基于日志增量订阅&消费支持的业务:
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x工作原理
它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间。主要用来备份和数据同步。binlog 有三种模式:STATEMENT、ROW、MIXED
举例来说,下面的sql
mysql的binlog文件长这个样子。
启用Binlog注意以下几点:
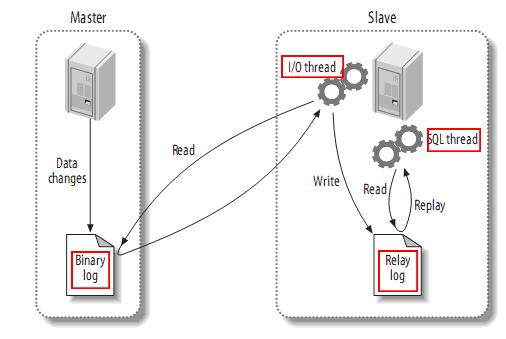
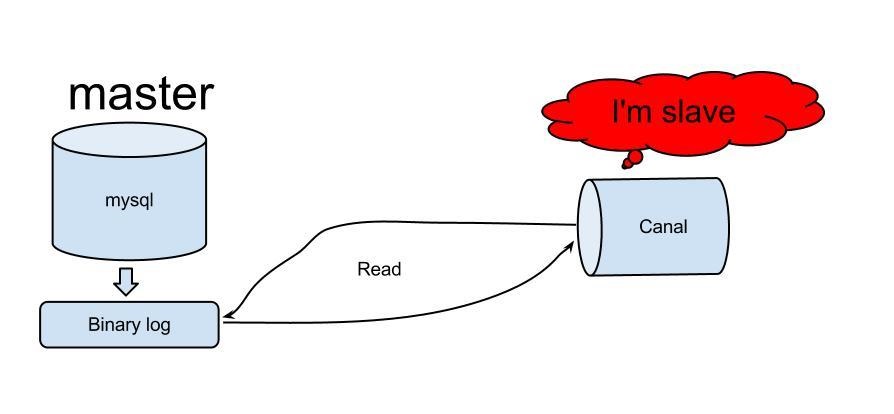
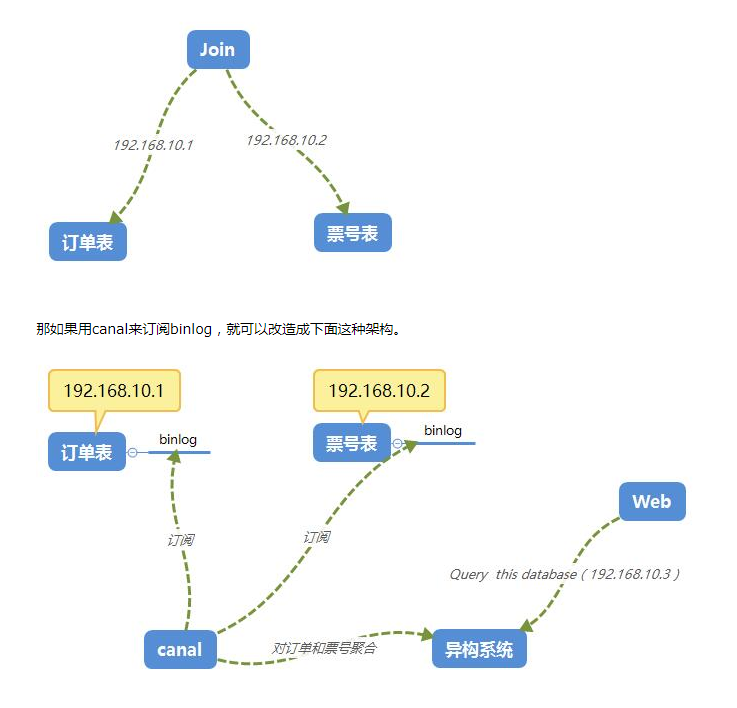
理解了mysql的主从同步的机制再来看canal就比较清晰了,canal主要是听过伪装成mysql从server来向主server拉取数据。
canal的组件化设计非常好,有点类似于tomcat的设计。使用组合设计,依赖倒置,面向接口的设计。
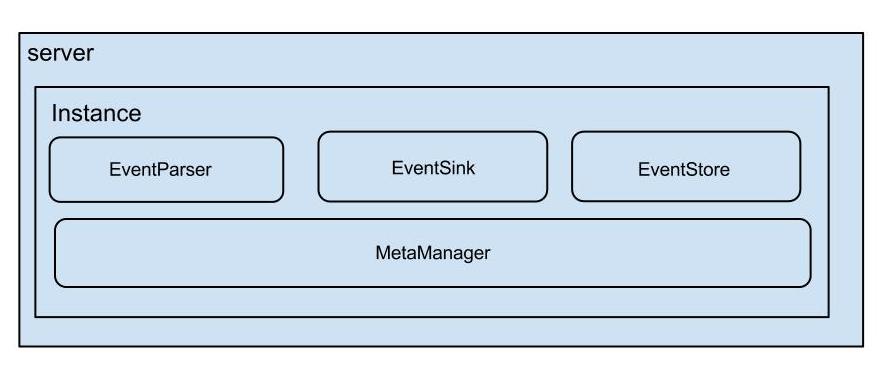
每个canal instance 有多个组件构成。在conf/spring/default-instance.xml中配置了这些组件。他其实是使用了spring的容器来进行这些组件管理的。instance 包含的组件
这里是一个cannalInstance工作所包含的大组件。截取自 conf/spring/default-instance.xml
eventParser 最基本的组件,类似于mysql从库的dump线程,负责从master中获取bin_log
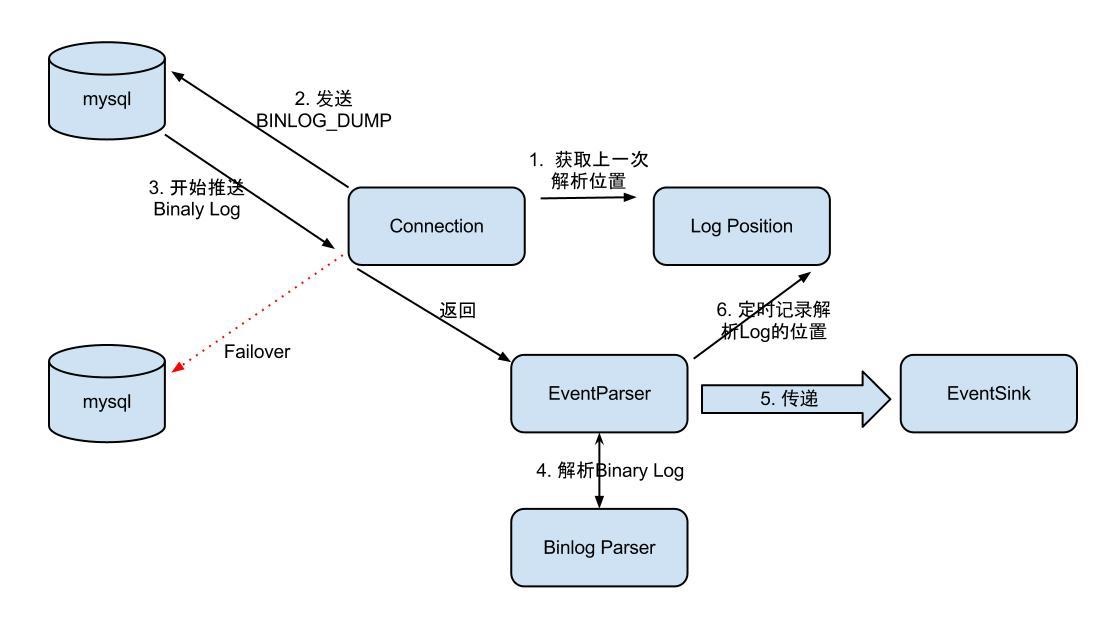
整个parser过程大致可分为几步:
eventSink 数据的归集,使用设置的filter对bin log进行过滤,工作的过程如下。
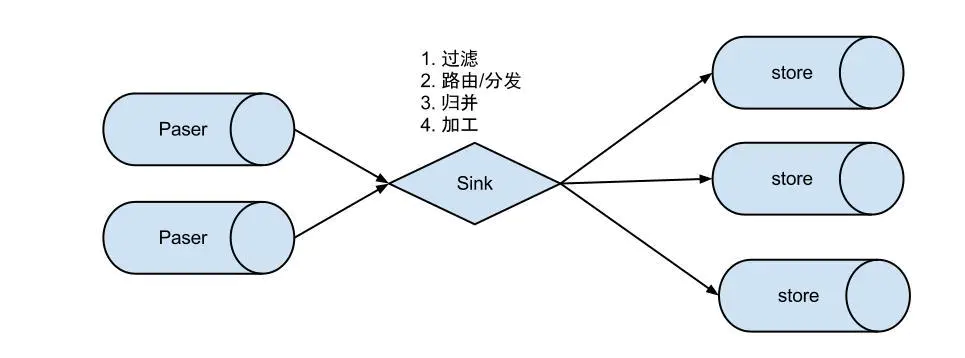
说明:数据过滤:支持通配符的过滤模式,表名,字段内容等
eventStore 用来存储filter过滤后的数据,canal目前的数据只在这里存储,工作流程如下
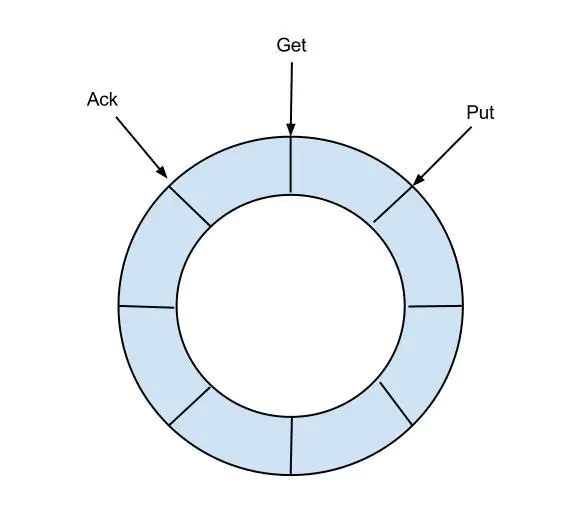
定义了3个cursor
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
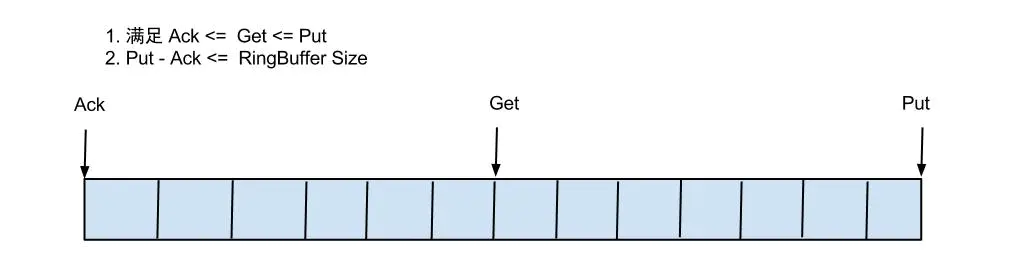
实现说明:
metaManager 用来存储一些原数据,比如消费到的游标,当前活动的server等信息alarmHandler
alarmHandler 报警,这个一般情况下就是错误日志,理论上应该是可以定制成邮件等形式,但是目前不支持各个组件目前支持的类型
canal采用了spring bean container的方式来组装一个canal instance ,目的是为了能够更加灵活。canal通过这些组件的选取可以达到不同使用场景的效果,比如单机的话,一般使用file来存储metadata就行了,HA的话一般使用zookeeper来存储metadata。
eventParser 目前只有三种
eventSink 目前只有EntryEventSink 就是基于mysql的binlog数据对象的处理操作eventStore
eventStore 目前只有一种 MemoryEventStoreWithBuffer,内部使用了一个ringbuffer 也就是说canal解析的数据都是存在内存中的,并没有到zookeeper当中。metaManager
metaManager 这个比较多,其实根据元数据存放的位置可以分为三大类,memory,file,zookeeperCanal-HA机制
canal是支持HA的,其实现机制也是依赖zookeeper来实现的,用到的特性有watcher和EPHEMERAL节点(和session生命周期绑定),与HDFS的HA类似。canal的ha分为两部分,canal server和canal client分别有对应的ha实现
server ha的架构图如下
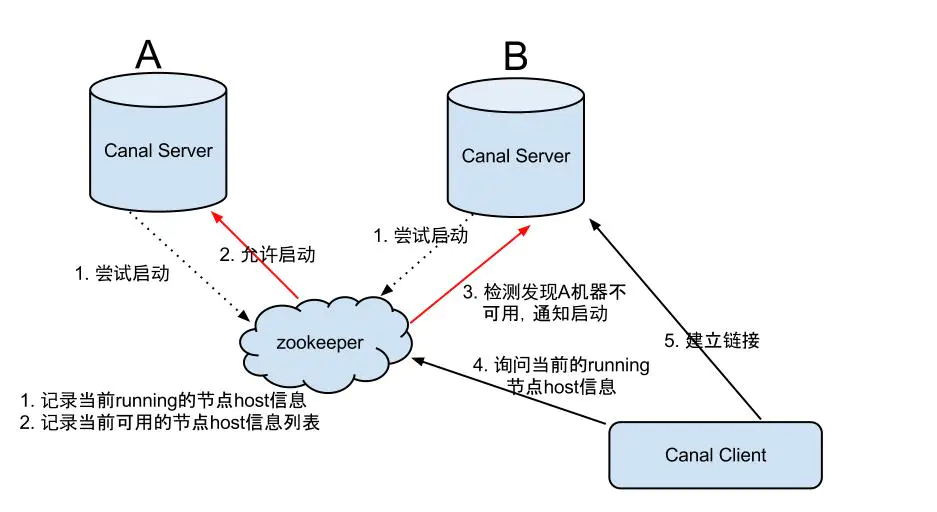
大致步骤:
启动时去MySQL 进行dump操作的binlog 位置确定工作的过程。在启动一个canal instance 的时候,首先启动一个eventParser 线程来进行数据的dump 当他去master拉取binlog的时候需要binlog的位置,这个位置的确定是按照如下的顺序来确定的(这个地方讲述的是HA模式哈)。
mysql的show master status 操作
数据在dump回来之后进行的归集(sink)和存储(store)sink操作是可以支撑将多个eventParser的数据进行过滤filter
配置父目录:
在下面可以看到
这里是全部展开的目录
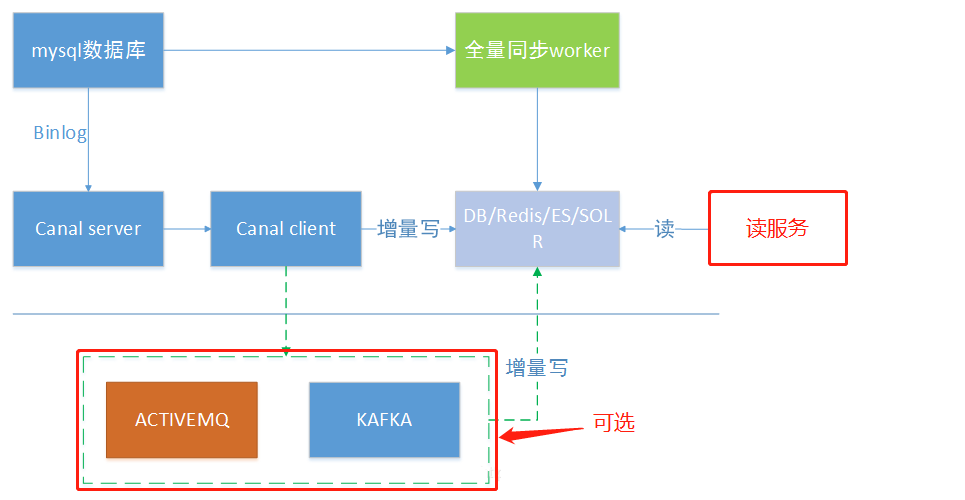
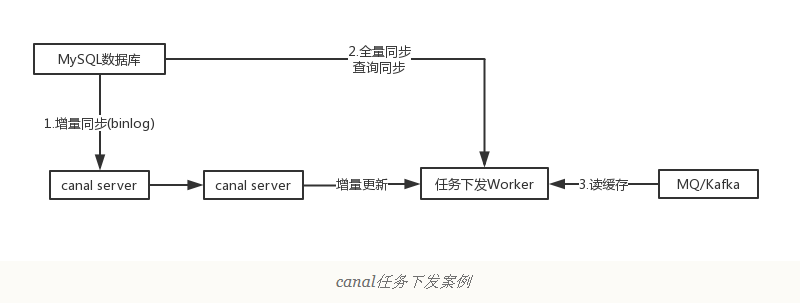
canal一个常见应用场景是同步缓存/全文搜索,当数据库变更后通过binlog进行缓存/ES的增量更新。当缓存/ES更新出现问题时,应该回退binlog到过去某个位置进行重新同步,并提供全量刷新缓存/ES的方法,如下图所示。
本文由传智教育博学谷狂野架构师教研团队发布。
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。
转载请注明出处!
| 欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |