摘要:在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。本文分享自华为云社区《【高并发】基于ReadWriteLock开了个一款高性能缓存》,作者:冰 河。
 读写锁
读写锁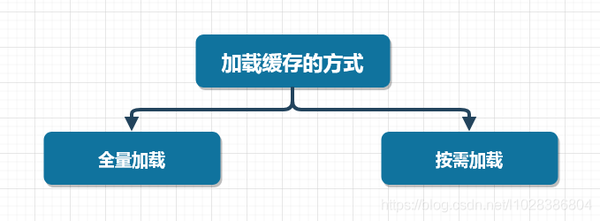 接下来,我们就分别来看看全量加载缓存和按需加载缓存的方式。
接下来,我们就分别来看看全量加载缓存和按需加载缓存的方式。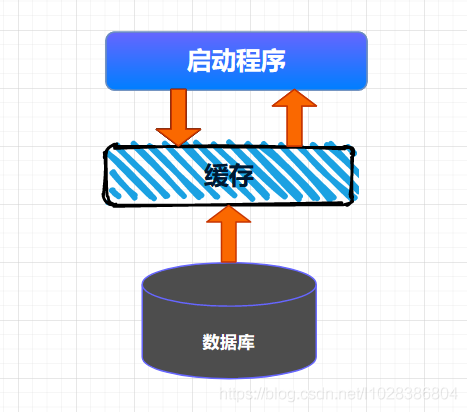 将数据全量加载到缓存后,后续就可以直接从缓存中读取相应的数据了。
将数据全量加载到缓存后,后续就可以直接从缓存中读取相应的数据了。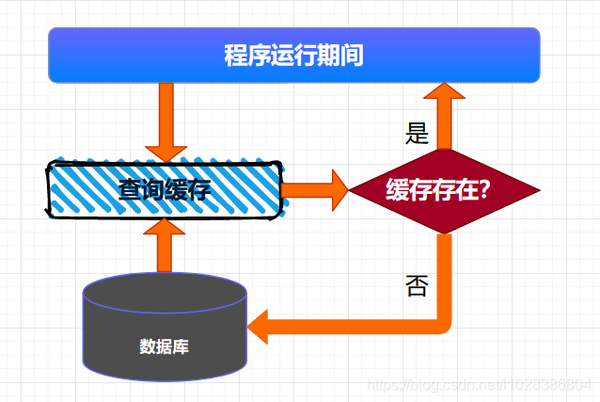 这种查询缓存的方式适用于大多数缓存数据的场景。
这种查询缓存的方式适用于大多数缓存数据的场景。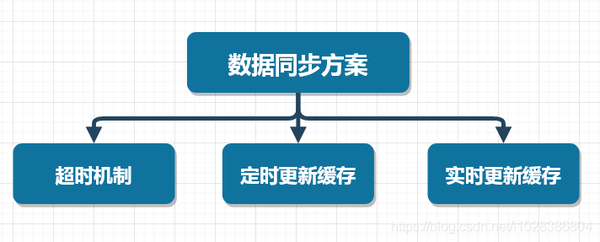 超时机制
超时机制| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |