ToB企服应用市场:ToB评测及商务社交产业平台
标题: 《Attention Is All You Need》论文精读,并解析Transformer模型结构 [打印本页]
作者: 道家人 时间: 2022-6-26 15:09
标题: 《Attention Is All You Need》论文精读,并解析Transformer模型结构
建议:结合《Attention Is All You Need》论文观看此文章。
目录
一、引言
二、结论
三、模型结构解析
(1)多头注意力模型结构
(2)Msked Multi-Head Attention
(3)相对位置编码
(4)为什么对点积注意力进行缩放
四、调整模型的结构超参数
五、注意力可视化
一、引言
主导的序列转导模型是基于复杂的递归或卷积神经网络,其中包括一个编码器和一个解码器。性能最好的模型也通过注意机制连接编码器和解码器。我们提出了一个新的简单的网络体系结构,Transformer,完全基于注意机制,不需要重复和卷积。在两个机器翻译任务上的实验表明,这些模型在质量上要优越的同时,可并行化程度更高,训练所需时间也不大。我们的模型在WMT 2014英德翻译任务上实现了28.4 BLEU,比现有的包括汇编在内的最佳结果提高了2 BLEU以上。在WMT2014英译法任务上,我们的模型在8台GPU(官网复现的代码支持TPU)上训练3.5天后,建立了一个新的单模型最先进的BLEU评分为41.8,仅占文献中最好模型的训练成本的一小部分。我们表明,Transformer通过成功地将其应用到英语选区句法分析中,无论是在训练数据较大的情况下,还是在训练数据有限的情况下,都很好地概括了其他任务。
二、结论
在本工作中,我们提出了第一个完全基于注意的序列转导模型Transformer,用多头自注意替换了编码器-解码器结构中最常用的递归层。
对于翻译任务,Transformer可以比基于递归或卷积层的架构训练得更快。在WMT 2014英译德和WMT 2014英译法的翻译任务上,我们实现了一种新的艺术状态。在前一个任务中,我们最好的模型甚至比之前报道的所有集合都要好。
我们对基于注意力的模型的未来感到兴奋,并计划将其应用于其他任务。我们计划将Transformer扩展到文本以外的输入和输出模式问题,研究局部的、受限的注意机制,以有效处理图像、音频和视频等大的输入和输出。使生成少序列化是我们的另一个研究目标。
三、模型结构解析
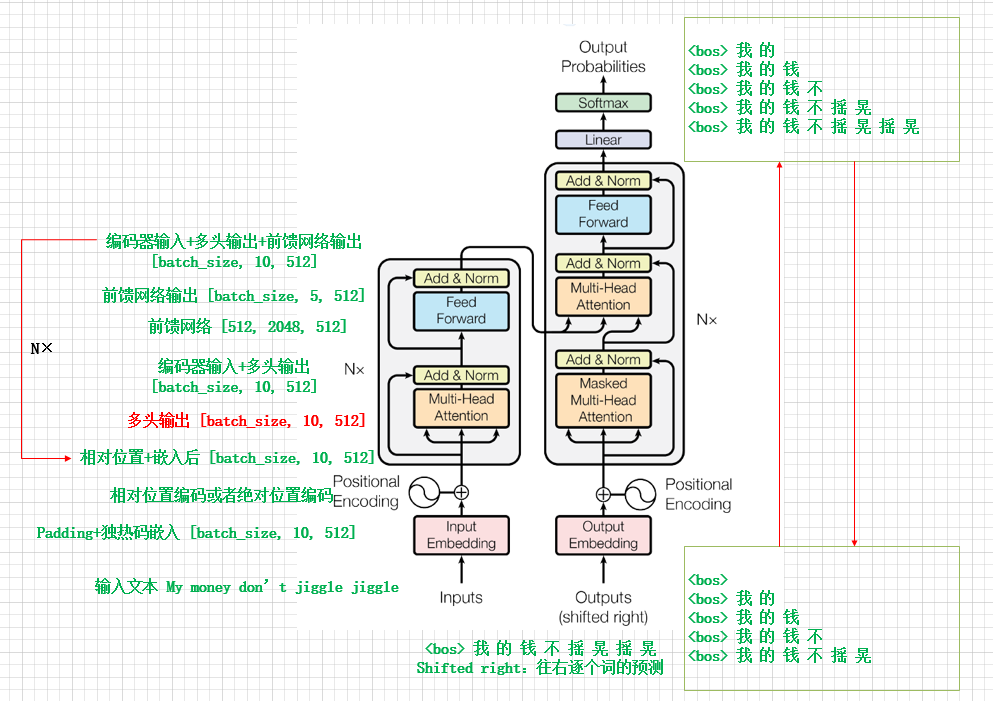
Transformer的模型结构如下图所示,通过把“My money don't jiggle jiggle”翻译成“我的钱不摇晃摇晃”来分析Transformer的工作过程。
训练过程中,每一次解码器的输出与数据集中的翻译值通过交叉熵计算错误率(一次送入batch_size大小个token,计算错误率),从而对权重进行更新。
预测过程,同训练过程相似,即输入英文句子,一个词一个词的翻译成汉语句子。
注:解码器的输出与数据集中的翻译值作比较,即经过Softmax函数后,输出最大概率的一个预测词,预测词与真实值作比较。
编码器的输入和输出(一次输出一个翻译词汇):
自回归:在生成下一个符号时,将前面生成的符号作为附加输入。
第一次输入, 输出 我 的
第二次输入 我 的, 输出 我 的 钱
第三次输入 我 的 钱, 输出 我 的 钱 不
第四次输入 我 的 钱 不 摇 晃, 输出 我 的 钱 不 摇 晃
第五次输入 我 的 钱 不 摇 晃 摇 晃, 输出 我 的 钱 不 摇 晃 摇 晃
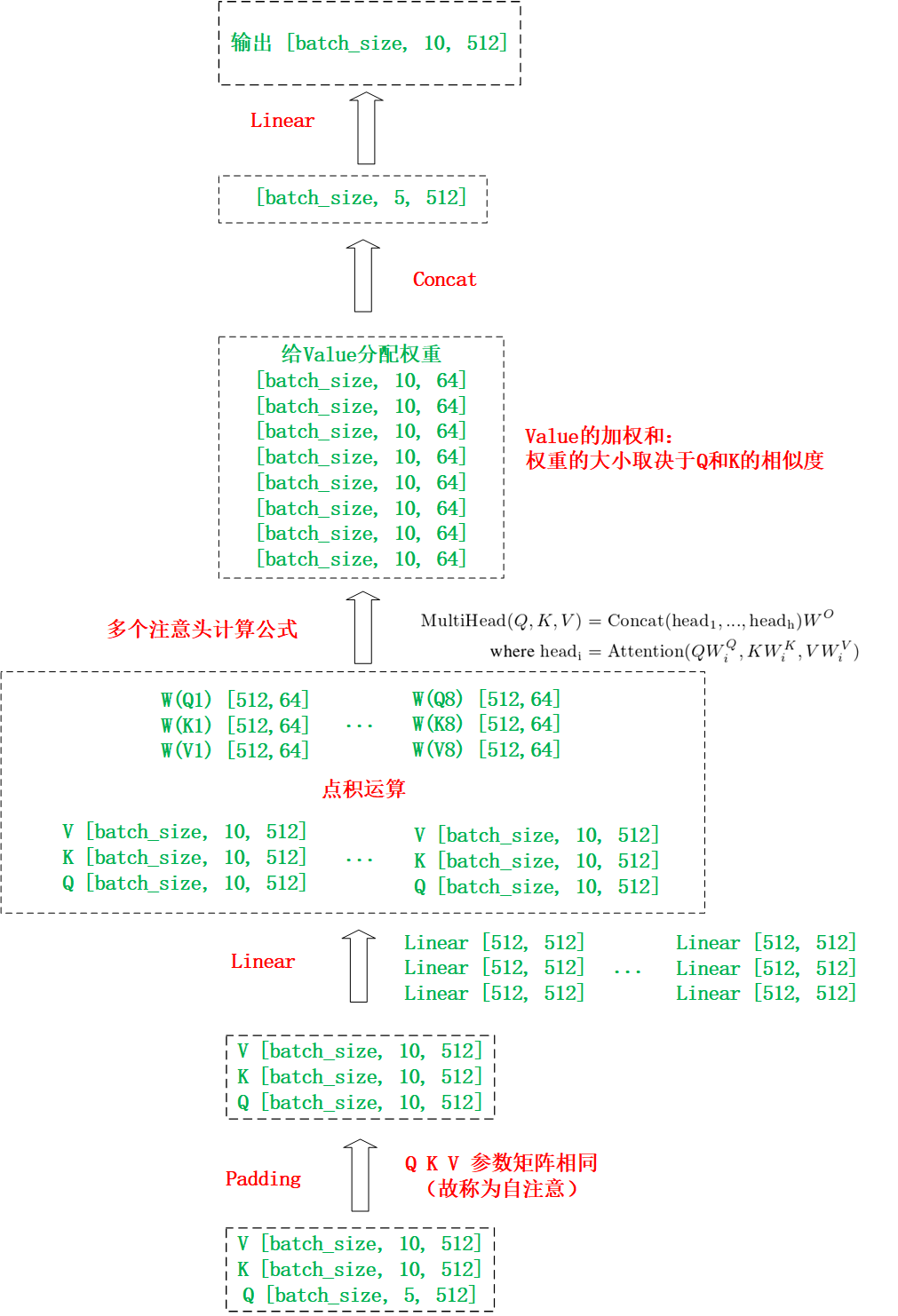
(1)多头注意力模型结构
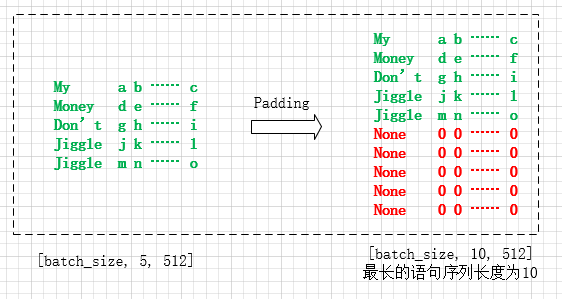
假设数据集中语句的最长序列是10,输入“My money don't jiggle jiggle”,经过独热码后的矩阵大小为 [batch_size, 5, 512],再经过Padding后的矩阵大小为 [batch_size, 10, 512],参数矩阵大概可以描述为以下形式:
缩放点击注意力汇聚和多头注意力机制结构,如下图所示:
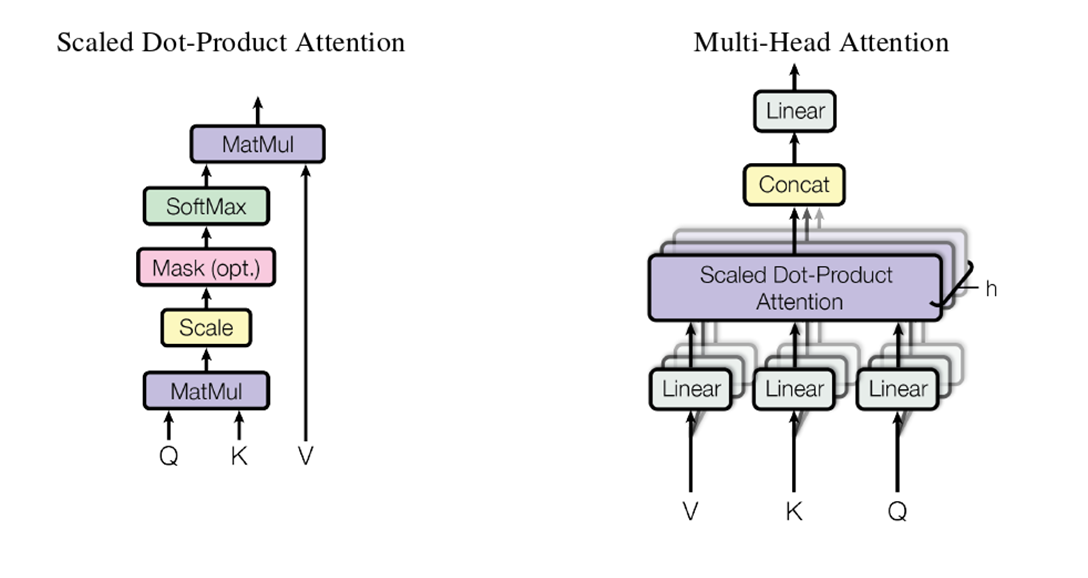
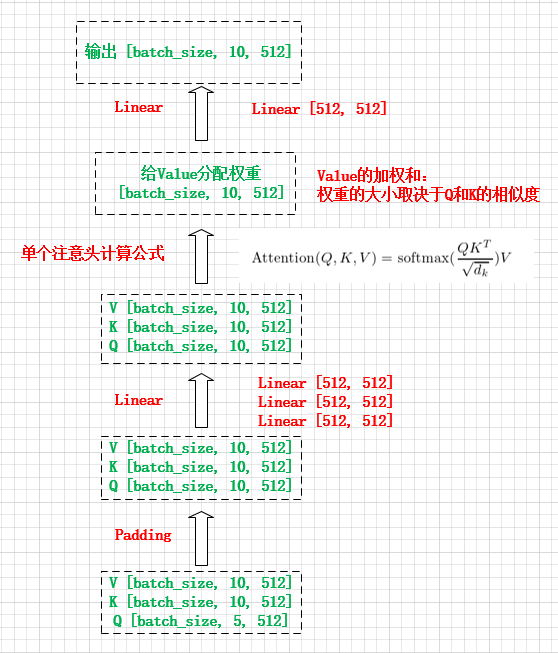
首先分析一个注意力头的工作过程:
然后分析多个注意力头的工作过程:(此处是 8 heads)
原文:我们没有用512维的键、值和查询执行单一的注意函数(即没有选用单一的注意力头),而是发现将查询、键和值经h次不同的、学到的线性投影分别线性投影到dk、dk和dv维是有利的。在这些查询、键和值的每个线性投影后,我们并行执行注意函数,产生dv维输出值,Concat后,再次进行投影,得到最终的值。
注:
- 缩放点积注意力要求Q、K、V的长度要求一致
- 输入的Q、K、V参数矩阵相同,可能这就是称为自注意的原因(应该是这样理解)
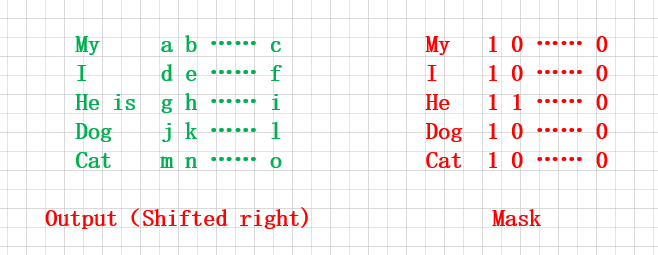
(2)Msked Multi-Head Attention
为了方便一次性输入batch_size个词汇或句子,把 Output(Shifted right) 中的目标词汇后方的需要预测的词汇mask掉,即把下方的两个矩阵相乘,便可实现并行化处理多个句子:
(3)相对位置编码
相对位置信息如下:

Pos是位置,i是维度,d
 定义为512。
定义为512。
下面证明选用正余弦函数进行相对位置的编码后,词汇的相对位置是线性关系。

(4)为什么对点积注意力进行缩放
问题:样本维度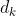 越大,点积增长的幅度越大,会将Softmax函数推入梯度极小的区域,从而使训练难度增大。(具体参考softmax函数的梯度函数,即导数)
越大,点积增长的幅度越大,会将Softmax函数推入梯度极小的区域,从而使训练难度增大。(具体参考softmax函数的梯度函数,即导数)
解决:构建缩放点积注意力,对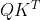 的点积乘以
的点积乘以 ,进行点积的缩放。
,进行点积的缩放。
四、调整模型的结构超参数
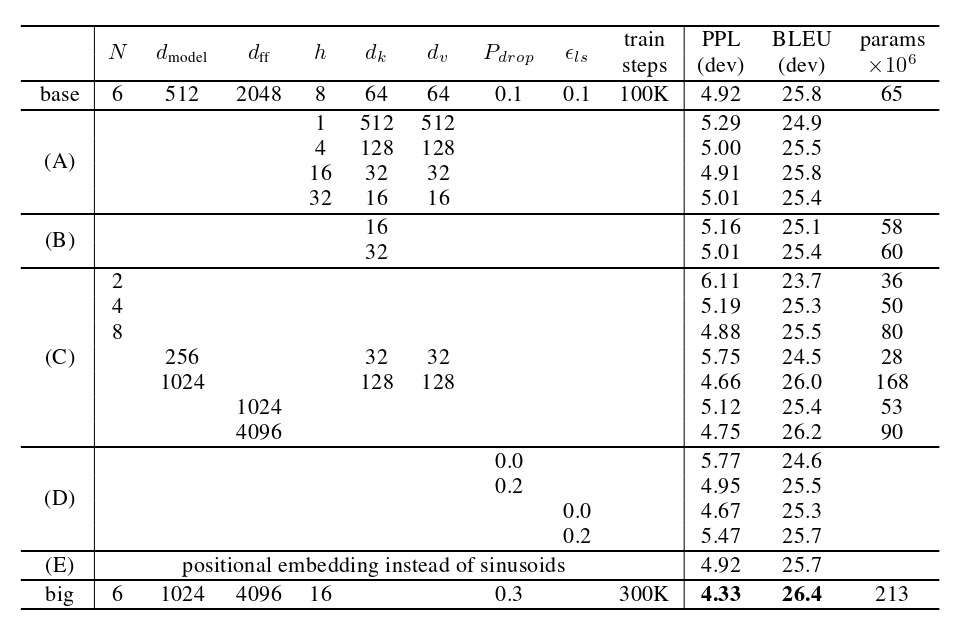
下面的表格中,从左往右的超参数分别表示:
- 编码器块和解码器块的个数
- 输入输出的维度(宽度)
- 前馈网路的隐藏层维度
原文:The mensionality of input and output is dmodel= 512, and the inner-layer has dimensionality dff= 2048.
- 注意力头的个数
- 一个注意力头的k的维度
- 一个注意力头的v的维度
- 舍弃比率
- 学习率
- 训练步数
- 评价指标
五、注意力可视化
不同颜色,代表不同的注意力头。
线条的暗淡程度,代表给Value分配权重的大小。
(1)许多注意头注意到动词 ‘使’ 的一个遥远依赖性,完成了短语 ‘使…更困难’ 。
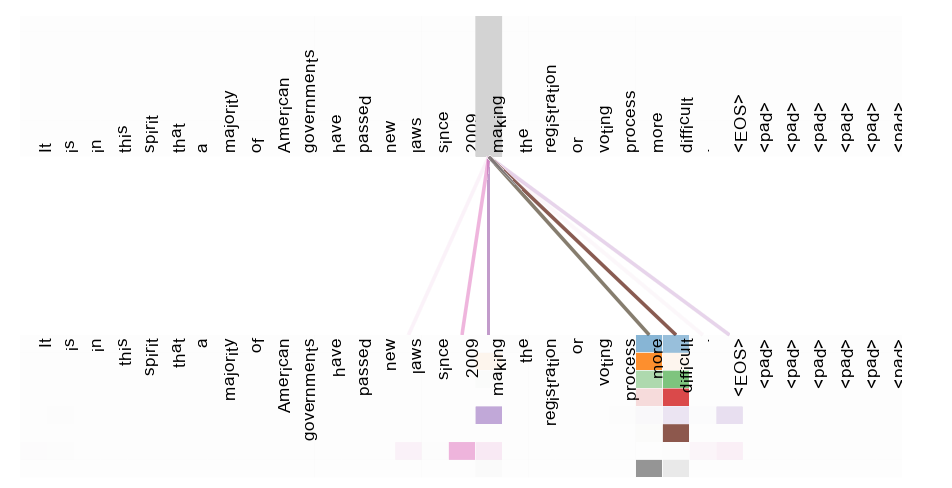
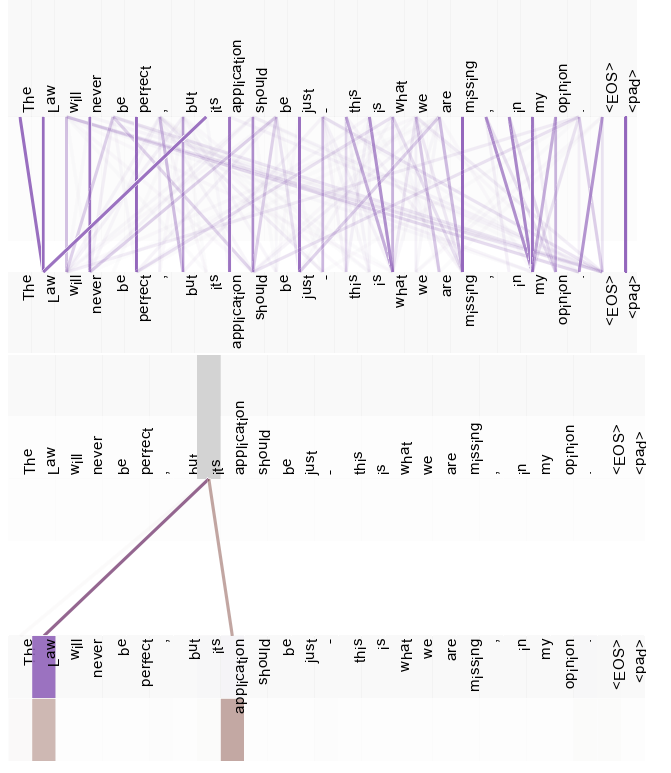
(2)上面是一个注意力头的所有注意力可视化图;下面的图把 “its” 单独拿出来进行观察,其注意力权重很突出。
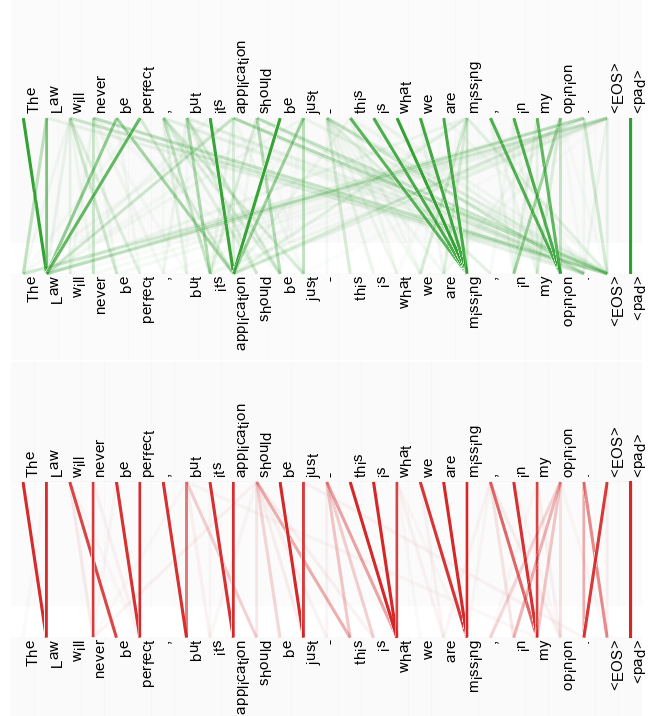
(3)两个不同注意力头学到的不同注意力及其权重。
>>>如有疑问,欢迎评论区一起探讨。
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) |
Powered by Discuz! X3.4 |