极限时需要举行整体的内存重新分配,而
deque 则通过一个链表的情势
分散存储,每次内存分配影响的范围较小。
deque 是办理需要频仍修改两头元素的问题的理想选择,而列表则更得当那些重要举行尾部操作和顺序访问的任务。
from collections import deque
# 创建一个空队列
queue = deque()
# 向队尾添加元素
queue.append('a')
queue.append('b')
queue.append('c')
print("队列状态:", queue) # 输出: 队列状态: deque(['a', 'b', 'c'])
# 从队首移除元素
first_element = queue.popleft()
print("移除的元素:", first_element) # 输出: 移除的元素: a
print("队列状态:", queue) # 输出: 队列状态: deque(['b', 'c'])
# 查看队首元素(不移除)
front_element = queue[0]
print("队首元素:", front_element) # 输出: 队首元素: b
# 检查队列是否为空
is_empty = len(queue) == 0
print("队列是否为空:", is_empty) # 输出: 队列是否为空: False
# 获取队列大小
size = len(queue)
print("队列大小:", size) # 输出: 队列大小: 2
复制代码
一些队列的
常用函数
可选参数maxlen,限定队列容量
# 创建一个最大长度为 3 的 deque
d = deque([1, 2, 3], maxlen=3)
# 当尝试添加更多元素时,最旧的元素将被自动移除
d.append(4) # deque([2, 3, 4])
d.appendleft(1) # deque([1, 2, 3])
复制代码
非常得当于需要限定容量的应用场景,如
缓存机制
或最近利用的项目(LRU)缓存。当只需要跟踪最新的几个项目时,利用 maxlen 可以自动维护 deque 的大小,避免手动删除老旧元素的复杂性。
添加和删除元素
from collections import deque
d = deque([1, 2, 3])
d.append(4) # 在右端添加元素
print(d) # 输出: deque([1, 2, 3, 4])
d.appendleft(0) # 在左端添加元素
print(d) # 输出: deque([0, 1, 2, 3, 4])
last_item = d.pop() # 移除并返回右端元素
print(last_item) # 输出: 4
print(d) # 输出: deque([0, 1, 2, 3])
first_item = d.popleft() # 移除并返回左端元素
print(first_item) # 输出: 0
print(d) # 输出: deque([1, 2, 3])
复制代码
访问元素和切片操作
from collections import deque
d = deque([0, 1, 2, 3, 4])
# 访问第一个元素
print(d[0]) # 输出: 0
# 访问最后一个元素
print(d[-1]) # 输出: 4
复制代码
尽管这种访问方式在语法上很直接,但需要留意的是,deque 中元素的随机访问不如列表高效,特别是在 deque 很大时。这是因为
deque 是用链表实现的,链表的随机访问性能相比于数组来说较差
。
# 将 deque 转换为列表进行切片
d_list = list(d)
print(d_list[0:3]) # 输出: [0, 1, 2]
# 使用 itertools.islice 进行切片
from itertools import islice
slice_result = islice(d, 0, 3)
print(list(slice_result)) # 输出: [0, 1, 2]
复制代码
与列表不同,deque 并不直接支持切片操作,即不能直接利用切片语法如 d[0:3] 来获取 deque 的一部分。假如需要执行切片操作,可以先将 deque 转换为列表,再举行切片,大概利用 itertools.islice 实现更高效的切片。
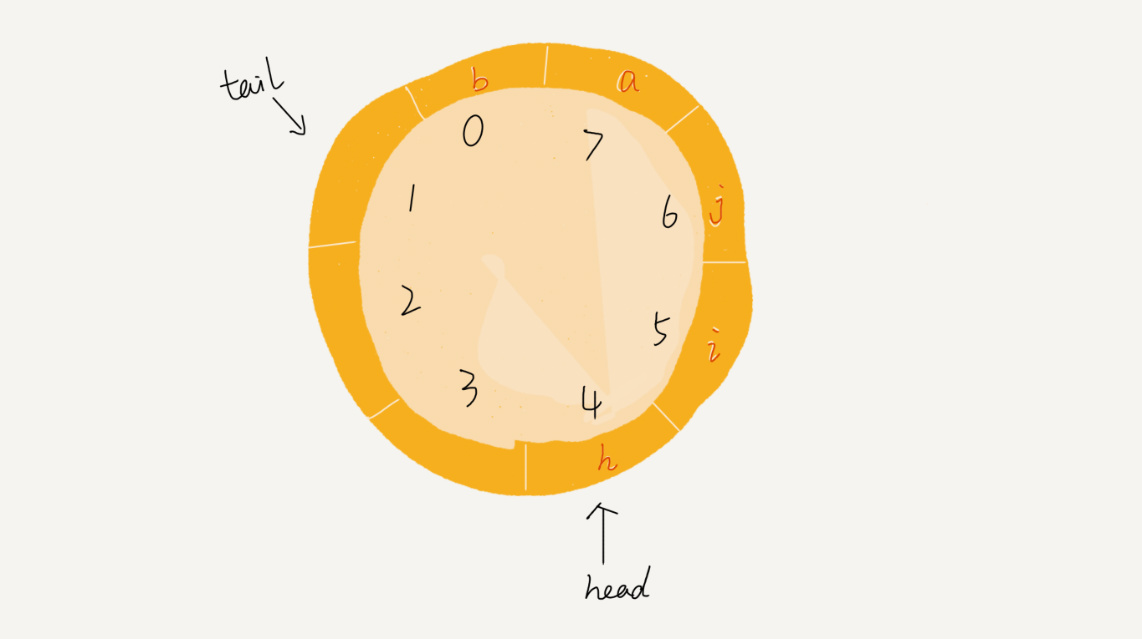
2.3. 循环队列、阻塞队列和并发队列
2.3.1. 循环队列
用数组来实现队列
的时候,在 tail==n 时,会有数据搬移操作,这样入队操作性能就会受到影响。可以用循环队列来避免数据搬运。
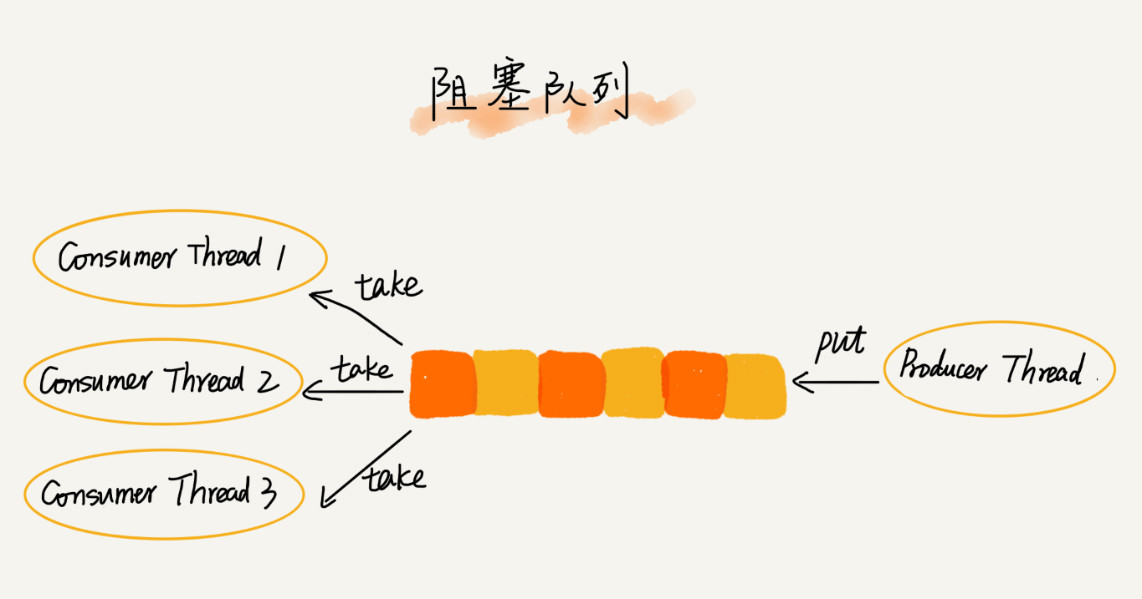
2.3.2. 阻塞队列和并发队列
阻塞队列
其实就是在队列底子上增加了阻塞操作。简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才华返回;假如队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
这种基于阻塞队列实现的“生产者 - 消费者模型”,可以有用地协调生产和消费的速度。当“生产者”生产数据的速度过快,“消费者”来不及消费时,存储数据的队列很快就会满了。这个时候,生产者就阻塞等候,直到“消费者”消费了数据,“生产者”才会被叫醒继续“生产”。
线程安全的队列我们叫作
并发队列
。最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时候仅答应一个存大概取操作。实际上,
基于数组的循环队列
,利用 CAS 原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的缘故原由。
2.4. 栈和队列代码随想录
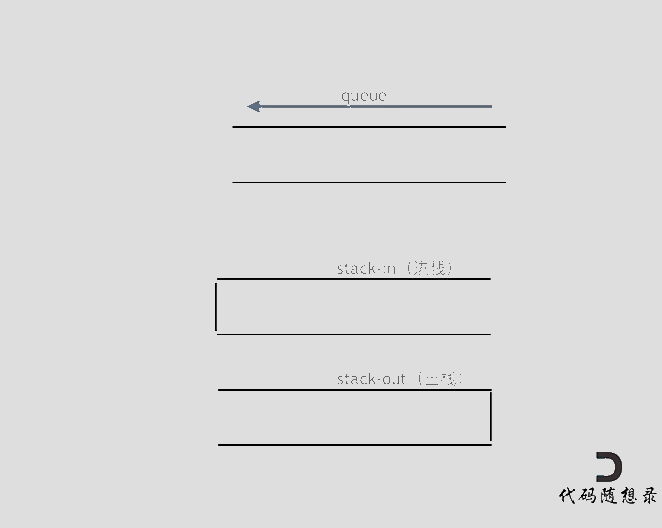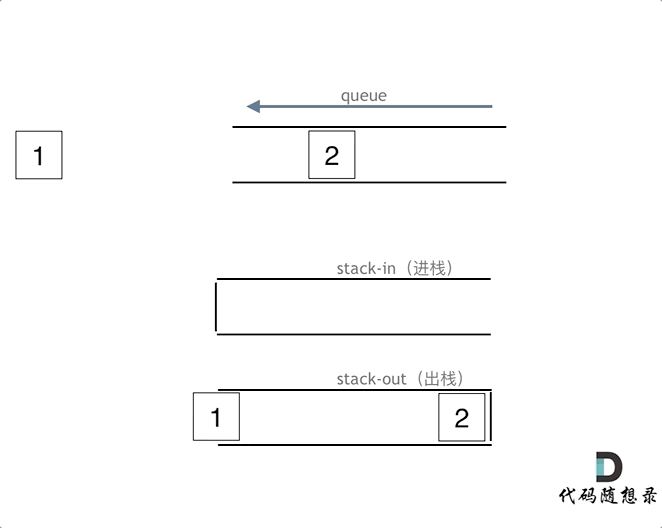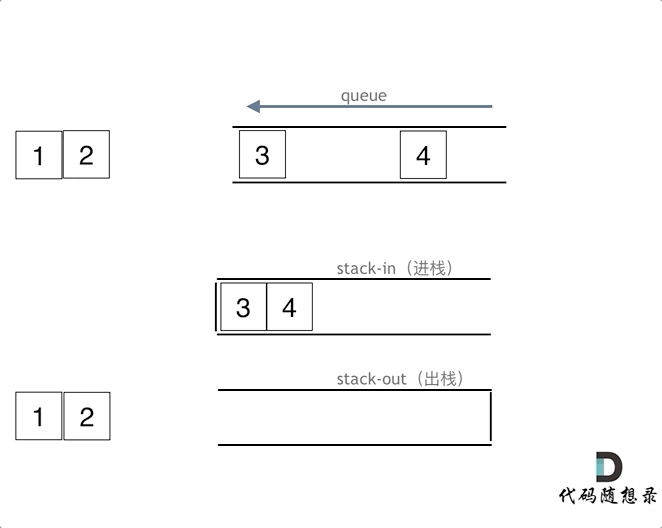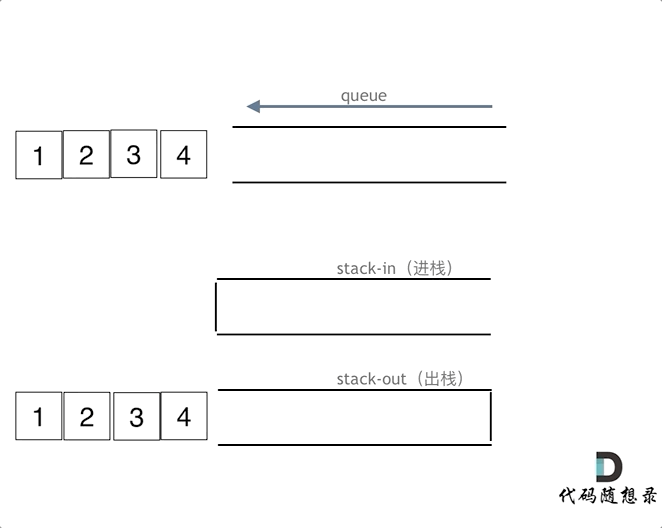
1. 232.用栈实现队列
用两个栈来实现队列的功能
且这里要留意函数的复用原则,可以使代码具有更高的可维护性
2. 用队列实现栈
用一个队列可以实现栈的功能,即将队尾之前的元素弹出之后全部加至队尾之后便可以实现栈的pop与peek功能
3. 有用的括号
三种不匹配的情况
已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false。
遍历字符串匹配的过程中,发现栈里没有要匹配的字符。所以return false
遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号return false。
4. 删除字符串中的所有相邻重复项
利用栈功能实现
5. 150. 逆波兰表达式求值
利用栈来办理
利用字典使代码更加简洁
op_map = {'+': add, '-': sub, '*': mul, '/': div}
复制代码
留意python中的//对于符号不相同的是向下取整(-9 // 5 = -2),可以用int(-9/5) = 1来办理这个问题
6. 239. 滑动窗口最大值
单调队列的实现方法,可以先封装单调队列类再利用
队列没有必要维护窗口里的所有元素,只需要维护有可能成为窗口里最大值的元素就可以了,同时保证队列里的元素数值是由大到小的。
7. 347.前 K 个高频元素
利用小顶堆来实现
利用字典来记录每个值出现的次数,这里初始化字典的时候要用到
from collections import defaultdict
time_dict = defaultdict(int)
复制代码
可以利用更高效的python内置函数
from collections import Counter
from typing import List
class Solution:
def topKFrequent(self, nums: List[int], k: int) -> List[int]:
# 使用Counter统计各元素的频率
freq = Counter(nums)
# 利用most_common方法获取前k高频的元素,并提取它们的值
return [item[0] for item in freq.most_common(k)]
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4