官方参考手册:http://freemarker.foofun.cn/toc.html
- Freemarker 将数据填入 .ftl 模板导出 word(.doc/.docx)
- 参考链接:
SpringBoot整合Freemarker导出word文档表格
freemarker导出Word,文本,可循环表格,合并单元格,可循环图片,目录更新(一)
- 缺点:
导出的 .doc / .docx 实际上是 xml 文件,用办公软件能正常打开使用。但是转 PDF 的时候发现转不成功。转过之后的 PDF 显示的不是 word 的格式字符,而是像 xml 文件的标签及字符。
- 参考链接:
- Freemarker 结合 .docx 格式的本质将数据填入 .docx 里面的 document.xml 文件导出 .docx
- 参考链接:
freemarker动态生成word并将生成的word转为PDF
- 优点:
可转换为 pdf
- 相关错误:
A. Date 格式的数据传输报错!
解决方案:复制代码- ${(initialTime?string("yyyy-MM-dd HH:mm:ss"))!}
- 附:
a. 循环行及表单行是否显示功能参考链接:
SpringBoot整合Freemarker导出word文档表格
freemarker合并单元格,if、else标签的使用,null、空字符串处理
如:
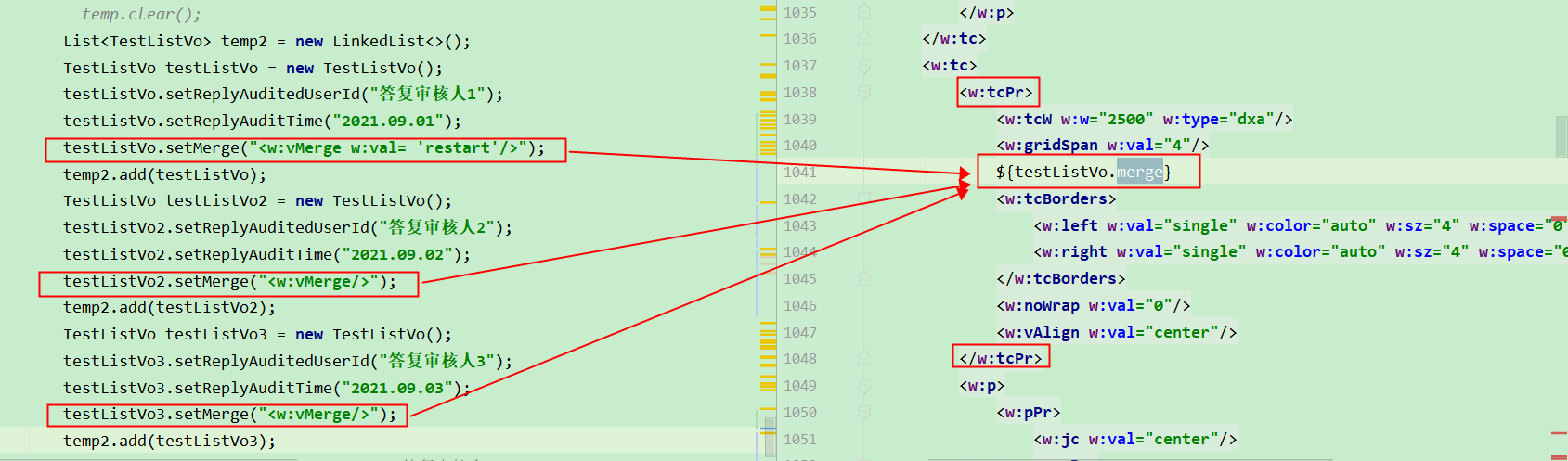
导出结果如下:

也可向参考链接2一样,在 xml 上定义插入对应的合并代码(如下图)。

- 参考链接:
结合 .docx 格式的本质将数据填入 .docx 里面的 document.xml 文件导出 .docx
docx4j 中模板的使用
docx4j 实现动态表格(模板式)
docx4j 中图片的使用(模板式)
docx4j 实现动态表格(模板式)单元格合并(含多列并列合并)
Poi的导出word和转pdf --已试过,可行
Java文件操作之word转pdf并导出(liunx和windows)
使用Aspose.word (Java) 填充word文档数据(包含图片填充)

