本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~既然Redis那么快,为什么不用它做主数据库,只用它做缓存?
Github地址
如果访问不了Github,可以访问gitee地址。
gitee地址
给大家分享一个Github仓库,上面有大彬整理的300多本经典的计算机书籍PDF,包括C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~Memcached和Redis的区别?
Github地址
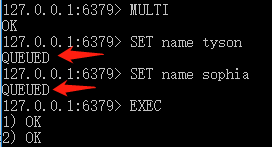
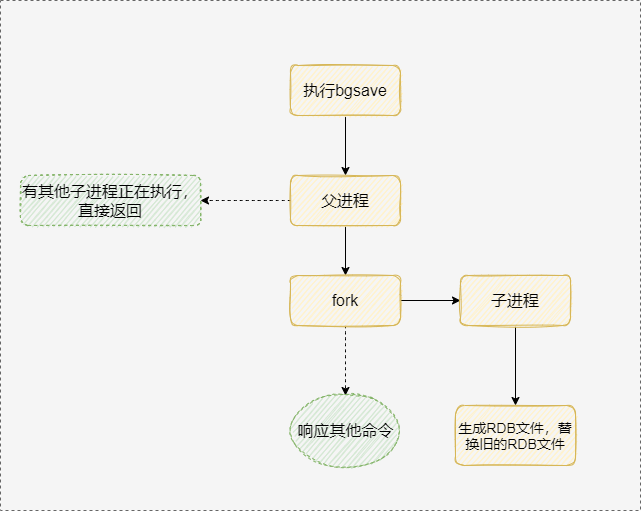
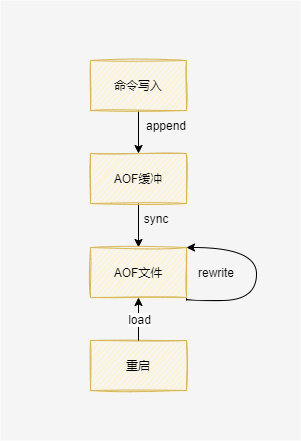
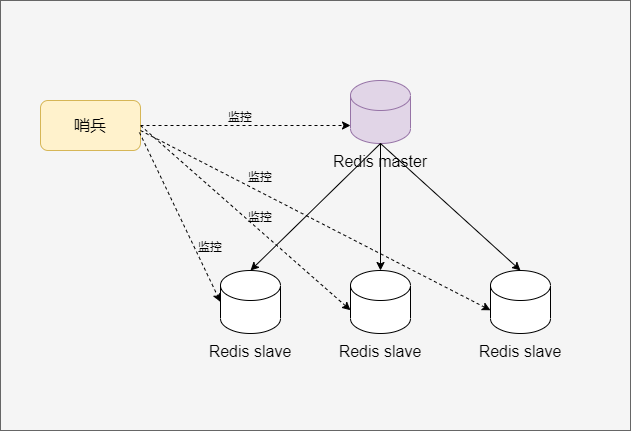
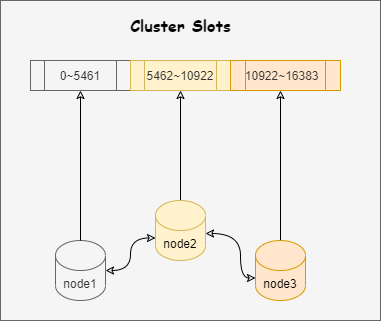
BLPOP和LPOP命令相似,唯一的区别就是当列表没有元素时BLPOP命令会一直阻塞连接,直到有新元素加入。redis可以通过pub/sub主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
PSUBSCRIBE channel?* 按照规则订阅。Redis 怎么实现延时队列
PUNSUBSCRIBE channel?* 退订通过PSUBSCRIBE命令按照某种规则订阅的频道。其中订阅规则要进行严格的字符串匹配,PUNSUBSCRIBE *无法退订channel?*规则。
| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |