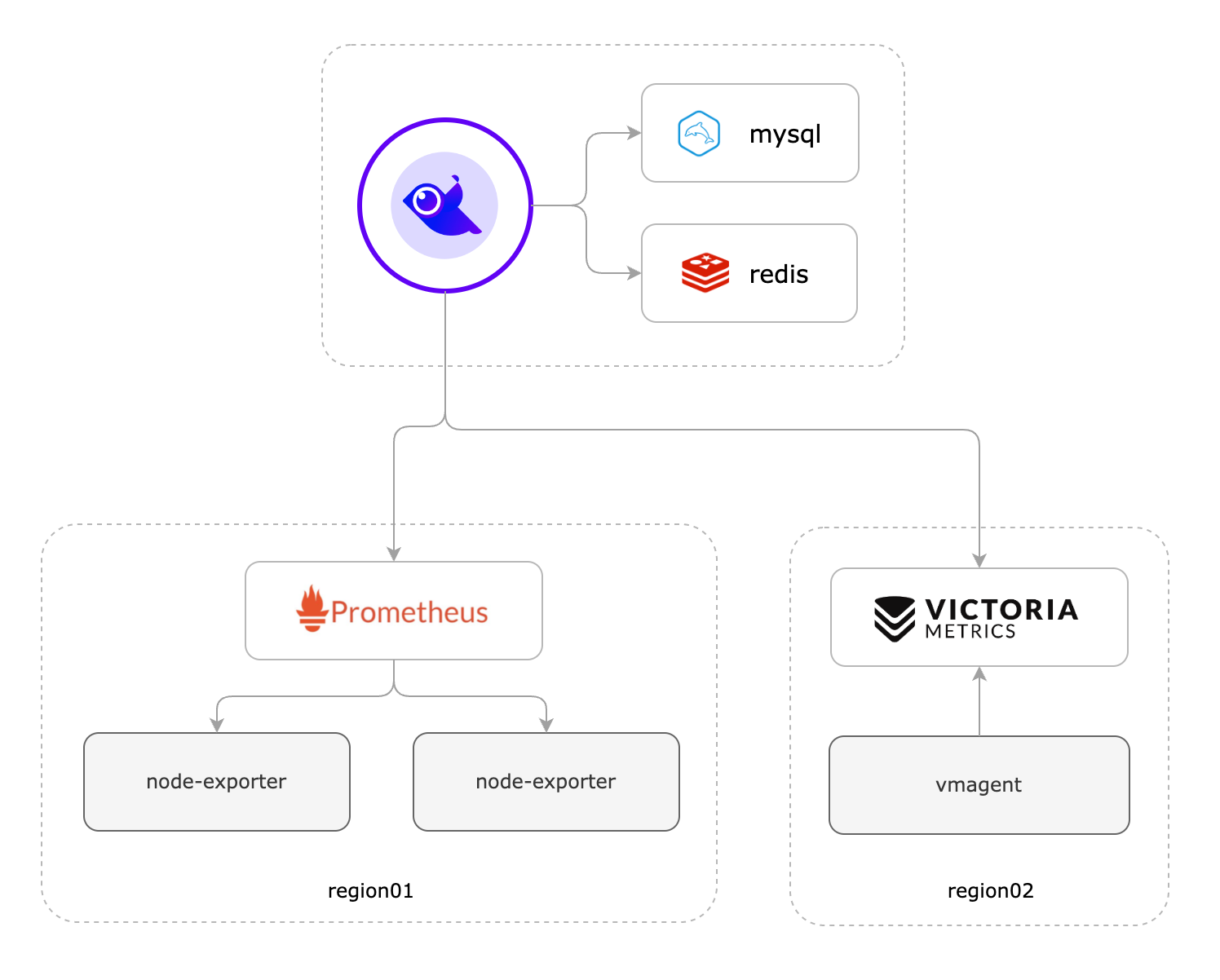
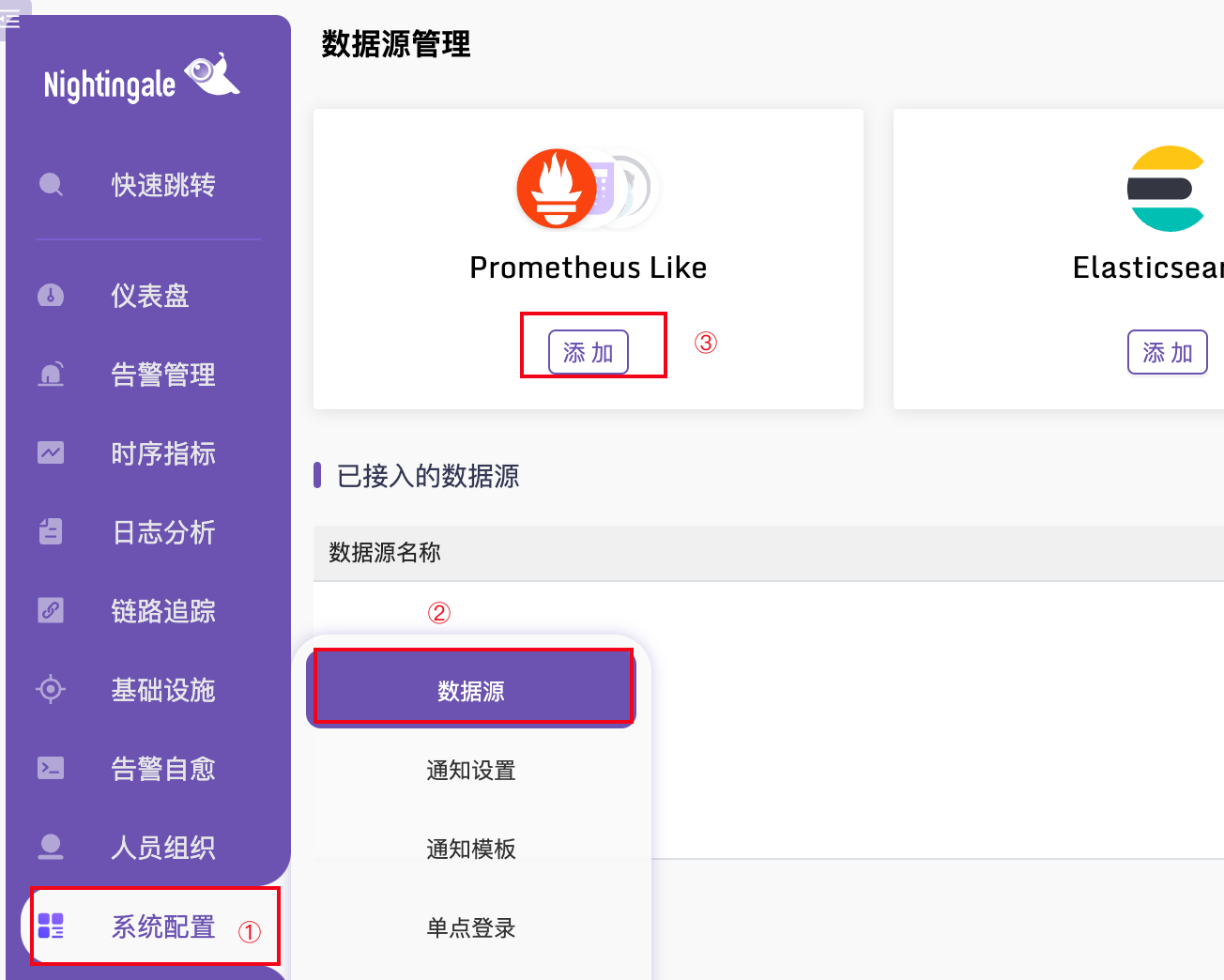
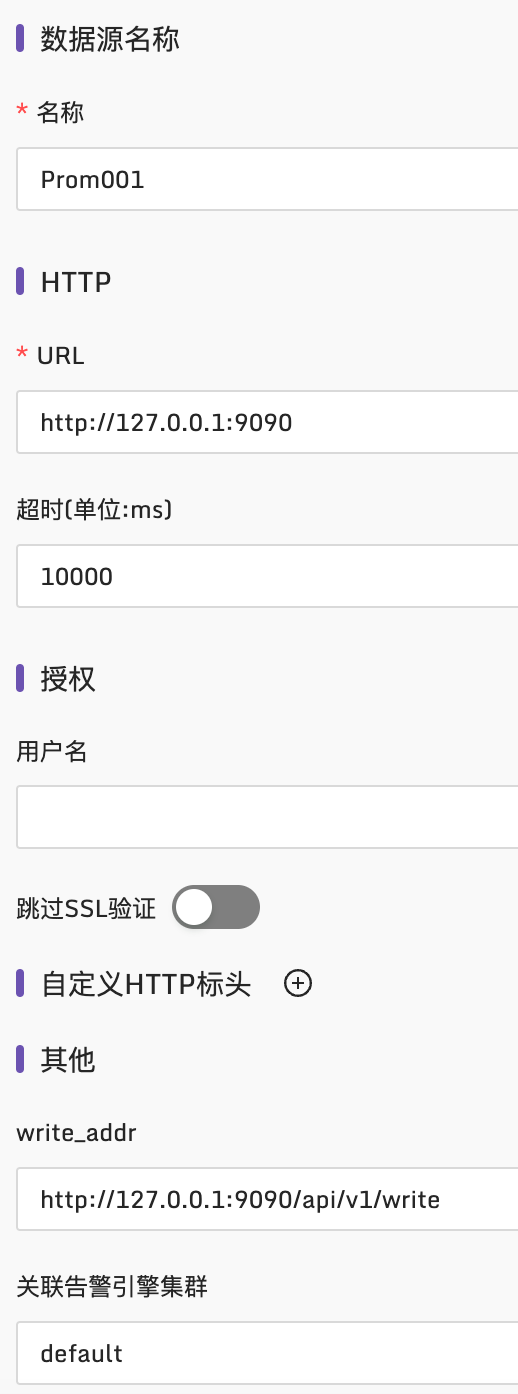
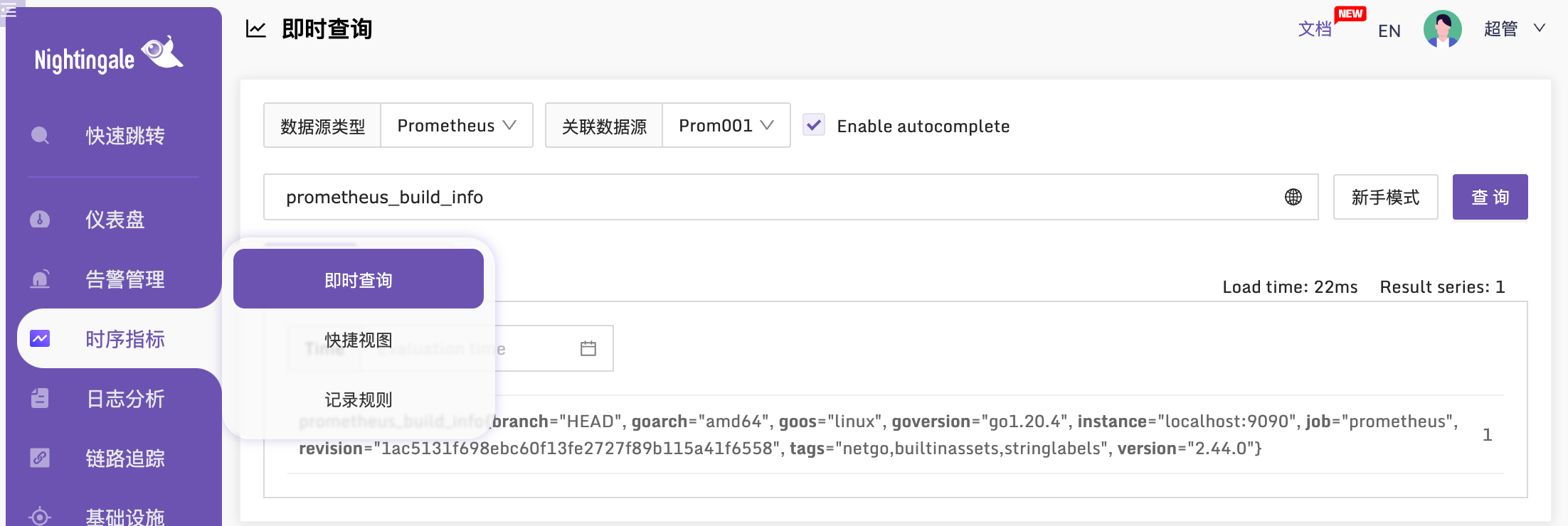
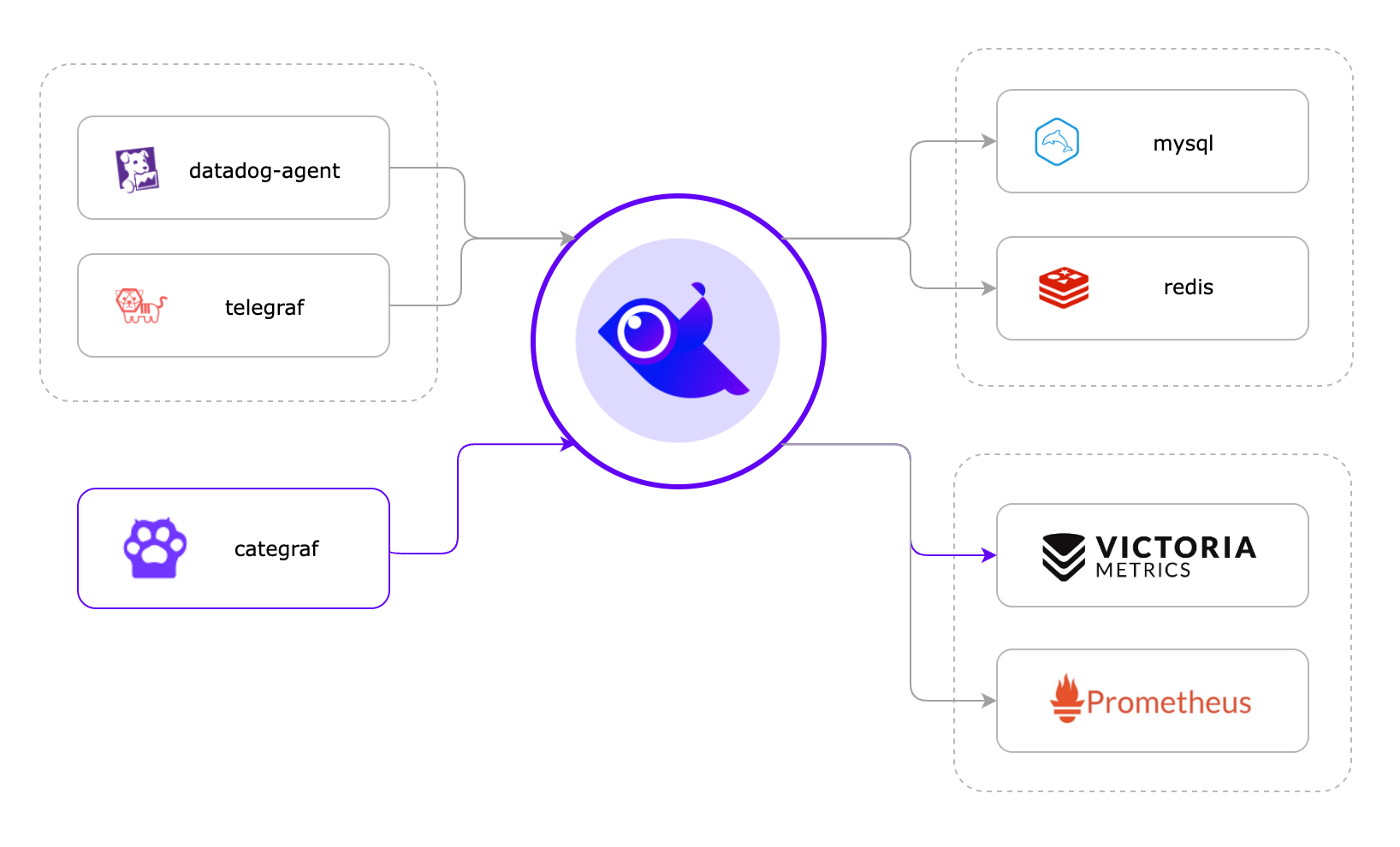
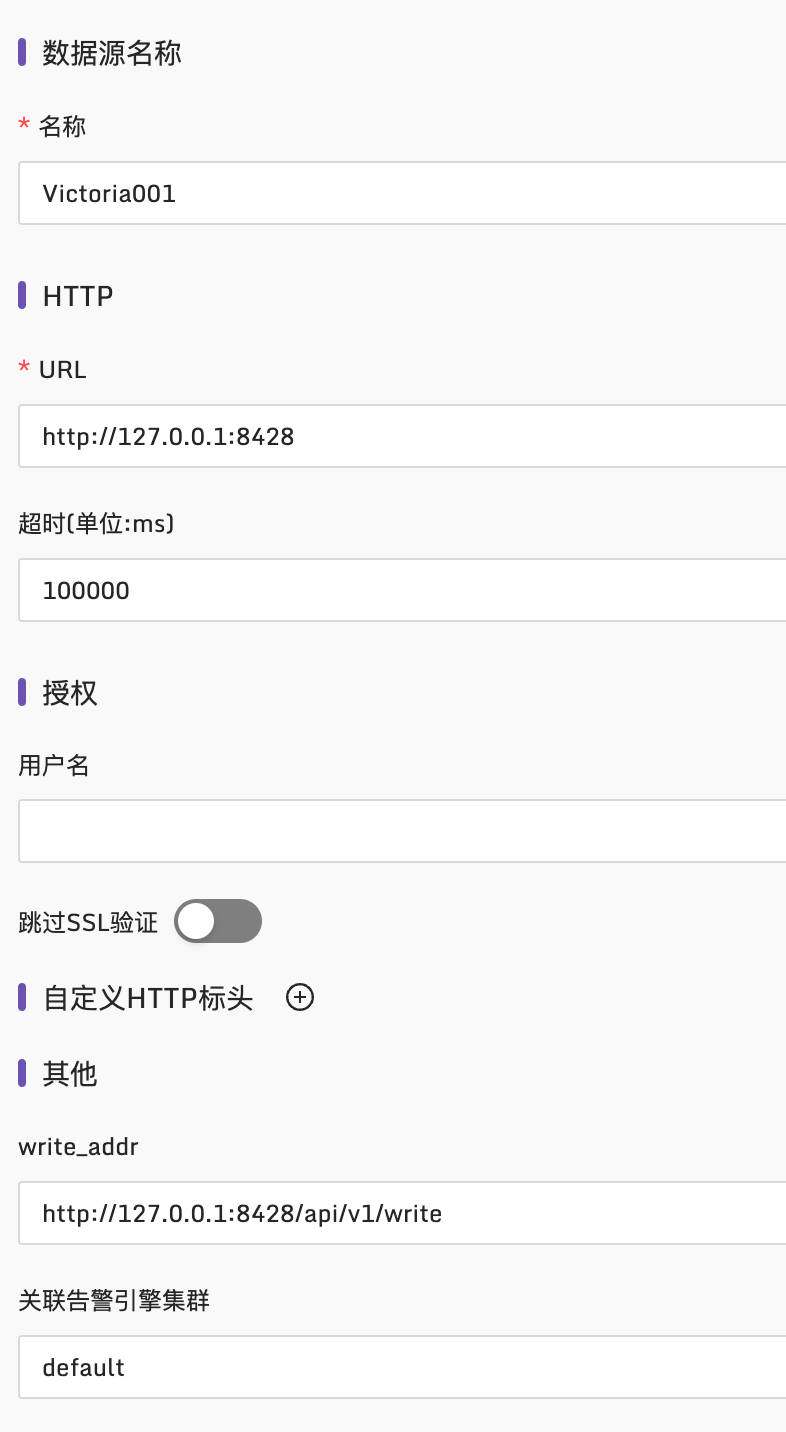
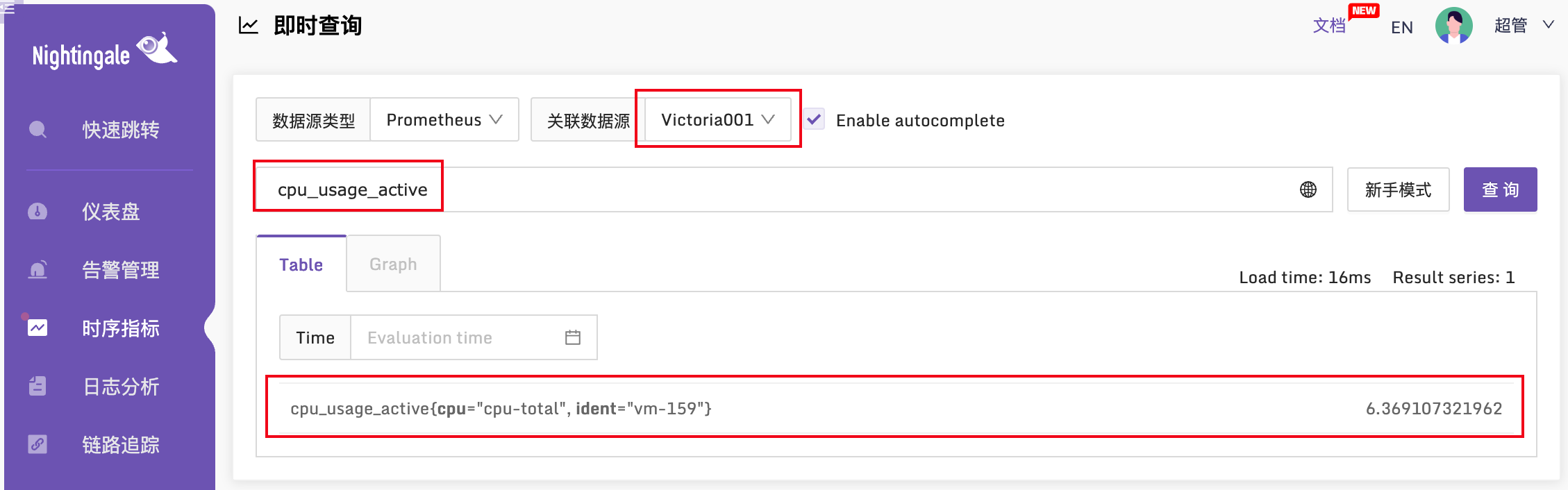
如果夜莺里配置了3千条告警规则,部署了3个n9e实例,这三个n9e实例就会自动分配(通过一致性哈希算法)要处理的告警规则,确保每个n9e实例只处理大概1千条告警规则,分担告警引擎处理压力。如果某个n9e实例挂掉,其他实例会自动感知(利用mysql做了一些心跳机制)自动接管未被处理的告警规则,这也是把n9e集群化部署的好处。