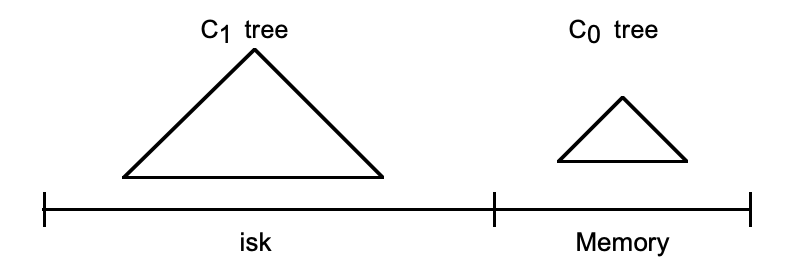
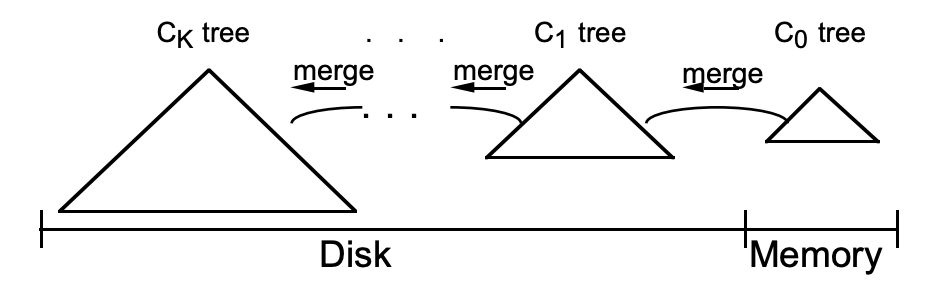

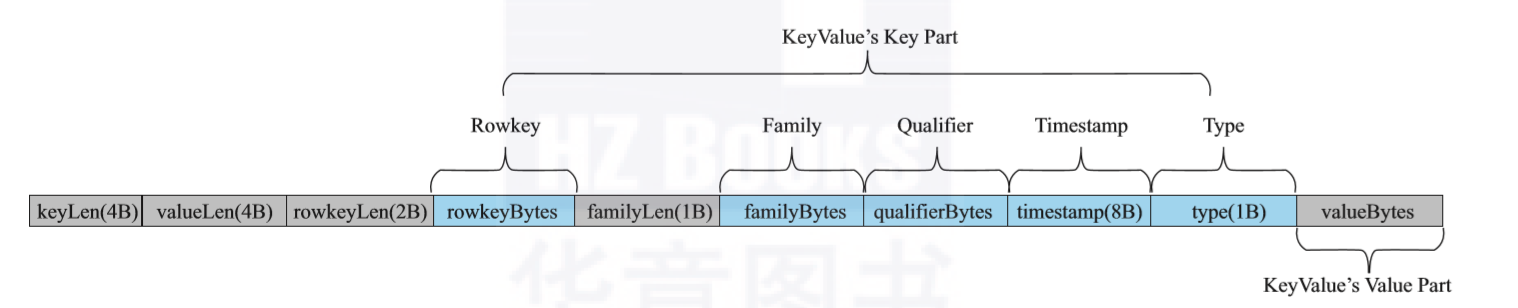
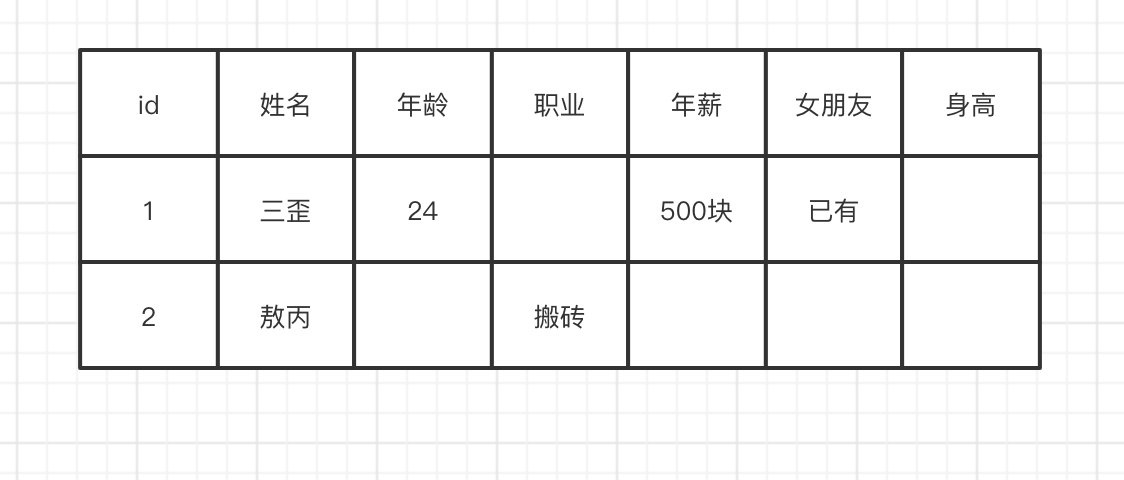

| 名称 | 命令表达式 |
| 查看存在哪些表 | list |
| 添加数据 | put '表名称', '行键', '列族 : 列名', '值' |
| 查看一行数据 | get '表名称', '行键' |
| 查看指定列族的一行数据 | get '表名称', '行键', '列族' |
| 查看指定列族及列名的数据 | get '表名称', '行键', '列族 : 列名', |
| 查看表中的数据总量 | count '表名' |
| 删除一个单元格的数据 | delete '表名' ,'行键' , '列族 : 列名' |
| 删除一行所有数据 | delete '表名' ,'行键' |
| 查看表的所有数据 | scan '表名'。注意,一般不应直接使用scan扫描整个表的海量数据。 |
| 查看一列数据 | scan '表名' , '列族 : 列名' |
| 查看帮助信息 | help |
| 欢迎光临 IT评测·应用市场-qidao123.com技术社区 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |