
摘要:Flink是一个批处理和流处理结合的统一计算框架,其核心是一个提供了数据分发以及并行化计算的流数据处理引擎。它的最大亮点是流处理,是业界最顶级的开源流处理引擎。本文分享自华为云社区《【云小课】EI第44课 MRS基础原理之Flink组件介绍》,作者:阅识风云。
 本课程为您介绍华为云MapReduce服务中Flink服务的基本原理介绍并展示如何通过MRS集群客户端提交Flink作业。
本课程为您介绍华为云MapReduce服务中Flink服务的基本原理介绍并展示如何通过MRS集群客户端提交Flink作业。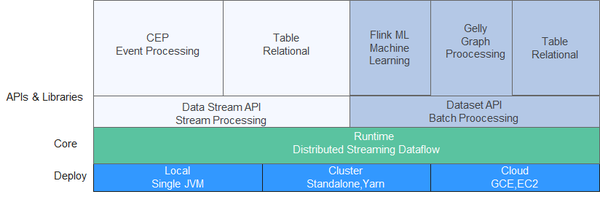 Flink重点构建如下特性:
Flink重点构建如下特性: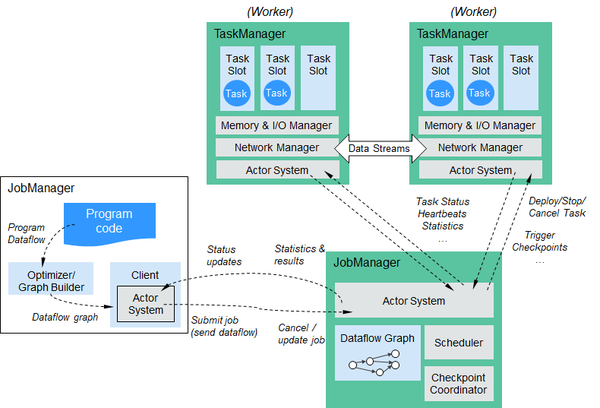 Flink整个系统包含三个部分:
Flink整个系统包含三个部分: 图4 启动session成功
图4 启动session成功 图5 在session中提交作业成功
图5 在session中提交作业成功 6.使用运行用户登录MRS集群的FusionInsight Manager界面,单击“集群 > 服务 > Yarn”,单击“ResourceManager WebUI”后的链接,进入Yarn服务的原生页面,找到对应作业的application,单击application名称,进入到作业详情页面。
6.使用运行用户登录MRS集群的FusionInsight Manager界面,单击“集群 > 服务 > Yarn”,单击“ResourceManager WebUI”后的链接,进入Yarn服务的原生页面,找到对应作业的application,单击application名称,进入到作业详情页面。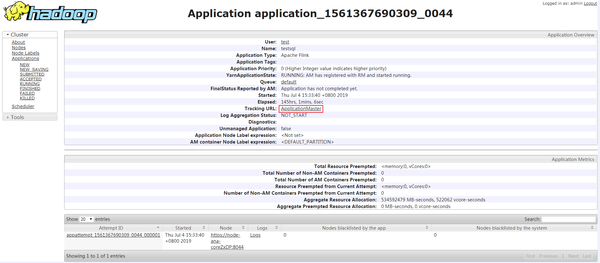
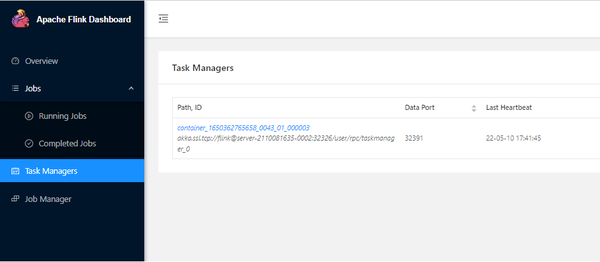 好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里
好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |