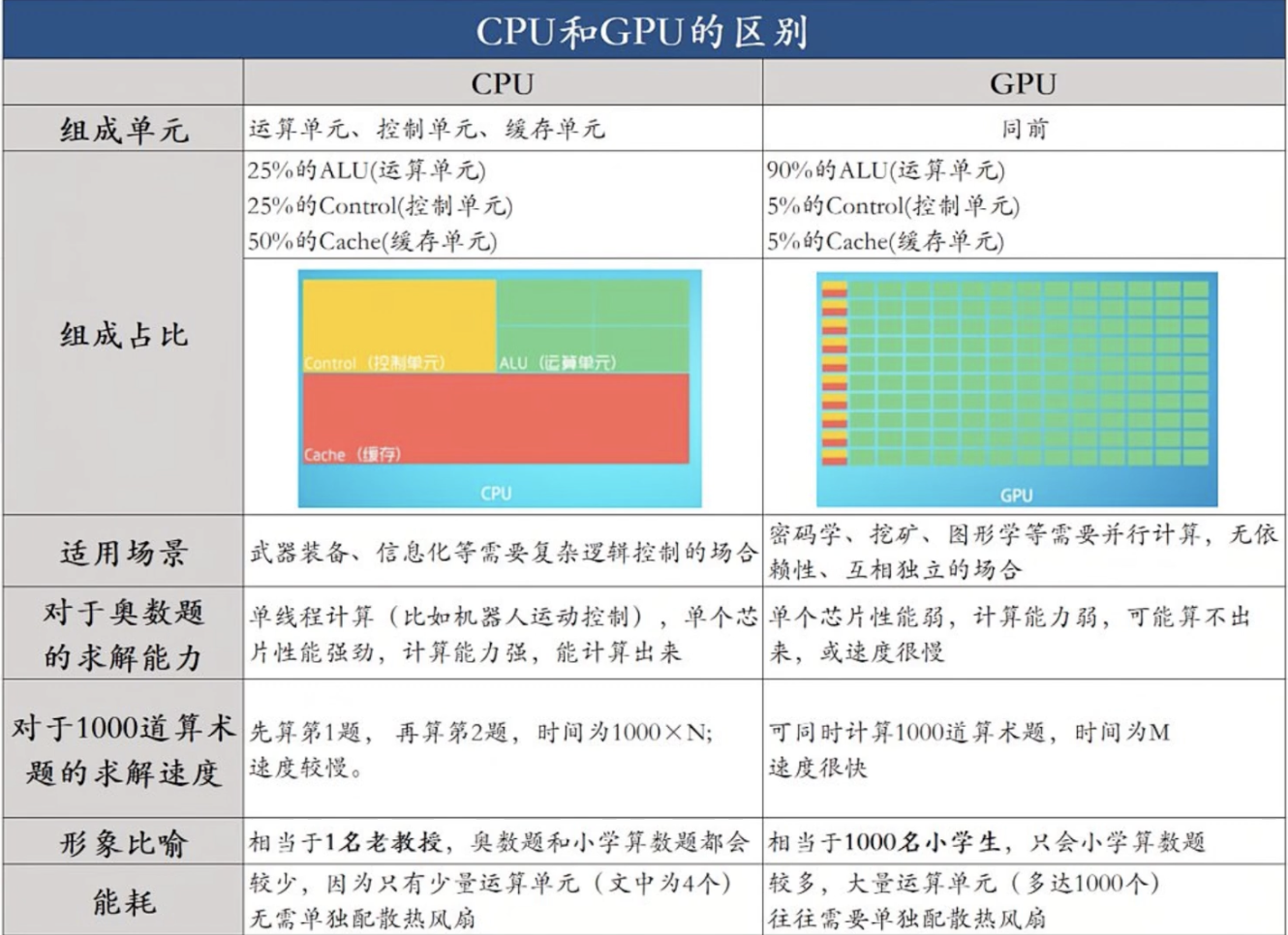
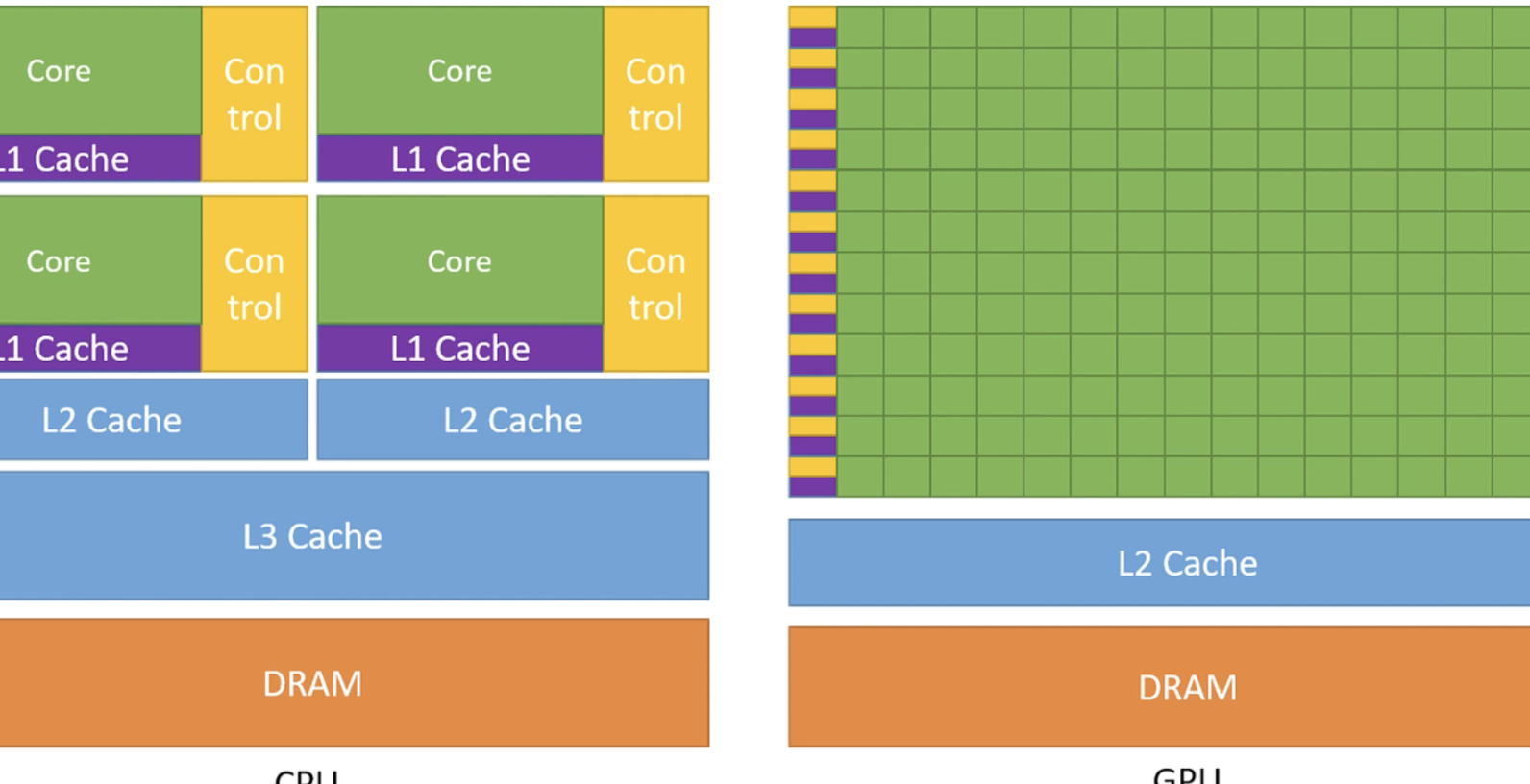
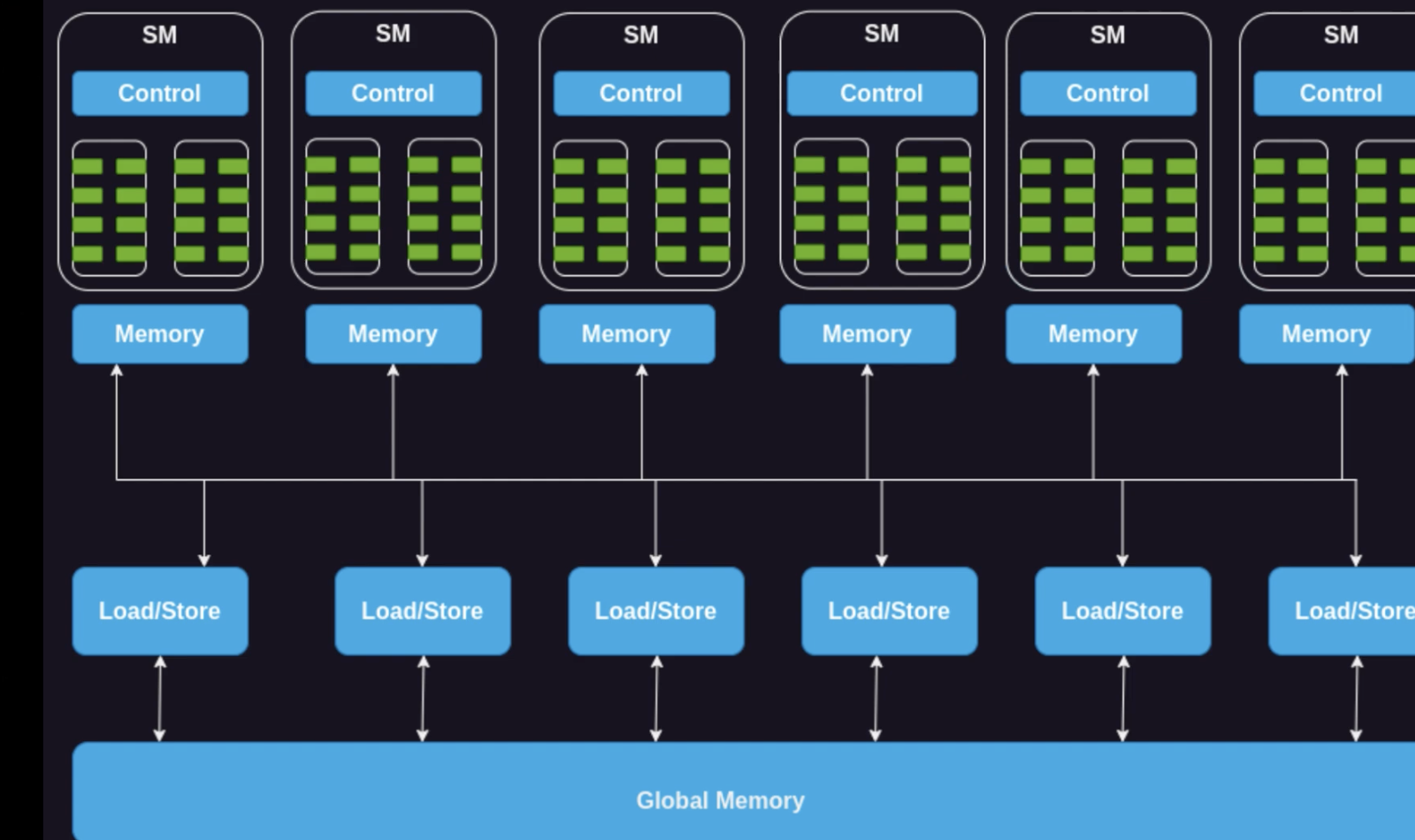
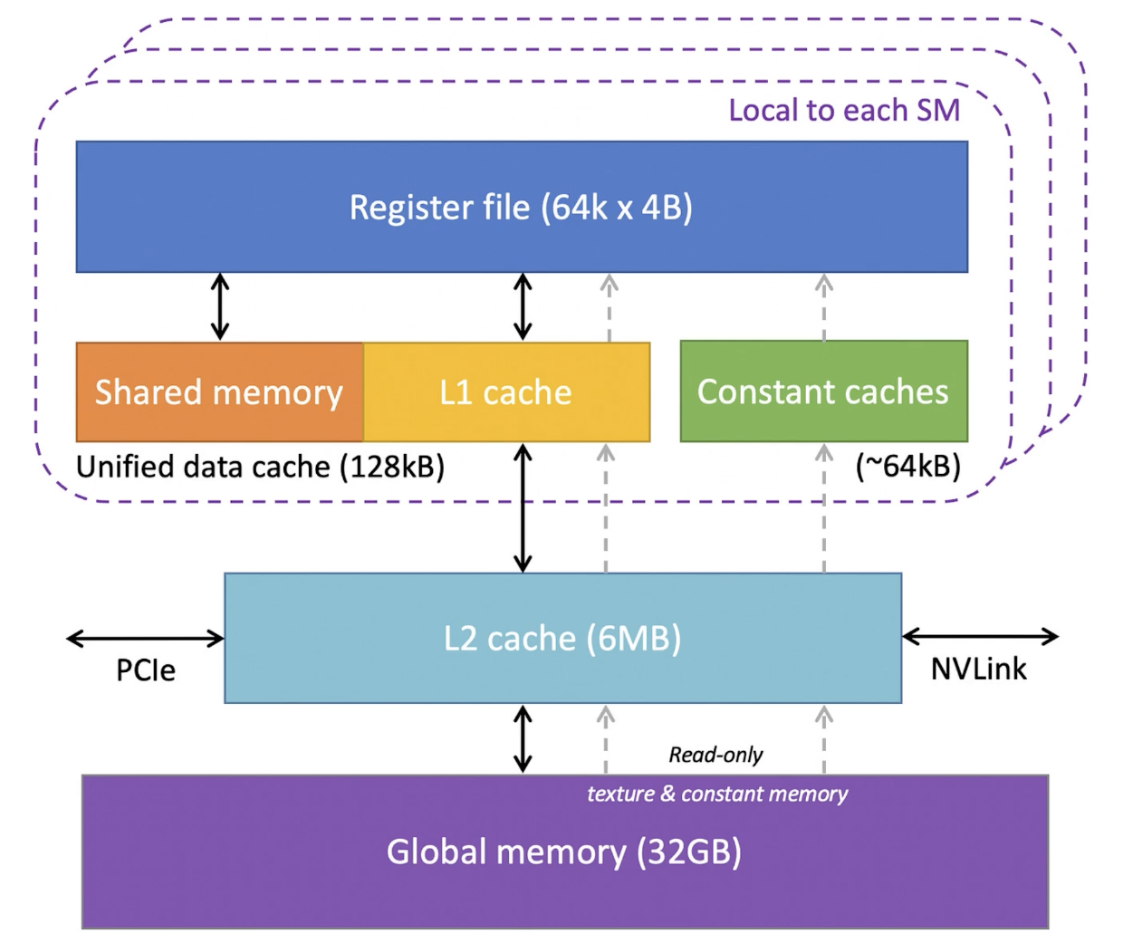
数据传输: 首先,Kernel 必要处理的数据必须从 CPU(主机)内存传输到 GPU 的全局内存(装备内存)。(注:较新的硬件和 CUDA 版本支持统一虚拟内存,可以在一定水平上简化这一步骤,允许 GPU 直接访问主机内存)。
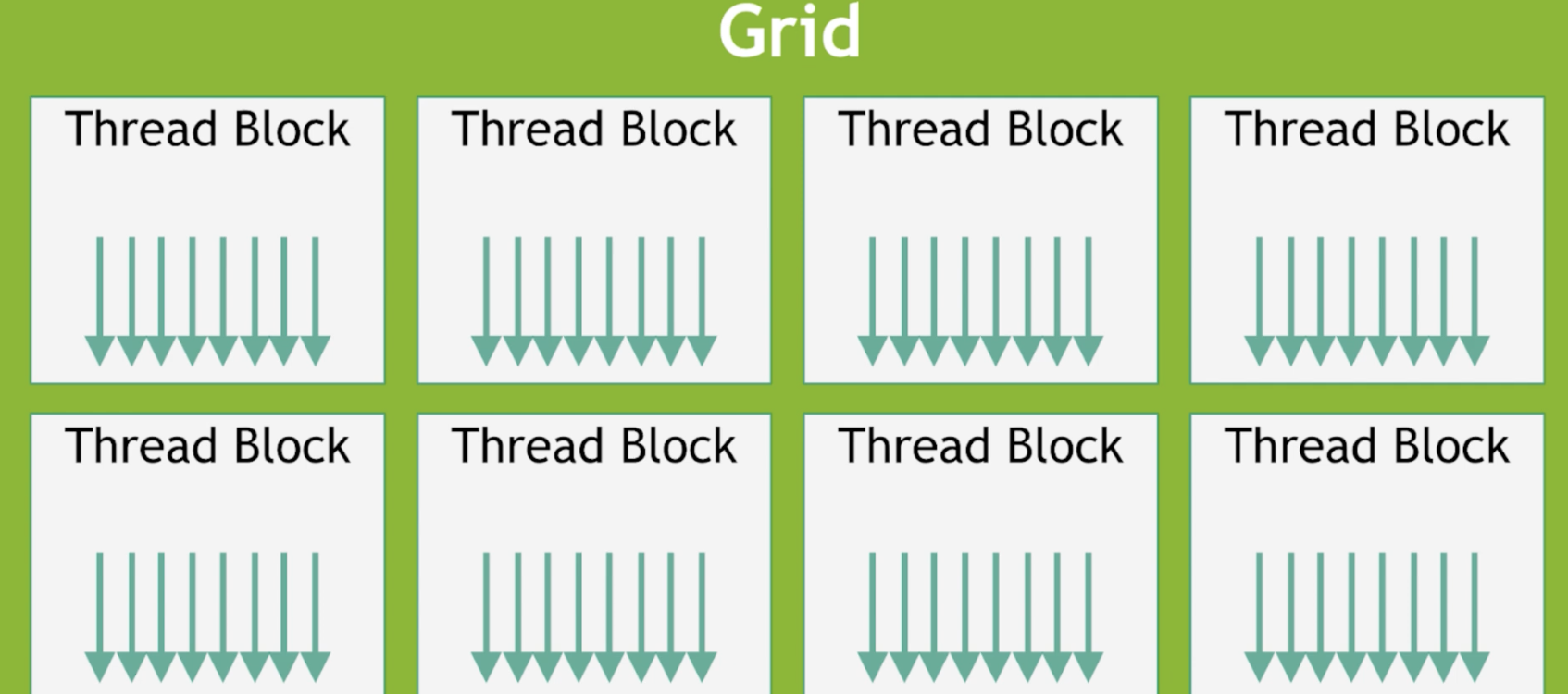
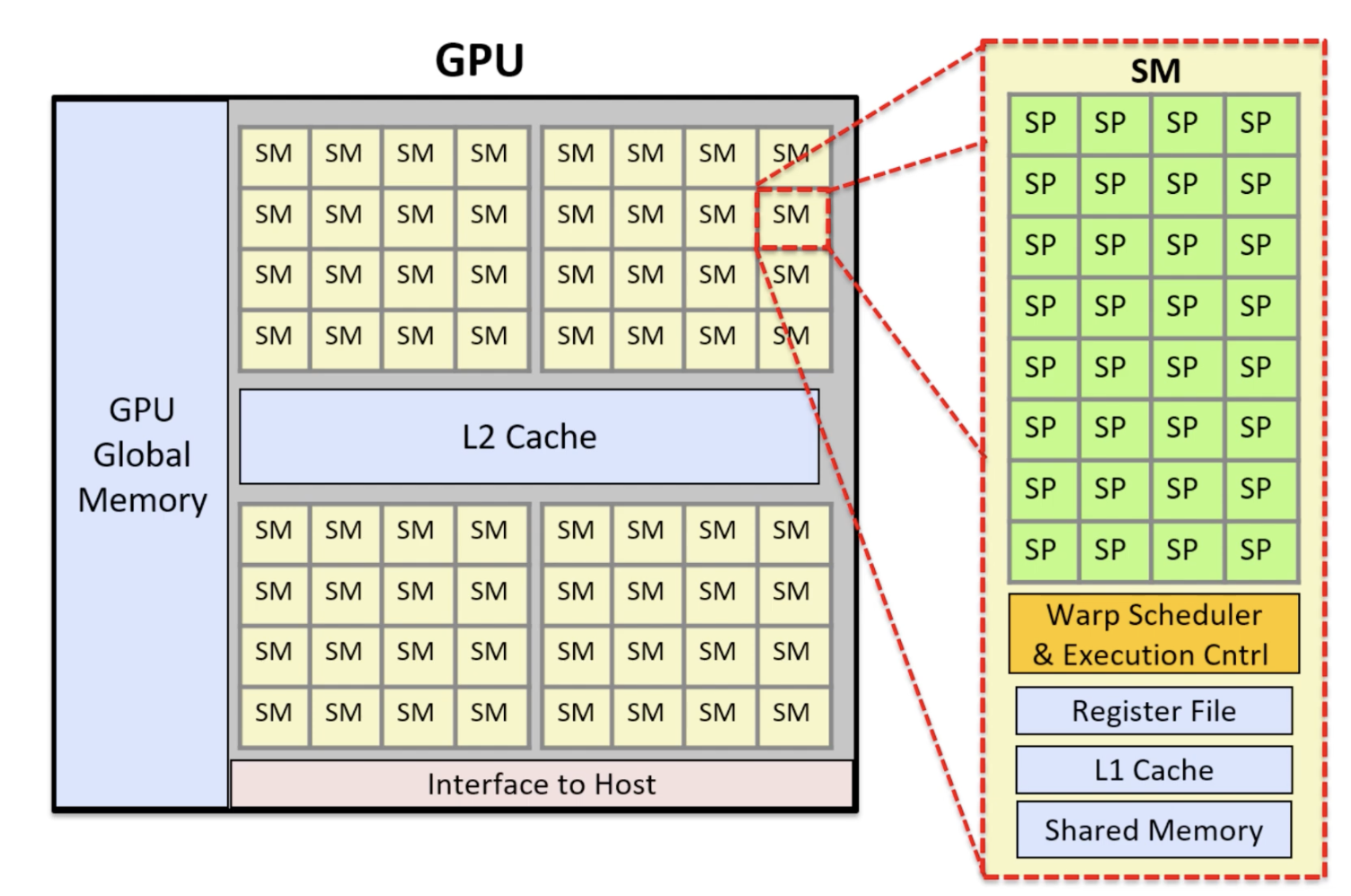
线程块分配到SM: 数据准备好后,GPU 会将线程块分配给 SM 进行处理。GPU 内部有一个硬件调度器,负责将待实行的线程块分配给空闲的 SM。同一个线程块内的所有线程保证被调度到同一个 SM 上实行,这样它们才气使用共享内存进行协作和同步。由于 SM 数量有限,如果 Kernel 包含大量线程块,它们会排队期待分配。当一个线程块实行完毕,SM 开释资源,调度器就会从队列中选择下一个线程块进行实行。