本文是 Uber 的工程师 Gergely Orosz 的文章,原文地址在:https://blog.pragmaticengineer.com/operating-a-high-scale-distributed-system/在过去的几年里,我一直在构建和运营一个大型分布式系统:优步的支付系统。在此期间,我学到了很多关于分布式架构概念的知识,并亲眼目睹了高负载和高可用性系统运行的挑战(一个系统远远不是开发完了就完了,线上运行的挑战实际更大)。构建系统本身是一项有趣的工作。规划系统如何处理10x / 100x流量的增加,确保数据持久,面对硬件故障处理等等,这些都需要智慧。不管怎样,运维大型分布式系统对我来说是一次令人大开眼界的体验。
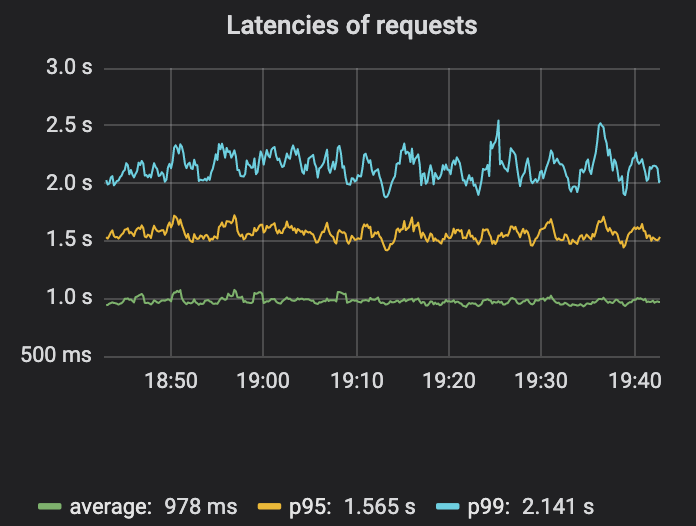
译者注:业务指标监控这一点,我们实在是太深有同感了,之前在滴滴有时就是发现所有服务都正常,但是业务不好使。我们现在创业做的北极星系统,就是专门应对这个问题的。感兴趣的朋友可以在公众号后台给我留言,或加我好友 picobyte 交流试用。Oncall,异常检测和警报
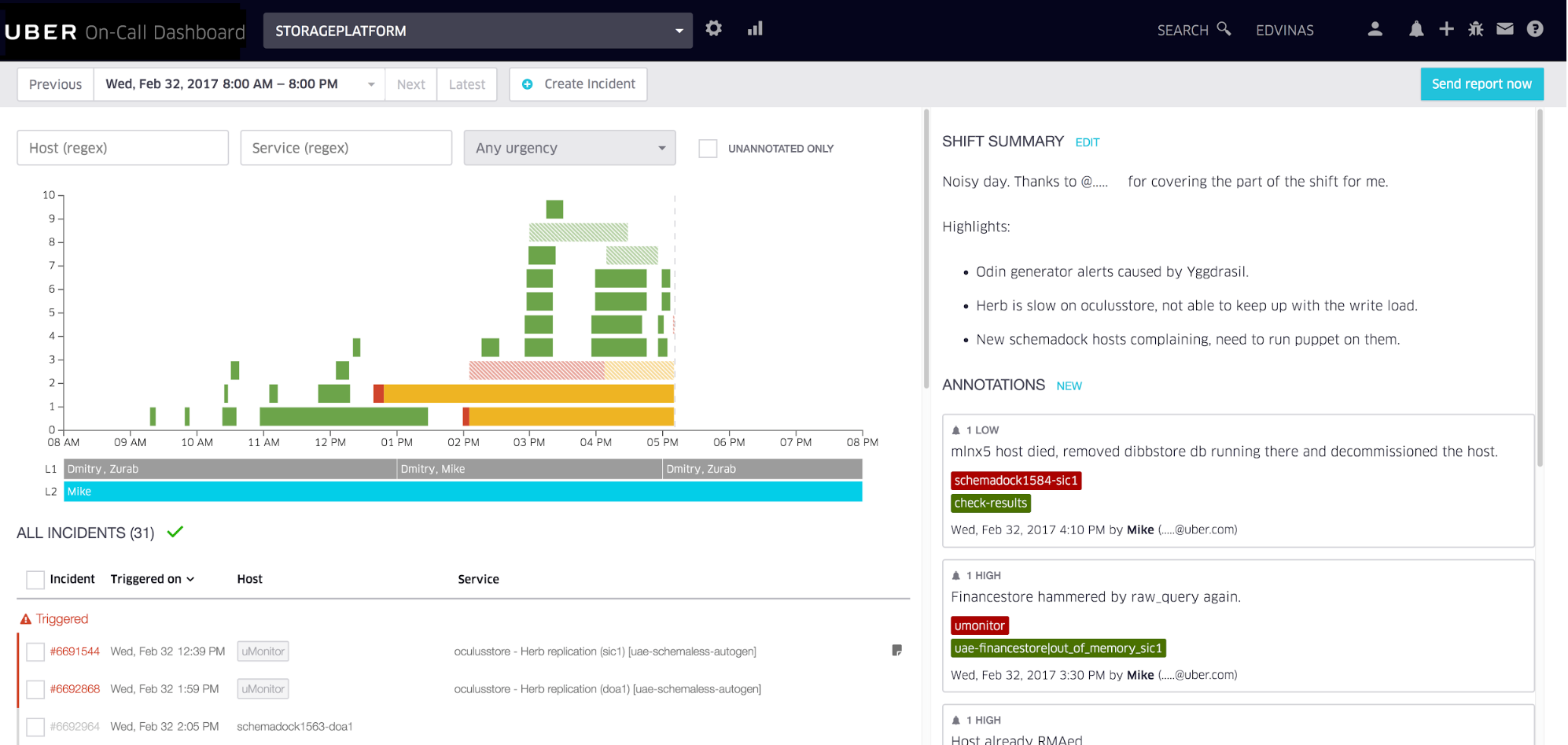
译者注:告警事件的聚合、降噪、排班、认领、升级、协同、灵活的推送策略、多渠道推送、和IM打通,是很通用的需求,可以参考 FlashDuty 这个产品,体验地址:https://console.flashcat.cloud/故障和事件管理流程
译者注:Nightingale 和 Grafana 的告警规则配置中,可以支持自定义字段,但是有些附加字段是默认就会提供的,比如 RunbookUrl,核心就是想传达SOP手册的重要性。另外,稳定性治理体系里,告警规则是否预置了RunbookUrl,是一个很重要的告警健康度的衡量指标。一旦有超过几个部署服务的团队,跨组织进行故障交流就变得至关重要。在我工作的环境中,成千上万的工程师会根据自己的判断将他们所开发的服务部署到生产环境中,每小时可能会有数百次部署。一个看似不相关的服务部署可能会影响另一个服务。在这种情况下,标准化的故障广播和通信渠道可以起到很大作用。我曾经遇到过多种罕见的警报信息 - 意识到其他团队中的人也看到了类似奇怪现象。通过加入一个集中式聊天群组来处理故障,我们迅速确定了导致故障的服务并解决了问题。我们做得比任何单独一人更快地完成了任务。

译者注:这一点老司机应该也深有感触,不要在线上Debug,出现问题立即回滚而不是尝试发布hotfix版本来修复!事后分析,事件回顾和持续改进文化
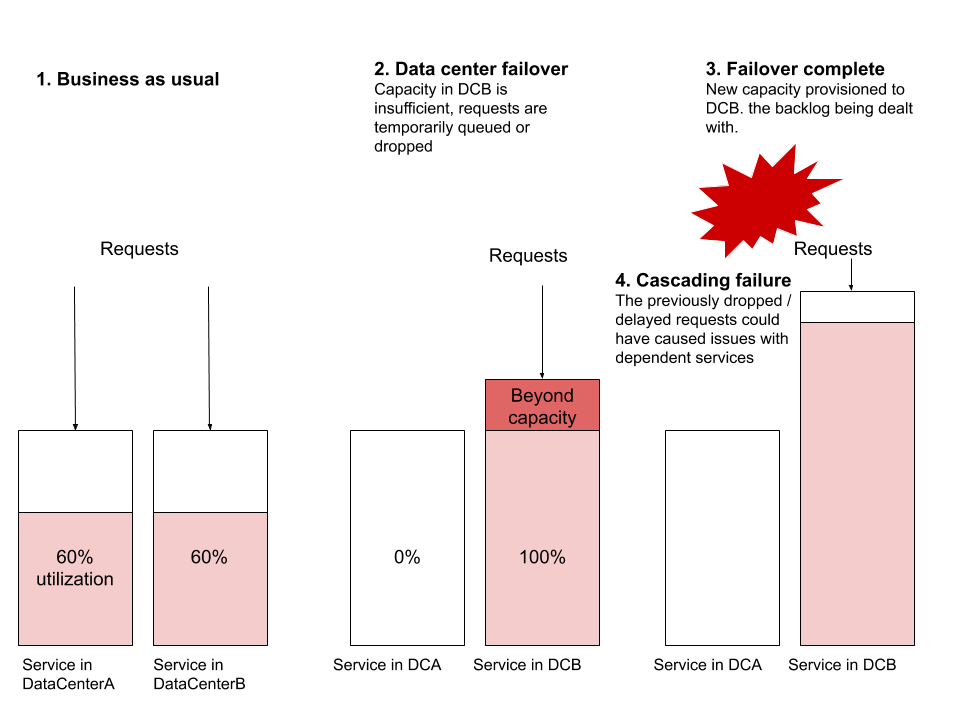
译者注:切流量,本就是预案“三板斧”之一。出故障的时候,要保证预案是可用的,那平时就少不了演练。重视起来吧,老铁们。计划的服务停机时间练习是测试整个系统弹性的极好方法。这些也是发现特定系统的隐藏依赖项或不适当/意外使用的好方法。虽然对于面向客户且依赖较少的服务,这种练习相对容易完成,但是对于需要高可用性或被许多其他系统所依赖的关键系统来说,则不那么容易喽。但是,当某一天这个关键系统不可用时会发生什么?最好通过受控演练来验证答案,所有团队都知道并准备好应对意外中断。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |