迎面走来了你的面试官,身穿格子衫,挺着啤酒肚,发际线严重后移的中年男子。
手拿泡着枸杞的保温杯,胳膊夹着MacBook,MacBook上还贴着公司标语:“加班使我快乐”。

这个问题难不住我啊。来之前我看一下一灯MySQL八股文。我: 举个例子:有这么一张用户表
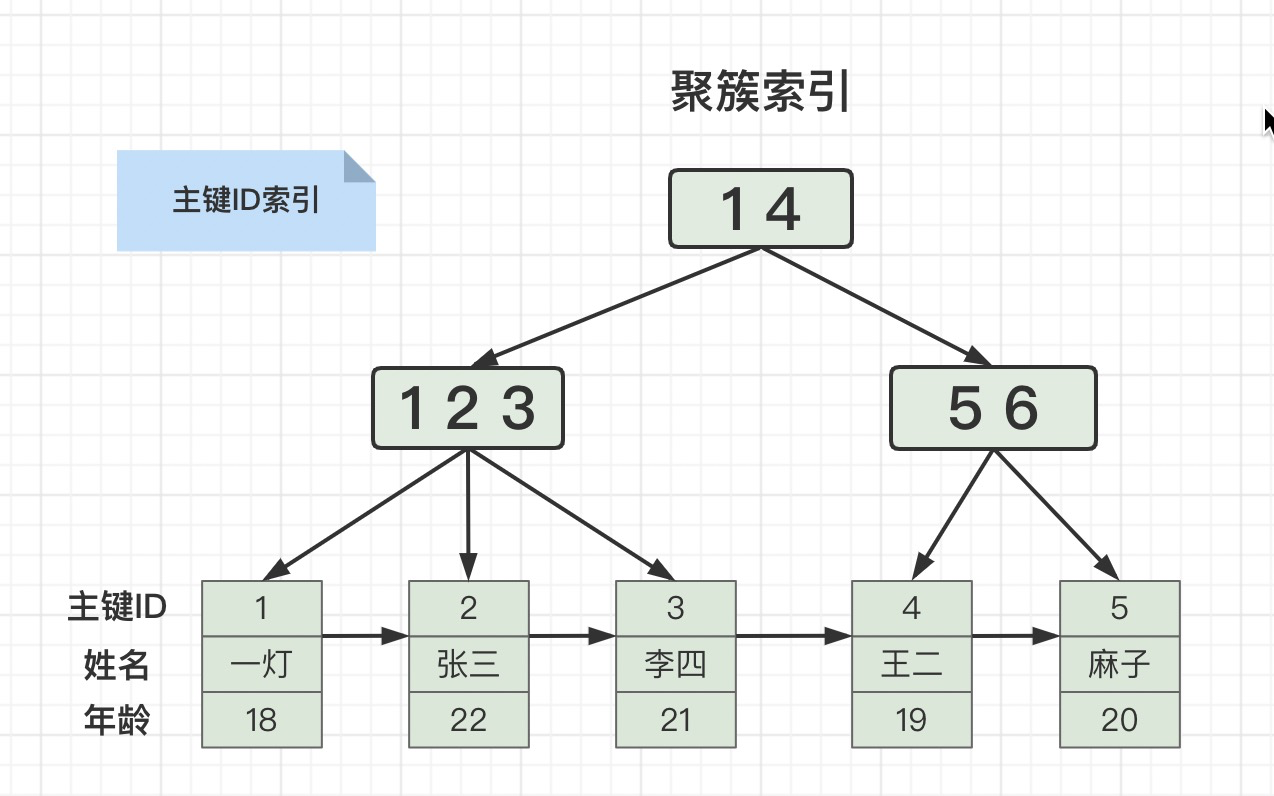
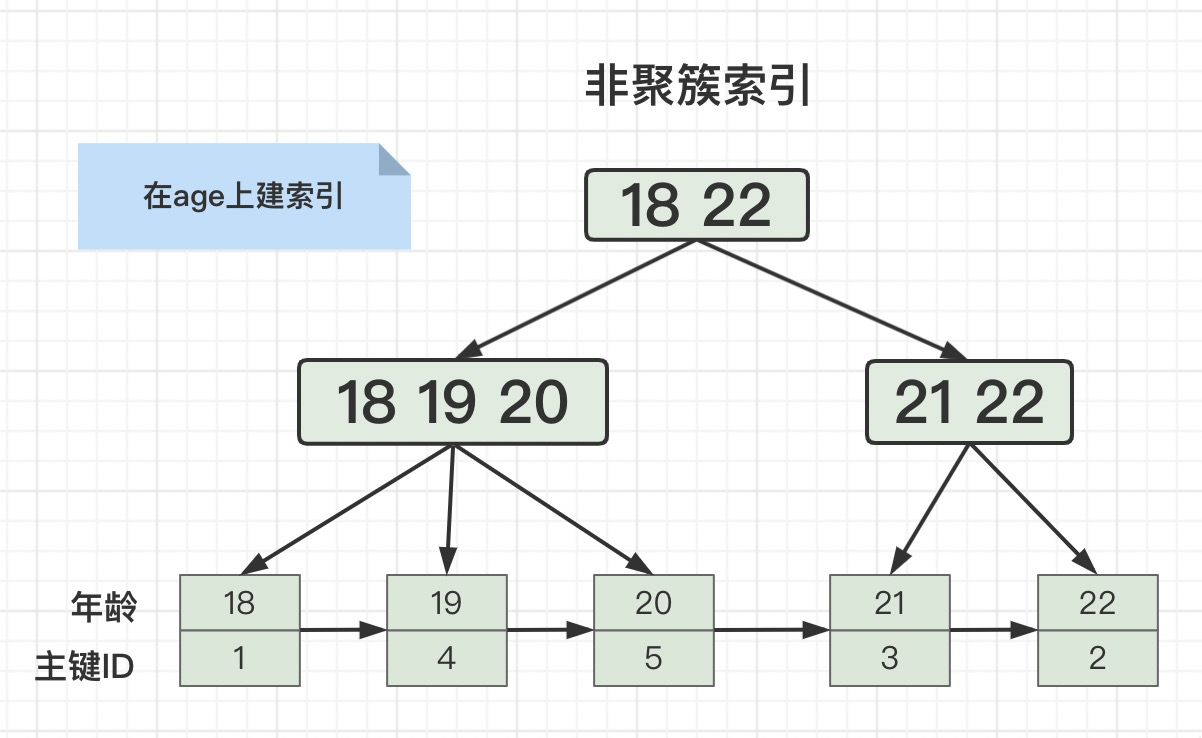
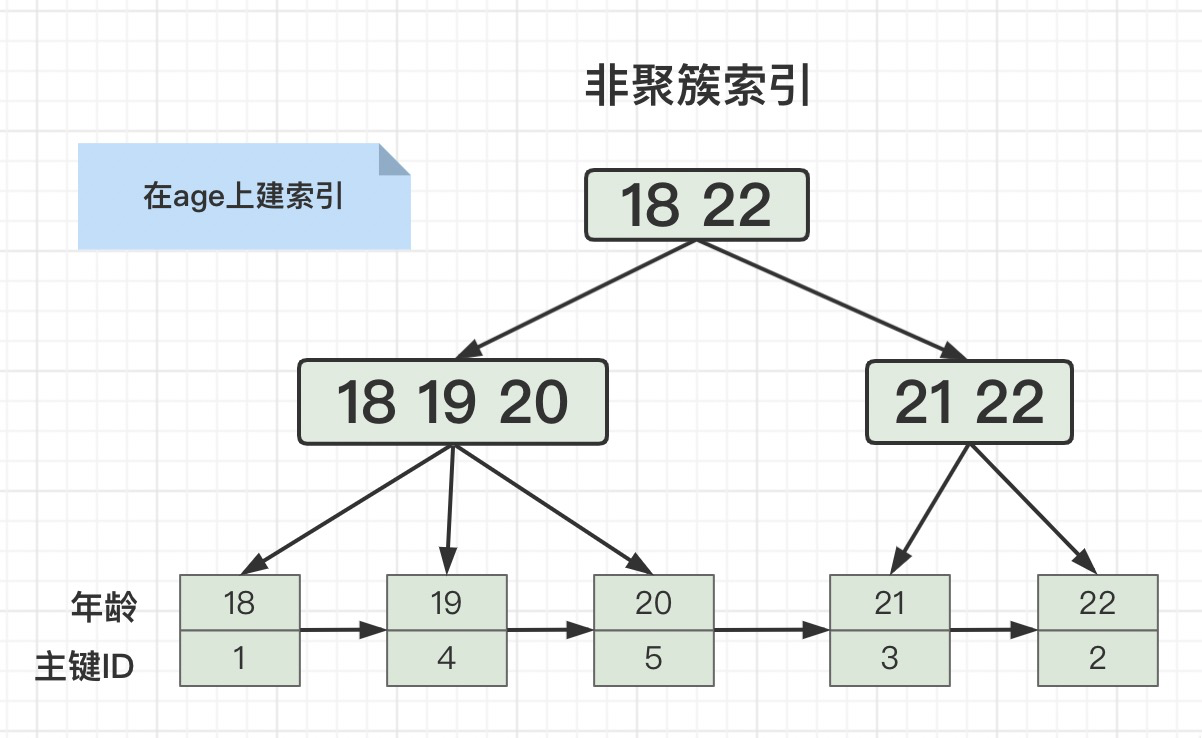
这么冷门的问题,你都问的出来,真的要面试造火箭啊!我: 索引下推(Index Condition Pushdown)是MySQL5.6引入的一个优化索引的特性。
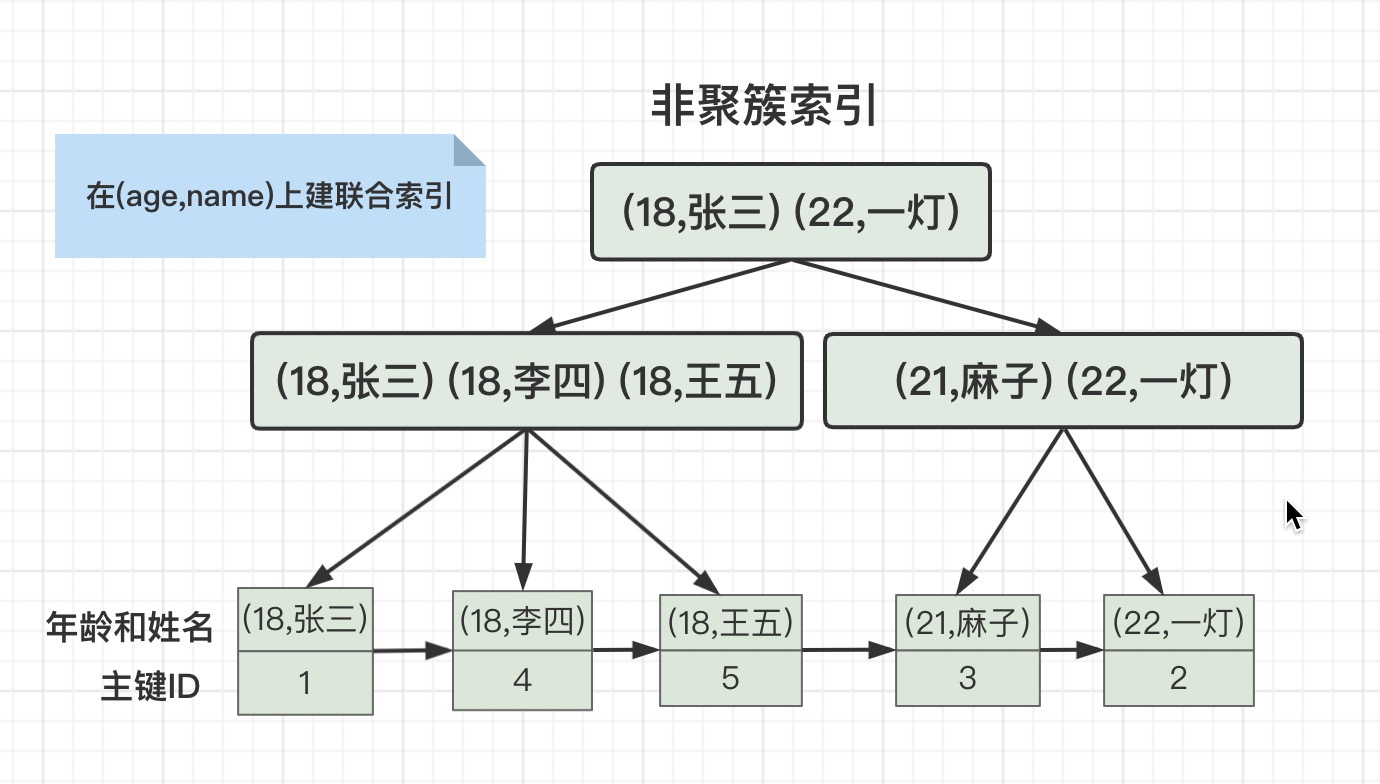
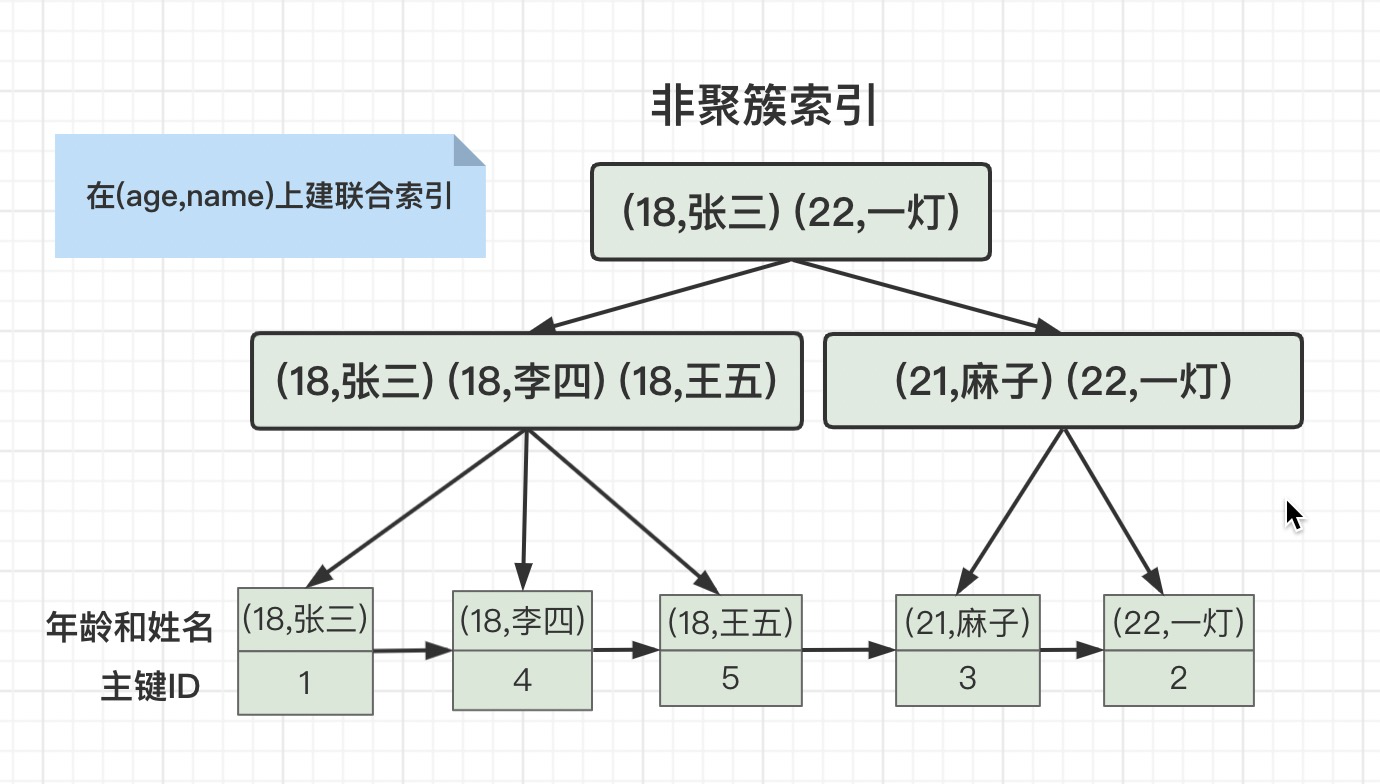
故意刁难我?你以为实战题就不能背八股文了吗?我: 刚才在讲联合索引的时候已经说了这个知识点了,where条件有b和c的等值查询,联合索引就建成(b,c),由于select后面有a,我们就建立 (b,c,a) 的联合索引,并且可以用到覆盖索引,查询速度更快。
文章持续更新,可以微信搜一搜「 一灯架构 」第一时间阅读更多技术干货。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |