
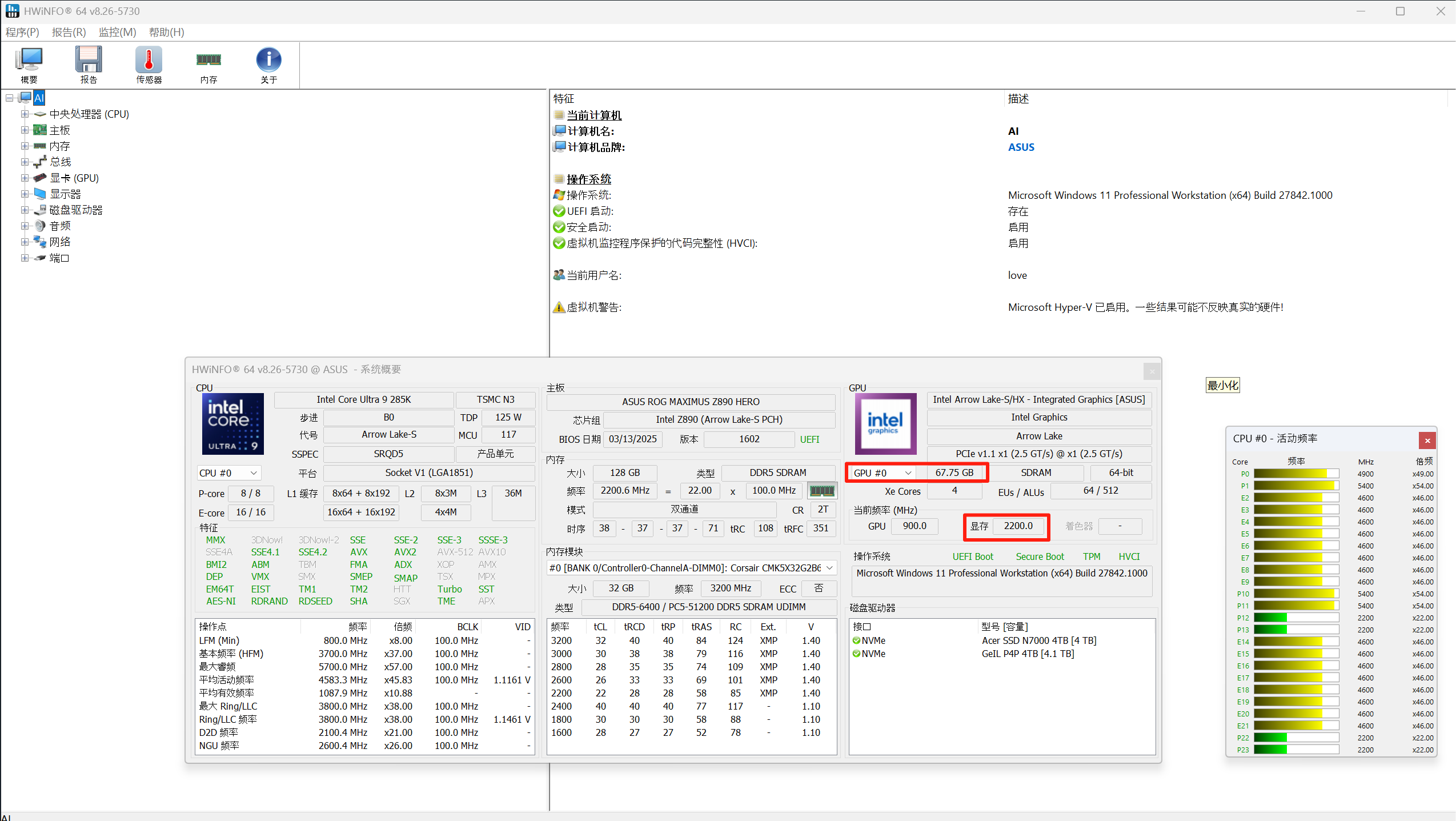
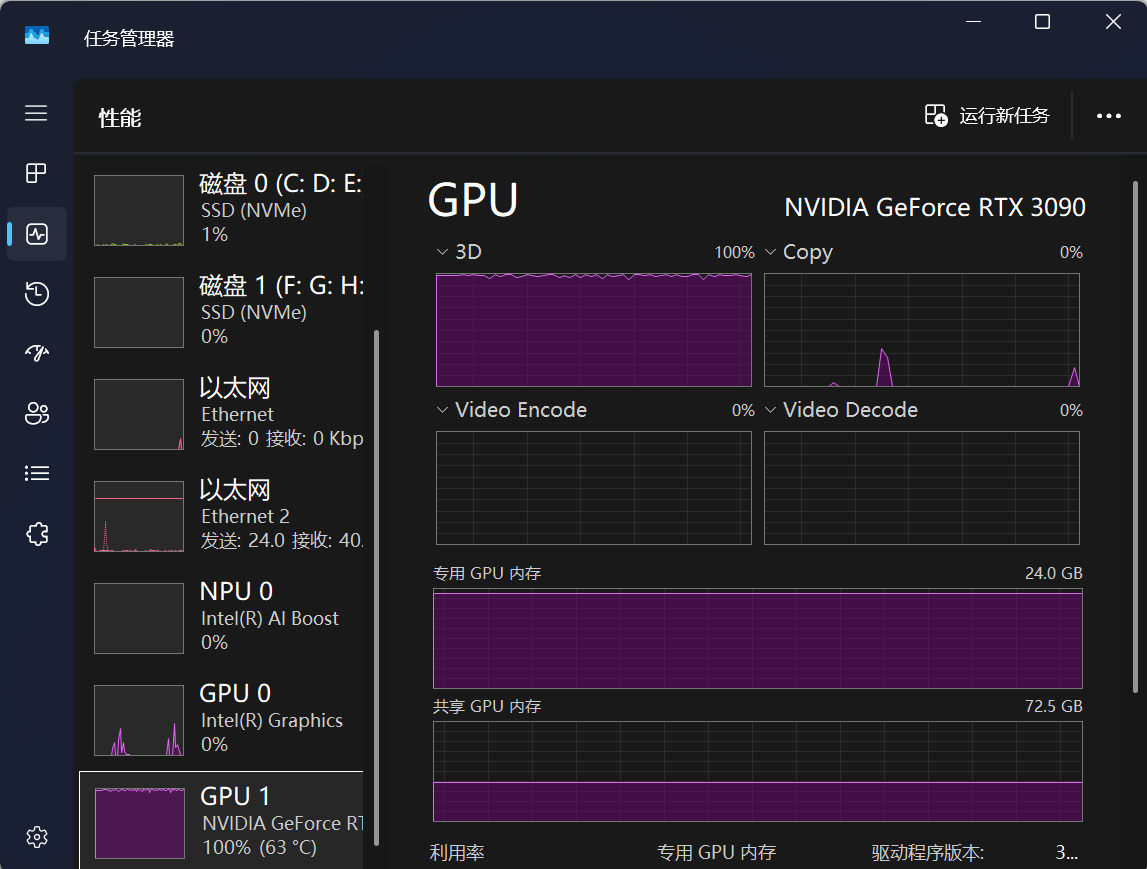
| 类型 | 核心架构优化方向 | 显存设置特点 | 驱动支持重点 |
| 专业卡 | 图形渲染精度、API 兼容性 | 高容量显存(如 32GB GDDR6) | 支持 OpenGL/DirectX 专业图形接口 |
| 游戏卡 | 实时图形渲染速度 | 中高容量显存(8-24GB GDDR6) | 偏重游戏引擎优化 |
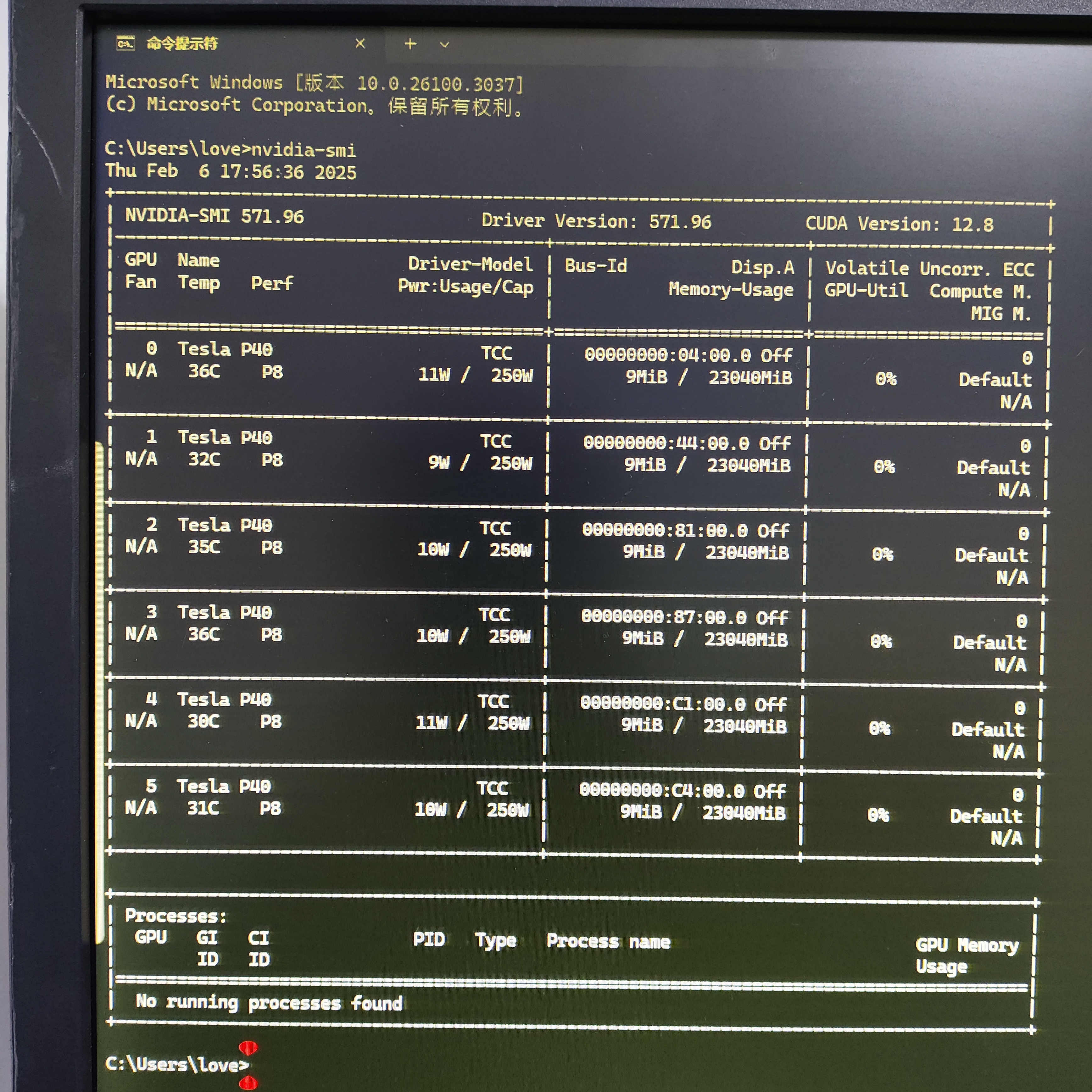
| 计算卡 | 并行计算效率、双精度浮点 | 超大容量显存(如 A100 的 80GB HBM3) | 深度优化 CUDA/ROCm 计算框架 |

| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |