ToB企服应用市场:ToB评测及商务社交产业平台
标题:
不存在的!python说不给数据的浏览器是不存在的!
[打印本页]
作者:
涛声依旧在
时间:
2022-8-9 14:38
标题:
不存在的!python说不给数据的浏览器是不存在的!
有时候我们些代码是总发此疑惑?
为什么别人采集 xx 网站的时候能成功,而我却总是不返回给数据
出现这种原因时往往是我们没有给够伪装, 被识别了出来~
就像人,你出门肯定是要穿衣服的对不,如果你不穿!
走在外面,肯定是最显眼的一个,不抓你抓谁
还有一种就是明明我之前运行成功了,为什么我现在再次运行时就不行了呢~
而且还甩一句话给我 “系统检测到您频繁访问,请稍后再来”
好啦!现在咋们正经的来介绍一下面对此种情况该如何处理~
要会伪装,要想想看,人是怎么访问网站的
这次我们来说说伪装 Header ,当你要去爬取某个网站的数据的时候
你要想想看,如果是别人爬取你的数据,你会做什么操作
你是不是也不想,让别人随随便便就疯狂请求你的服务器
你是不是也会,采取一定的措施
比如,我有一个网站,你分析到了我的地址
当你想要通过 python 来爬取的时候…
这边我来写一个简单的可以被请求的例子
from flask import Flask
app = Flask(__name__)
@app.route('/getInfo')
def hello_world():
return "这里假装有很多数据"
if __name__ == "__main__":
app.run(debug=True)
复制代码
ok ,假设你现在分析到了我的地址了,
也就是可以通过 /getInfo 就可以获取到数据了
你感觉很爽,就开始请求了
url = 'http://127.0.0.1:5000/getInfo'
response = requests.get(url)
print(response.text)
复制代码
没错,这个时候你确实获取到数据了
但是!我觉得有点不对劲了,想看看请求的 header 信息
@app.route('/getInfo')
def hello_world():
print(request.headers)
return "这里假装有很多数据"
if __name__ == "__main__":
app.run(debug=True)
复制代码
结果看到的 headers 信息是这样的
Host: 127.0.0.1:5000
User-Agent: python-requests/2.21.0
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-alive
复制代码
User-Agent: python-requests/2.21.0
复制代码
居然使用 python 的库来请求,你说我不封你封谁呢?
所以我这个时候进行判断,就获取不到数据了
@app.route('/getInfo')
def hello_world():
if(str(request.headers.get('User-Agent')).startswith('python')):
return "系统检测到您频繁访问,请稍后再来"
else:
return "这里假装有很多数据"
欢迎加入白嫖Q群:660193417 ###
if __name__ == "__main__":
app.run(debug=True)
复制代码
你这个时候的请求
if __name__ == '__main__': url = 'http://127.0.0.1:5000/getInfo'
response = requests.get(url)
print(response.text)
复制代码
得到的结果就是
“系统检测到您频繁访问,请稍后再来”
你已经在我面前暴露了,想重新再来,那么怎么办呢?
伪装自己呗,python 不可以访问
浏览器可以访问呀,所以你可以修改你的请求头
先在浏览器访问,然后在抓取数据的时候获取到 Header 数据
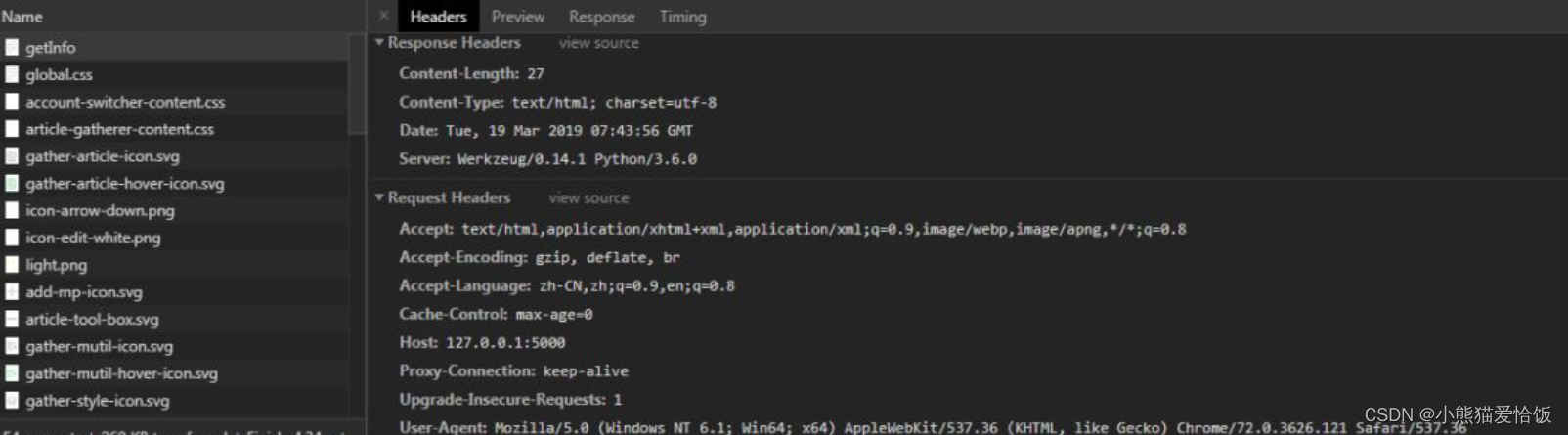
当然你也可以使用 Chrome 的控制面板获取 Header
有了 Header 信息之后,就可以使用 requests模块轻松获取
恩,现在的你学会假装自己是浏览器了
欢迎加入白嫖Q群:660193417 ###
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://127.0.0.1:5000/getInfo'
response = requests.get(url,headers=headers)
print(response.text)
复制代码
再获取一次可以发现,返回的是
这里假装有很多数据
ok,你又获取到数据了
好啦,这篇文章就到这里啦~对你有帮助就点赞收藏一下吧!
我是小熊猫,咱下篇文章见
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4