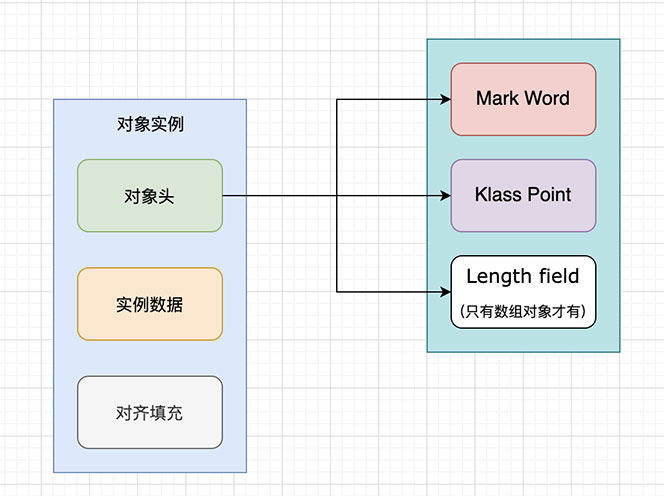
对象头分为Mark Word(标记字)和Class Pointer(类指针),如果是数组对象还得再加一项Array Length(数组长度)。
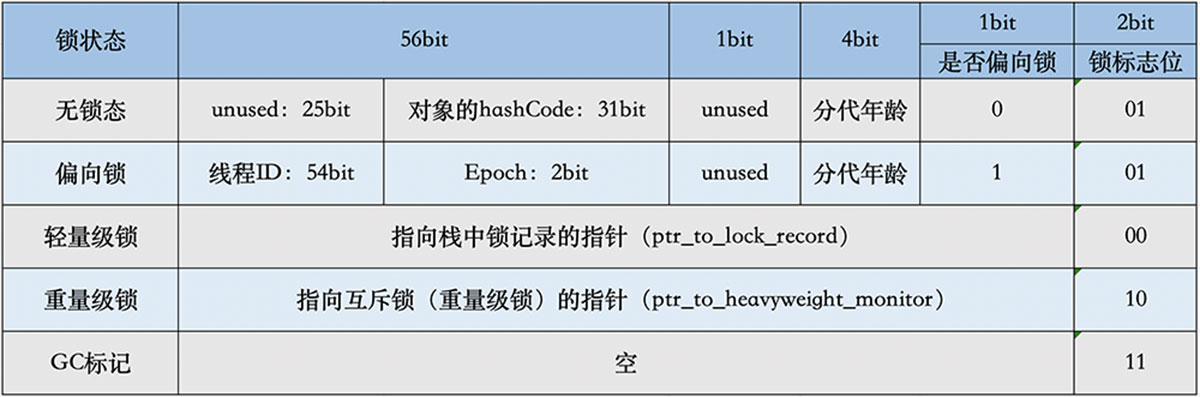
Mark Word
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
Mark Word在32位JVM中的长度是32bit,在64位JVM中长度是64bit。我们打开openjdk的源码包,对应路径/openjdk/hotspot/src/share/vm/oops,Mark Word对应到C++的代码markOop.hpp,可以从注释中看到它们的组成,本文所有代码是基于Jdk1.8。