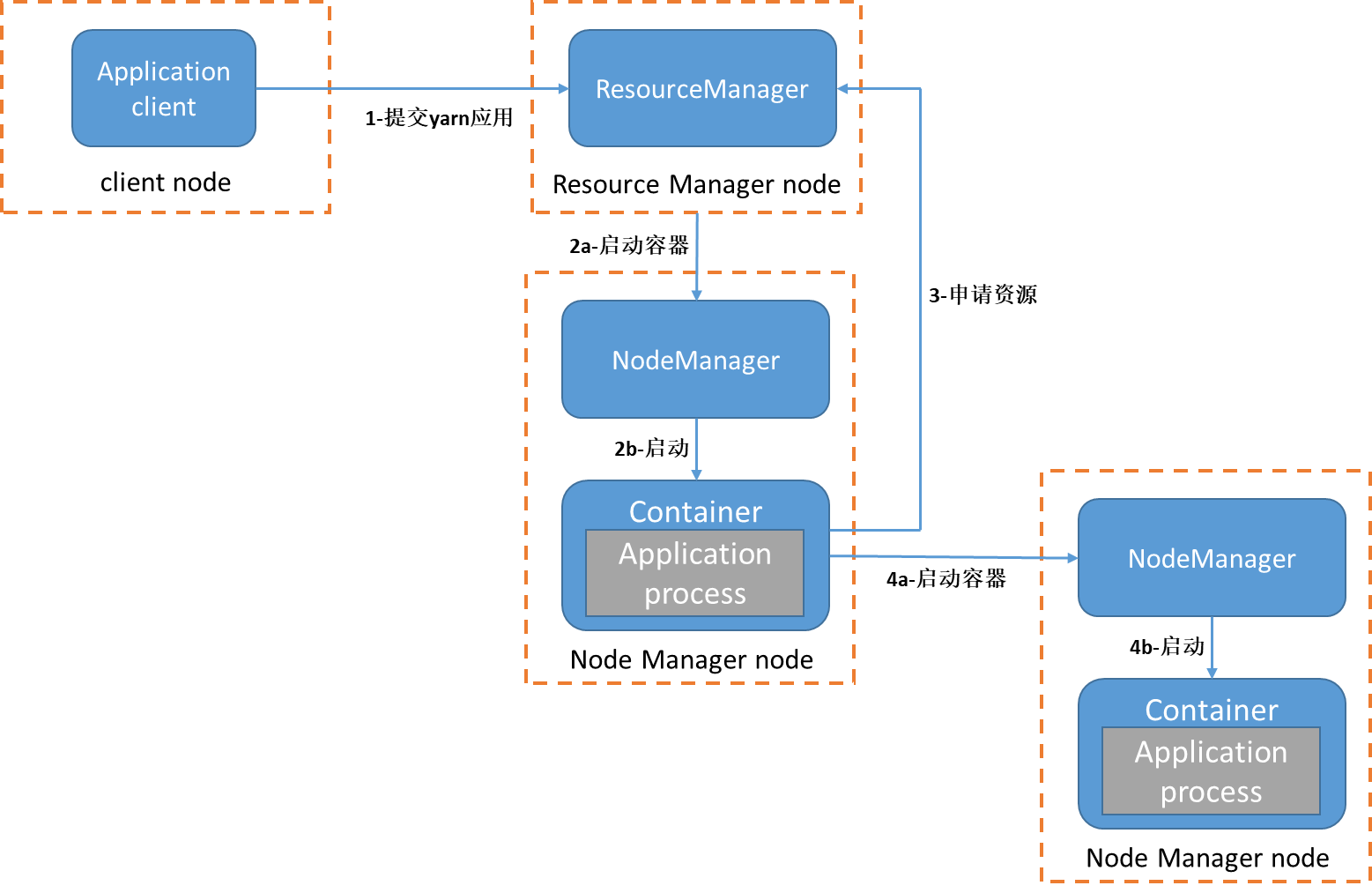
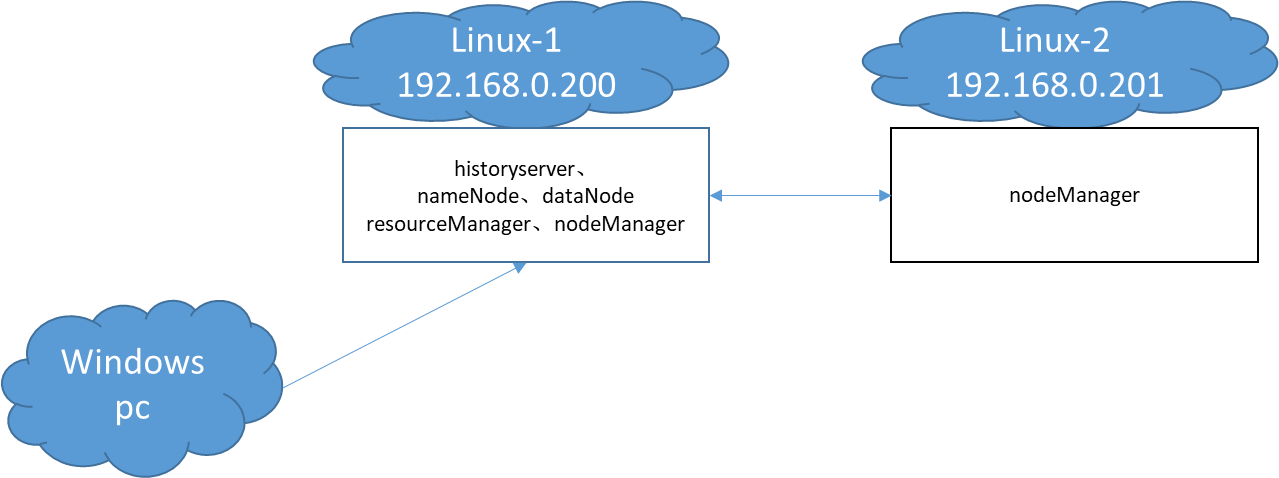
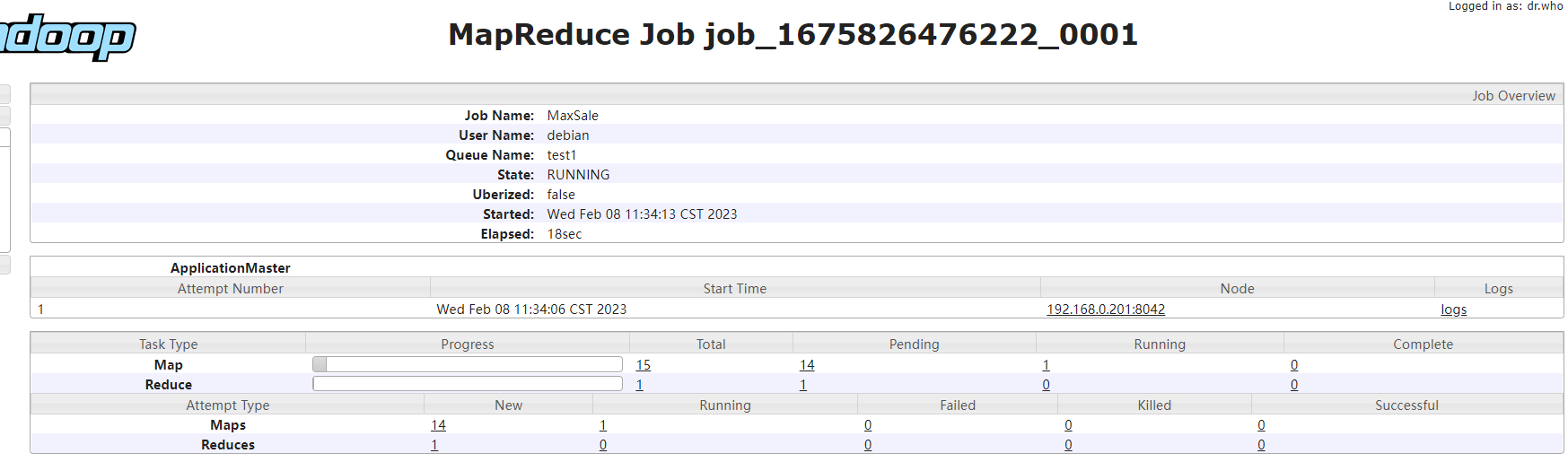
这里提交的应用还是maxSaleMapReduce,唯一不同的是配置文件mapreduce.job.running.map.limit(map同时最大运行数量)设置成3。可以在https://github.com/xunpengliu/hello-hadoop获取代码,如果之前已经下载过需要拉取最新代码后重新打包
更多配置可以参考 https://hadoop.apache.org/docs/r2.10.2/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
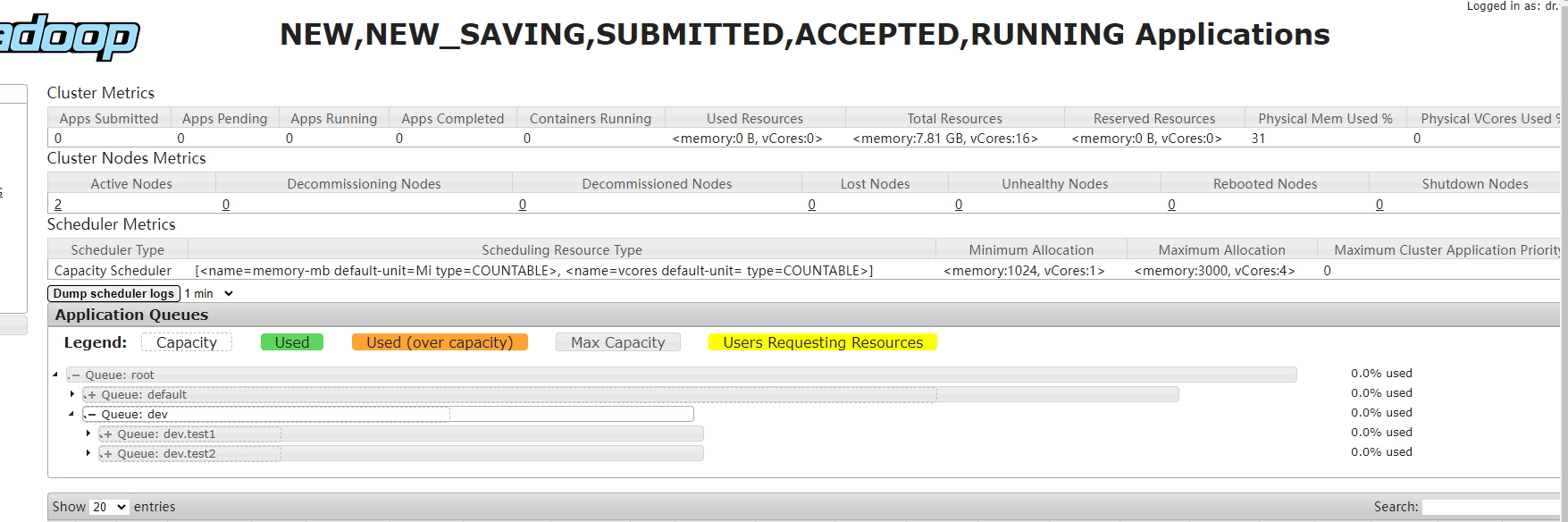
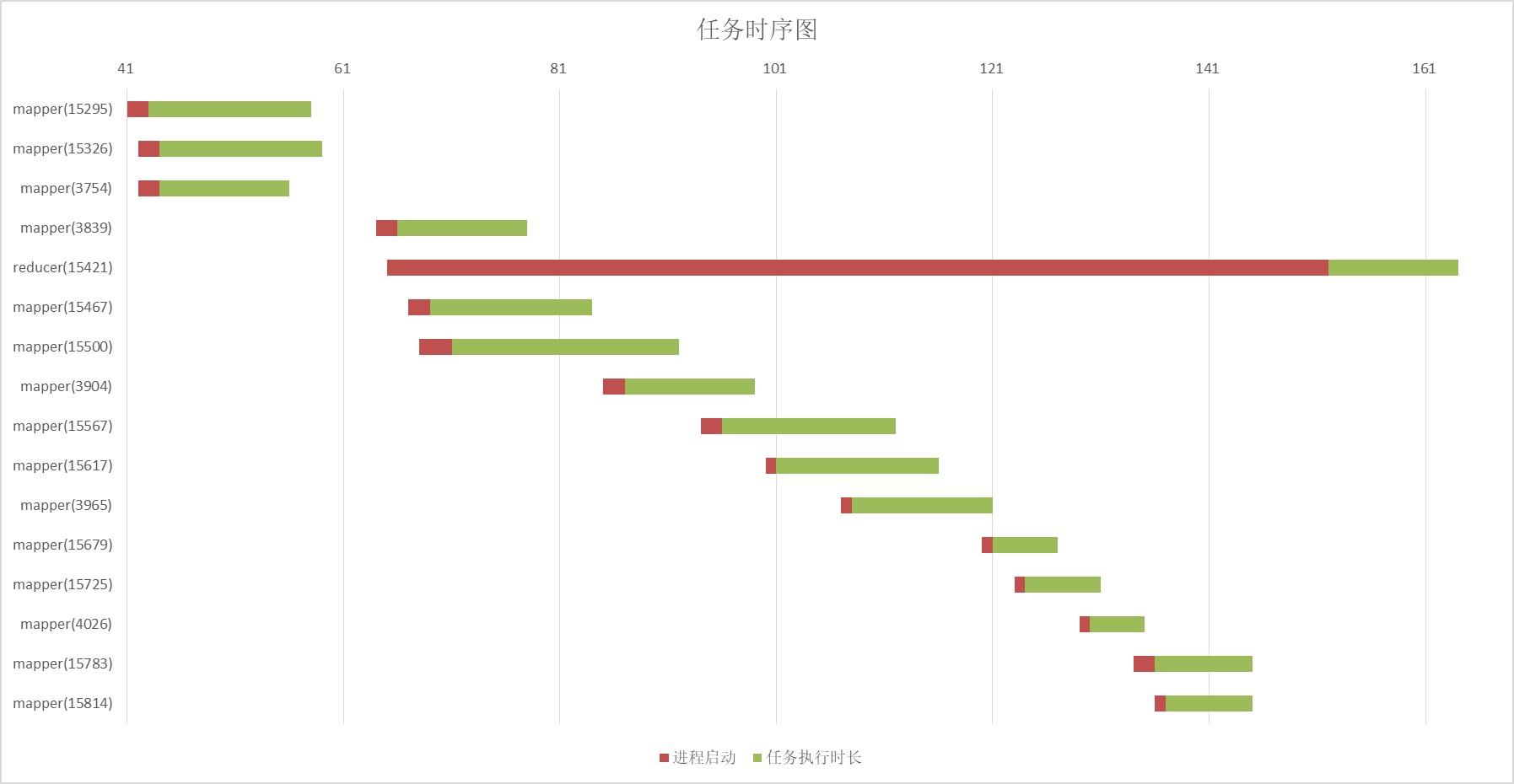
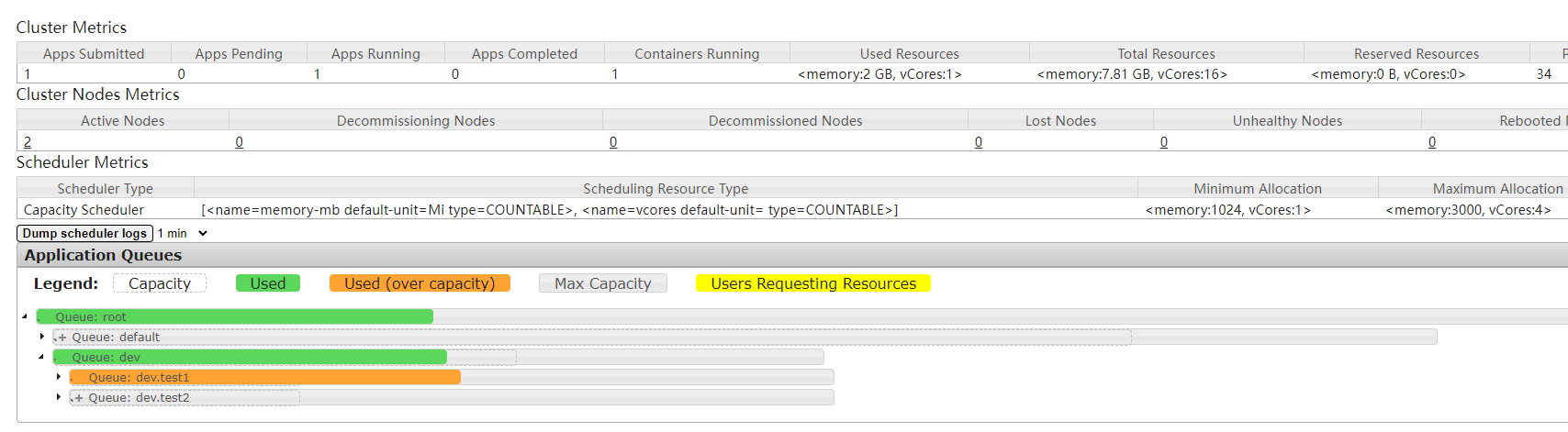
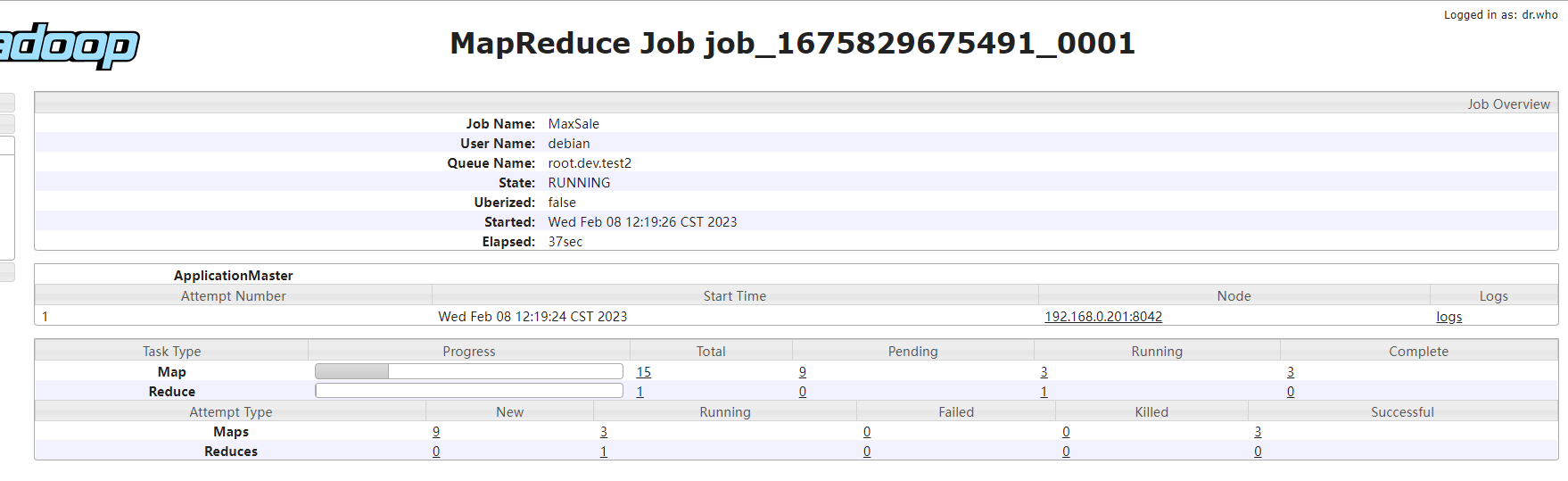
启动进程数量和集群资源相关,因为资源受限,可以发现此时应用执行时间明显偏长队列状态:
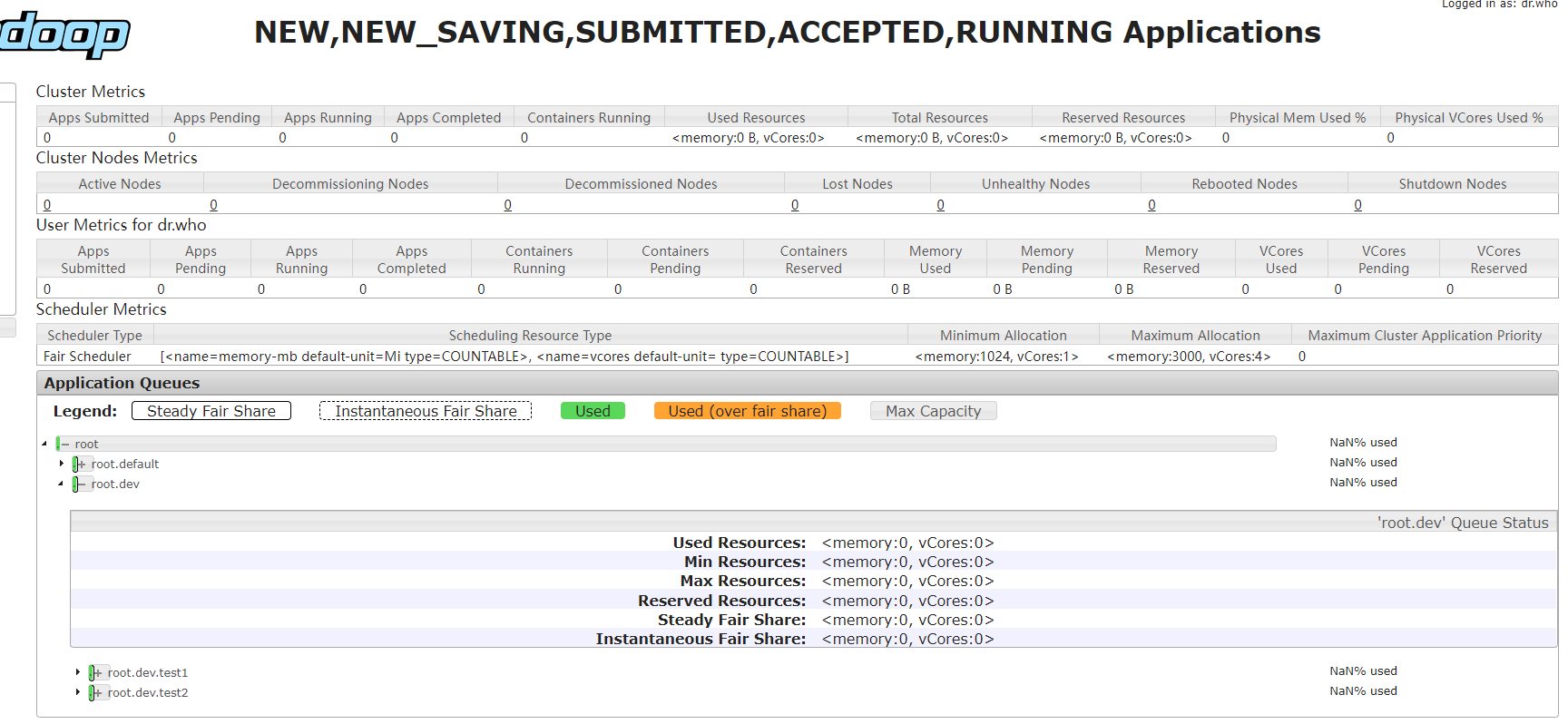
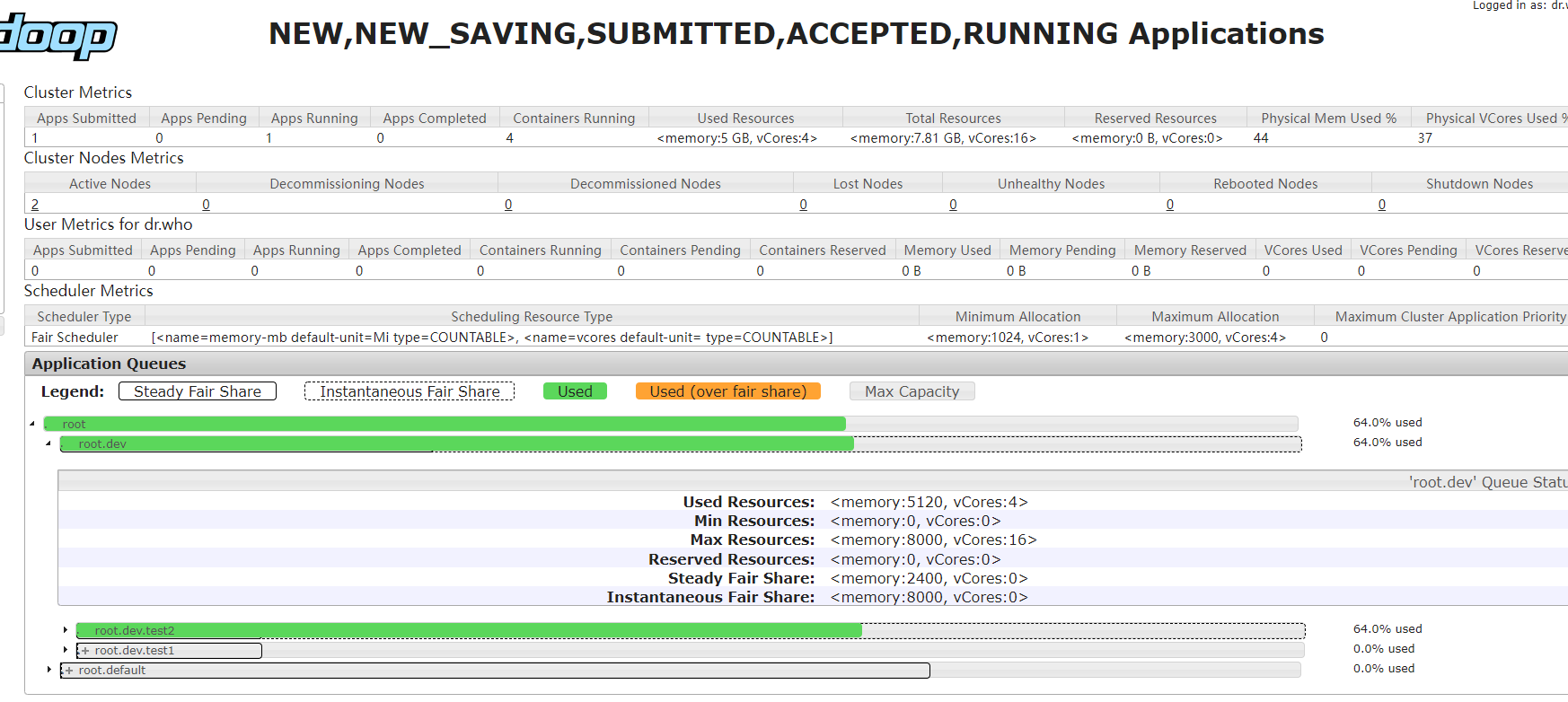
更多配置可以参考 https://hadoop.apache.org/docs/r2.10.2/hadoop-yarn/hadoop-yarn-site/FairScheduler.html
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |