摘要:本文对Lazy Agg查询重写优化和GaussDB(DWS)提供的Lazy Agg重写规则进行介绍。本文分享自华为云社区《GaussDB(DWS) lazyagg查询重写优化解析【这次高斯不是数学家】》,作者: OreoreO 。
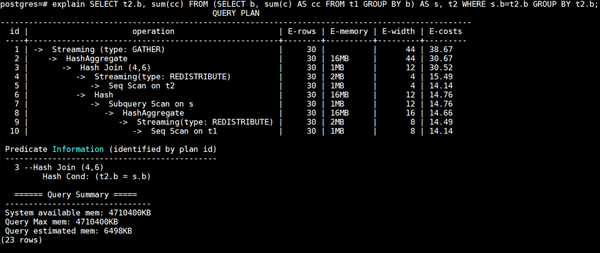 lazyagg重写优化后计划如下所示:
lazyagg重写优化后计划如下所示: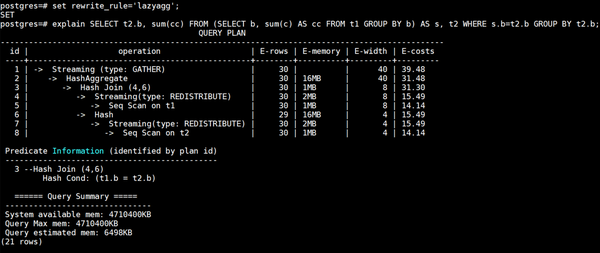 可以看到相比于原计划,lazyagg重写优化后消除掉了原计划中的聚集操作,即7号Subquery Scan算子和8号HashAggregate算子。
可以看到相比于原计划,lazyagg重写优化后消除掉了原计划中的聚集操作,即7号Subquery Scan算子和8号HashAggregate算子。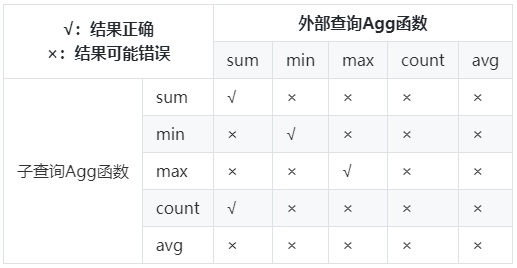 4. 场景约束
4. 场景约束| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |