qidao123.com技术社区-IT企服评测·应用市场
标题:
携手北京大学,MindSpore+openEuler打造支持vLLM的DeepSeek全栈开源推理方案
[打印本页]
作者:
滴水恩情
时间:
3 天前
标题:
携手北京大学,MindSpore+openEuler打造支持vLLM的DeepSeek全栈开源推理方案
2025年,以DeepSeek-R1为代表的AI大模型正以惊人的速率重塑产业格局。短短7天用户破亿、多模态交互与低算力需求突破硬件限定,这些成就印证了AI技术走向规模落地的临界点已至。然而,将AI融入到详细产业,还面临着一些题目:
从产业上看:
1、
算力与模型的割裂
:厂商需为差异硬件重复适配模型,开辟成本陡增;
2、
生态孤岛化
:各厂商自建技术栈,导致跨平台协作效率低下;
3、
长尾需求难满足
:中小开辟者受限于算力与框架兼容性,难以复用头部模型能力。
从技术上看:
1、
混合专家(
MoE)架构的适配性挑战
:专家模型与硬件内存存在匹配困境,同时专家负载不均与通信开销过高;
2、
多模型协同与训推一体的体系挑战
:多模型动态交互、训推状态切换、资源动态分配引发协同困难,训推一体化软件栈的易用性不足;
3、
长序列推理与希奇计算的性能挑战
:长序列KV Cache存在容量瓶颈;希奇计算引发的向量化效率降落。
DeepSeek引发的挑战,本质上是AI规模化落地的必经之痛。解决这些难题需硬件厂商、框架开辟者与行业用户深度协同,通过
全栈开放生态共建
与
分层协同性能提升
,实现从单点突破到体系级效能跃迁。
# 01
全栈开放生态共建
北京大学联合OpenAtom openEuler(简称"openEuler") 开源社区与MindSpore社区
,推出头向大模型的全栈开源方案,以
操作体系+AI框架+模型生态
的三层开放架构,更换
操作体系
和
DL框架
,秉承
代码开源+标准开放+生态共建
的理念,逐步成为智能期间的全国产化的数字基座。
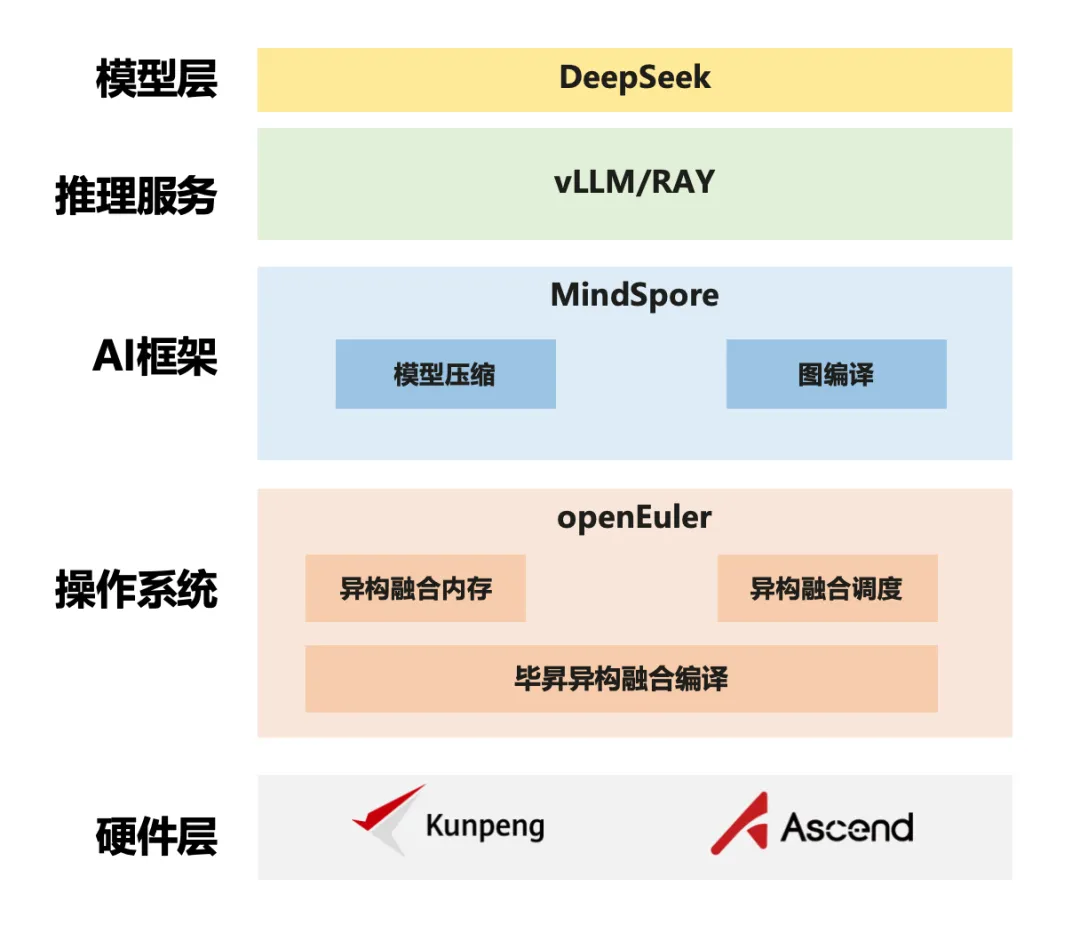
openEuler + MindSpore + vLLM/RAY全栈开源架构
1
对上:兼容多元大模型生态,普惠AI
支持DeepSeek、LLaMA系列等主流模型接入,通过归一化的开源推理软件栈,保证差异模型对资源的动态调配,在生态上做到同一演进,且开箱即优,制止“重复造轮子”;
集成模型微调与蒸馏能力,优化增强RAG流程搭建,联合DeepSeek群体计谋优化履历,低落长尾场景定制门槛。
2
对下:异构算力无缝接入,AI基座
通过硬件抽象层兼容GPU、NPU及国产芯片,释放DeepSeek低能耗技术红利;
在极致资源束缚下,资源动态调理诉求强烈,通过全栈协同优化低落模型资源消耗获得竞争优势。
# 02
分层协同性能提升
通过openEuler、MindSpore与vLLM/RAY间的分层协同,为DeepSeek-R1大模型带来了吞吐性能与易用性的明显提升。核心技术点如下:
1
openEuler
异构融合调理:负载感知MoE冷热专家,使命细粒度调理提升推理性能
负载感知的冷热MoE专家动态识别和并行调理,希奇MoE计算分层细粒度拆分到差异进程部署在多样算力;
共享资源细粒度按需控制,支持MoE专家均衡调理,计算/通信细粒度并发;
针对高并发场景下推理服务、分布式计算组件Host侧资源争用的痛点,使用NUMA感知的细粒度算力与内存资源隔离,提升推理整体性能。
异构融合内存:高效管理异构内存,减小体系内存碎片,提升体系推理性能
针对推理服务高并发场景,通过线程特性感知的细粒度内存分配、高性能代码段大页机制,在控制内存开销的同时,提升Host侧性能与整体推理吞吐;
针对MoE架构的希奇访存特征,通过Host/Device协同内存管理实现多粒度动态混合页与按需内存分配,减少页表访存开销同时提升显存使用效率;
针对大模型推理服务面临的显存容量挑战,基于MoE架构的希奇计算特征,使用运行时-OS协同设计实现高效专家超分部署,提升显存使用率与整体推理吞吐。
异构融合编译:毕昇编译优化,减少算子下发耗时,提升算子性能
架构亲和编译优化
:通过架构亲和的原子指令优化和Malloc、Memcpy高性能库优化,低落各类锁的代价,提高内存使用效率,低落访存开销,进而低落时延,提高吞吐率;算子编译阶段使能智能感知流水优化,基于数据依靠关系深度分析和自适应同步决议机制,主动插入最优同步指令实现高效的多级流水并行;通过昇腾算子抽象层与芯片ISA的智能映射,实现指令级并行优化,极大发挥芯片理论算力;
多维融合
编译
优化
:针对算子下发阶段前端性能瓶颈较高的特点,通过CFGO优化技术,借助运行时信息,编译器进行精准的代码布局优化,有用提高程序IPC,低落算子下发时延;多维融合加速可以或许主动实现向量类算子融合、矩阵-向量类算子融合,减少数据搬运开销,并通过细粒度并行进一步提升算子性能,快速满足用户验证模型算法和提升模型开箱性能。
2
MindSpore
图编译:将模型编译为计算图,通过模式匹配主动将小算子融为大算子
图天生
:MindSpore通过JIT编译主动将模型的python类大概函数编译成一张完整的计算图,JIT编译提供了多种方式(ast/bytecode/trace)以满足差异场景的用途,覆盖了绝大部分Python语法。
主动融合
:基于计算图通过主动模式匹配实现算子融合,将小算子融合成大颗粒的算子。大算子既减少Host下发的开销,同时也大大收缩了Device的计算时延。在DeepSeek V3/R1模型中实现了QKV/FFN+Split融合、Transpose+BatchMatMul+Transpose融合、Swiglu融合以及Norm类融合,大幅度减少了算子数目。
动态shape支持
:计算图的执行需要支持动态shape以满足推理场景输入输出序列长度以及batch size的动态厘革,相比于静态shape的整图下沉,动态shape的计算图执行需要每个iteration在Host偏重新执执行shape推导以及申请显存等操作,为了制止Host成为瓶颈,MindSpore通过Shape推导和显存申请、算子Tiling数据计算以及算子下发三级流水优化,实现Host计算和Device计算的掩饰。
模型压缩
:
金箍棒
工具,
快速
实现
模型量化
算法及
量化
推理
全流程
金箍棒是华为昇思 MindSpore 团队与华为诺亚方舟实验室联合研发的模型压缩工具,依靠 MindSpore Rewrite 模块,为算法开辟者屏蔽网络差异和硬件细节,提升算法接入与调优效率,同时提供了可视化、量化丧失分析以及Summary 等工具。
我们使用金箍棒通过差异量化方式,来尝试平衡DeepSeek-R1的精度和性能:
8bit权重量化
:对 DeepSeek-R1 进行8bit 权重量化,使权重显存占用降为1/2,小batch_size场景推理性能提升明显,但大batch_size场景推理性能变差,分析发现是权重量化矩阵乘算子随着batch_size增大性能会降落。
SmoothQuant 8bit量化
:为提升大batch_size场景的性能,用SmoothQuant 8bit 全量化,测试发现随batch_size增加,吞吐量线性度良好,但网络量化精度丧失仍较大。
混合量化
:为降量化精度丧失,对精度较敏感的FeedForward层用激活动态量化,丧失部分性能提升来提升量化精度,MLA层用Outlier-Suppression+异常值克制算法替代SmoothQuant进一步提升精度。
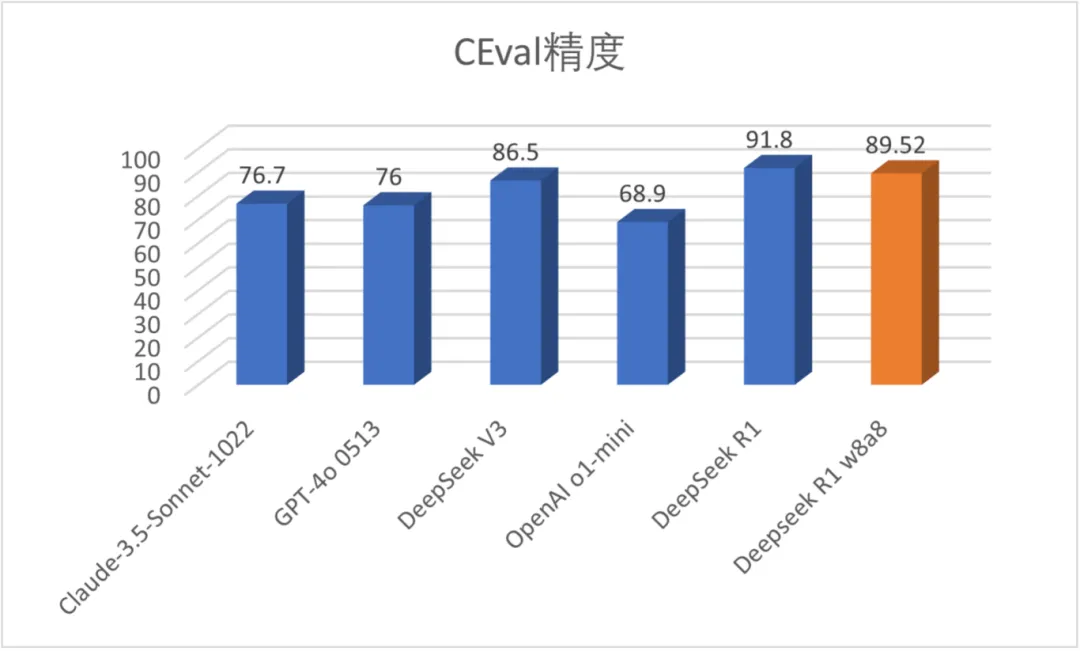
经多次尝试,最终以CEval精度丧失2分的代价,实现DeepSeek-R1部署显存和算力需求减半。
3
算力集群训推平台
北京大学科教创新良好中心自研SCOW算力平台与鹤思算力调理,可以或许高效纳管大规模的异构算力集群,通过软硬件解耦的分层体系架构,屏蔽底层硬件差异,向下支持各种硬件,向上支持各种框架模型应用。基于openEuler+MindSpore社区的开源集群训推平台,通过高效的算力调理技术实现训推一体,已应用到了全国凌驾60家单位,并渐渐应用到了良好中心国产集群。
# 03
高效部署开箱即用
2025年3月7日在北京大学鲲鹏昇腾科教创新良好中心,北大师生和openEuler 与MindSpore 社区开辟者共同首次打通了openEuler+MindSpore+DeepSeek全栈开源推理方案的生产情况部署实践。
北京大学与华为进行生产情况部署实践
到场部署的成员包括:北京大学计算中心工程师龙汀汀(右三)、付振新(右二),北京大学本科生孙远航(右一);华为公司的栾建海(左四),邓叶鹏(左三),李强(左二),李佳明(左一)
1
openEuler情况部署
组网布局推荐使用直连模式,即服务器通过交换机直连,确保每张卡都可以ping通其他卡。
情况要求:
两台Atlas 800I A2(8*64G)。
Ascend HDK Driver 24.1.0版本,Firmware 7.5.0.3.22版本。
openEuler 24.03 LTS版本(内核 5.10)。
2
DeepSeek模型下载
模型需在各个推理节点上进行部署,请确保模型
位置在各节点上一致
,可从如下地址下载。
魔乐社区:
https://modelers.cn/models/MindSpore-Lab/DeepSeek-R1-W8A8
3
MindSpore一键部署
一键式部署脚本推荐在单独控制的节点执行,控制节点需要可以使用SSH访问各个推理节点。
Step1:下载oedeploy工具,调整oedeploy配置文件
# 下载插件包并解压
wget https://repo.oepkgs.net/openEuler/rpm/openEuler-24.03-LTS/contrib/oedp/plugins/mindspore-deepseek.tar.gz
tar zxvf mindspore-deepseek.tar.gz
# 按照提示调整mindspore-deepseek目录下config.yaml
# 下载并安装oedp工具
wget https://repo.oepkgs.net/openEuler/rpm/openEuler-24.03-LTS/contrib/oedp/aarch64/Packages/oedp-1.0.0-2.oe2503.aarch64.rpm
yum localinstall oedp-1.0.0-2.oe2503.aarch64.rpm
复制代码
Step2:运行一键部署脚本
oedp run install #在mindspore-deepseek目录下运行
复制代码
4
推理服务测试验证
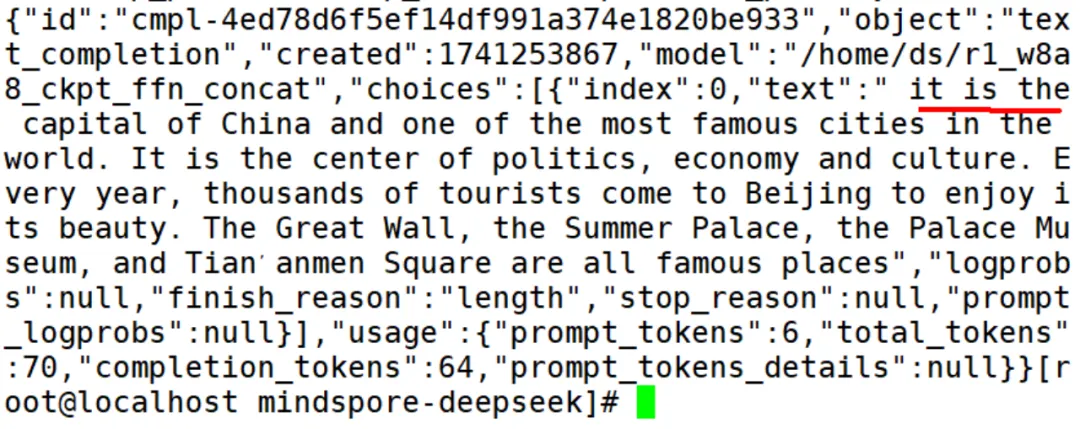
服务拉起后,可使用如下curl指令进行验证
curl http://主节点ip:推理服务端口/v1/completions -H "Content-Type: application/json" -d '{"model": "模型路径", "prompt": "I love Beijing, because", "max_tokens": 32, "temperature": 0, "top_p": 1.0, "top_k": 1, "repetition_penalty":1.0}'
复制代码
注意:"模型路径"请确保和插件目录下config.yaml中的model_path值一致
返回推理结果示例:
测试结果:
基于DeepSeek-R1 W8A8大模型,2台Atlas 800I A2 64GB服务器,128哀求吞吐率凌驾1198token/s,单哀求吞吐率可达16.7token/s。
# 04
开源方案优秀实践
1
高效部署,开箱即用
接纳MindSpore+openEuler一键部署脚本,主动完成镜像拉取、集群启动、推理服务拉取等技术。相较于传统手动部署时间通常耗费2-3小时,基于当前复杂组网现状,本方案端到端部署时间约20分钟。
未来基于精简组网及内存卸载,一键部署可在单台主机上进行DeepSeek满血部署,部署效率进一步提升。
2
全栈开放,生态共建
本方案整合了DeepSeek、openEuler、MindSpore与vLLM/RAY等社区开源组件,用户可以轻松获取源码,根据需求进行二次开辟。联合社区进行庞大特性开辟与生态共建,企业开辟成本低落。
北大科教创新良好中心根据自身现实情况开辟算力集群训推平台,并贡献反馈开源社区,取得模型部署易用性的进一步提升。
3
按需量化,动态适配
压缩模型工具(金箍棒)针对开源大模型,根据用户及硬件能力可进行适当定制量化,本方案使用8bit权重量化、SmoothQuant 8bit量化和混合量化等技术,最终以CEval精度丧失2分的代价,实现了DeepSeek-R1w8a8的大模型部署。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!更多信息从访问主页:qidao123.com:ToB企服之家,中国第一个企服评测及商务社交产业平台。
欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/)
Powered by Discuz! X3.4