摘要:本文以华为云图引擎 GES 为例,来介绍如何使用图查询语言 Cypher 表达一些需要做数据局部遍历的场景。本文分享自华为云社区《使用 Cypher 子查询进行图探索 -- 以华为云图引擎 GES 为例》,作者:蜉蝣与海。
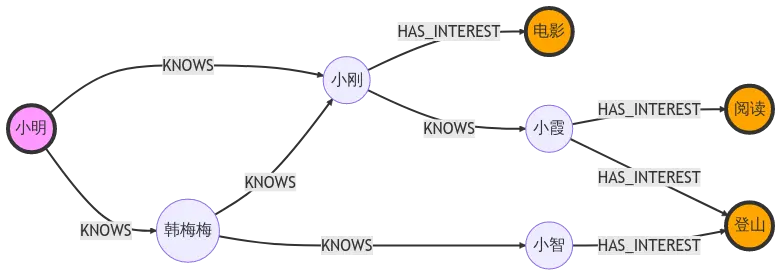 这些查询往往只关注图中的某个局部,对局部进行多跳查询,且局部上往往有类似下列限制:
这些查询往往只关注图中的某个局部,对局部进行多跳查询,且局部上往往有类似下列限制: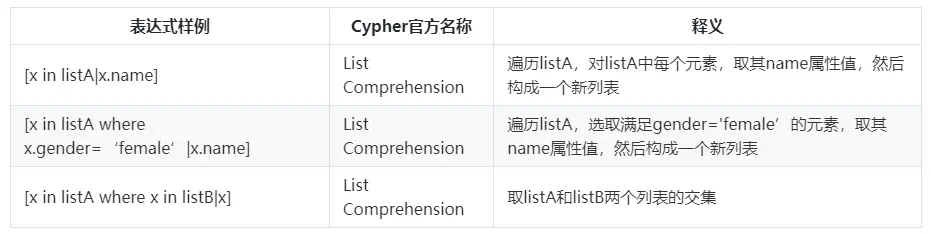 下方三个小节会指导如何配置一个 GES 实例并使用 notebook 连接 GES 服务进而做查询演示。如果你只想了解如何编写查询语句,对输入的 Cypher 查询获取返回结果没有需求,可以直接跳过下方三个小节。
下方三个小节会指导如何配置一个 GES 实例并使用 notebook 连接 GES 服务进而做查询演示。如果你只想了解如何编写查询语句,对输入的 Cypher 查询获取返回结果没有需求,可以直接跳过下方三个小节。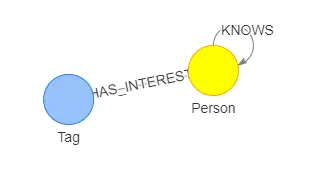 如图是本文使用的数据集的 schema,主要包括下列类型的点边:
如图是本文使用的数据集的 schema,主要包括下列类型的点边: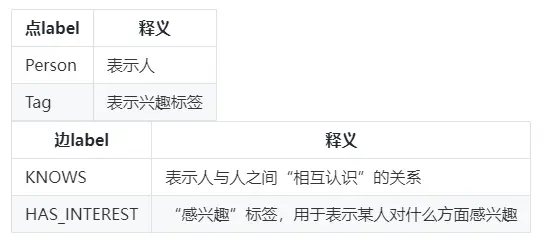 使用子查询
使用子查询







| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |