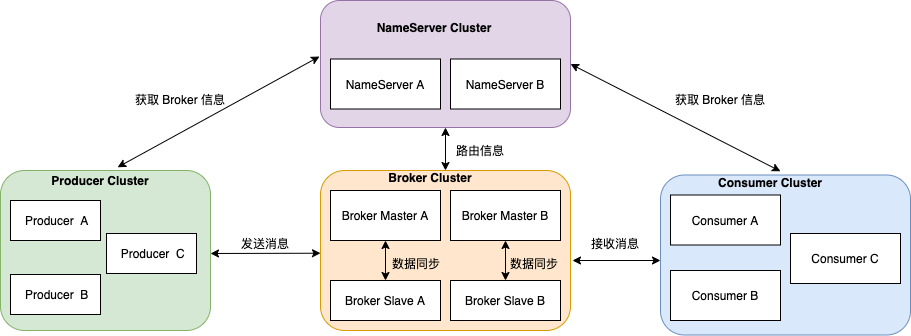
 整体架构中包含四种角色 :
整体架构中包含四种角色 :

磁盘的存取速度相对内存来讲并不快,一次磁盘 IO 的耗时主要取决于:寻道时间和盘片旋转时间,提高磁盘 IO 性能最有效的方法就是:减少随机 IO,增加顺序 IO 。
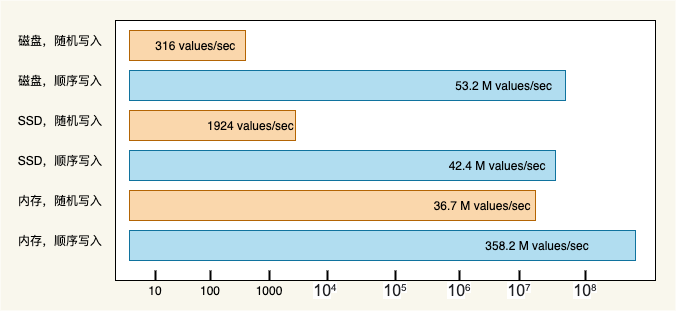
《 The Pathologies of Big Data 》这篇文章指出:内存随机读写的速度远远低于磁盘顺序读写的速度。磁盘顺序写入速度可以达到几百兆/s,而随机写入速度只有几百 KB /s,相差上千倍。
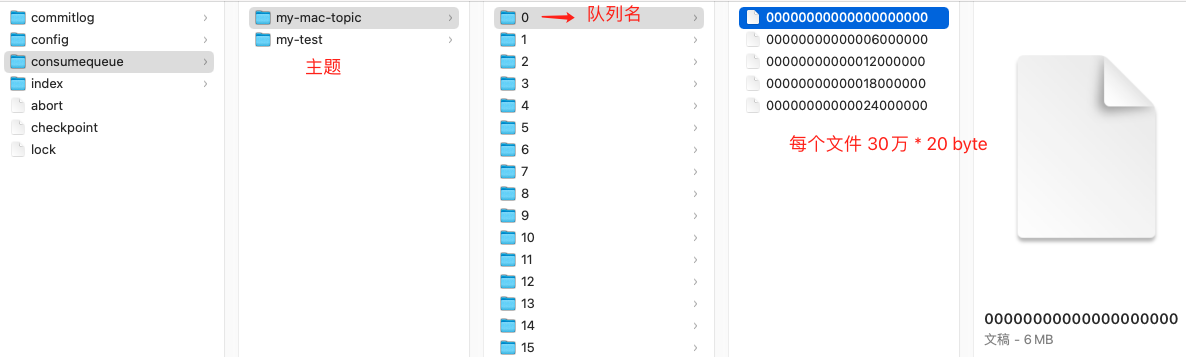
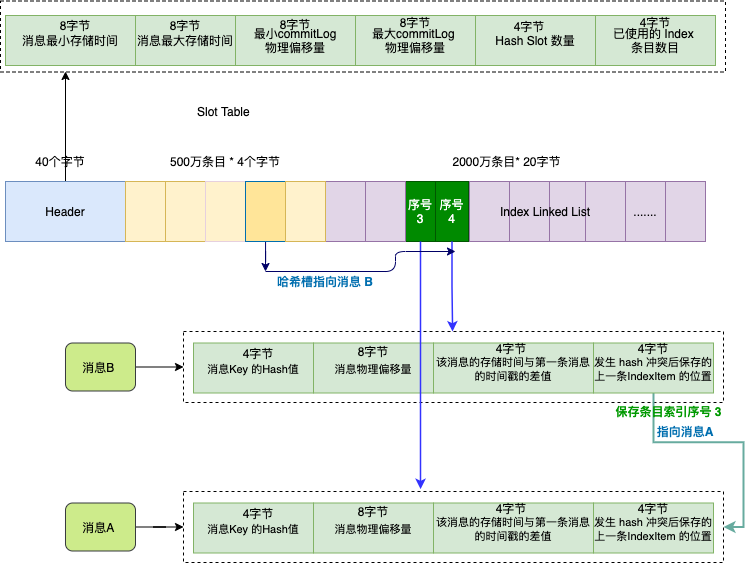
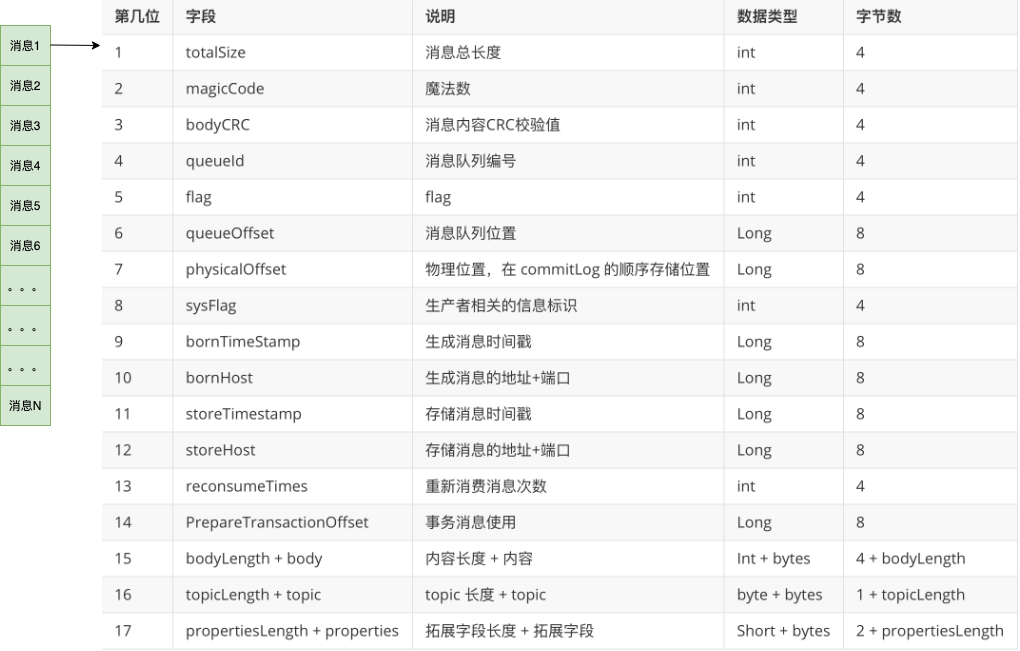
因为消息是一条一条写入到 commitlog 文件 ,写入完成后,我们可以得到这条消息的物理偏移量。
每条消息的物理偏移量是唯一的, commitlog 文件名是递增的,可以根据消息的物理偏移量通过二分查找,定位消息位于那个文件中,并获取到消息实体数据。
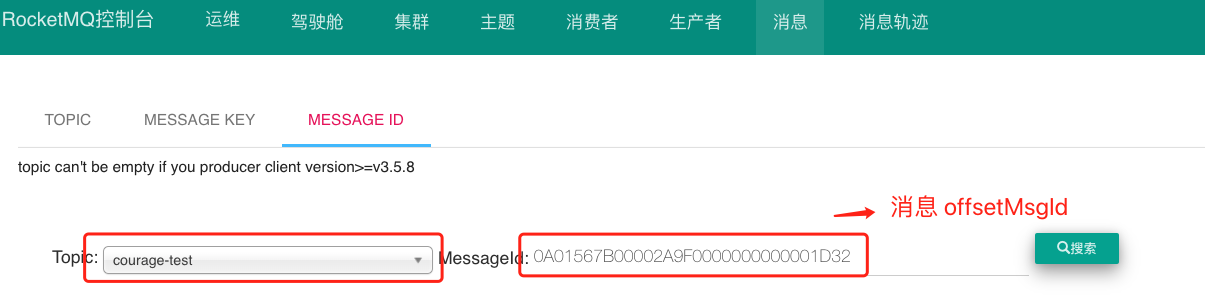
消息 offsetMsgId 是由 Broker 服务端在写入消息时生成的 ,该消息包含两个部分:
- Broker 服务端 ip + port 8个字节;
- commitlog 物理偏移量 8个字节 。