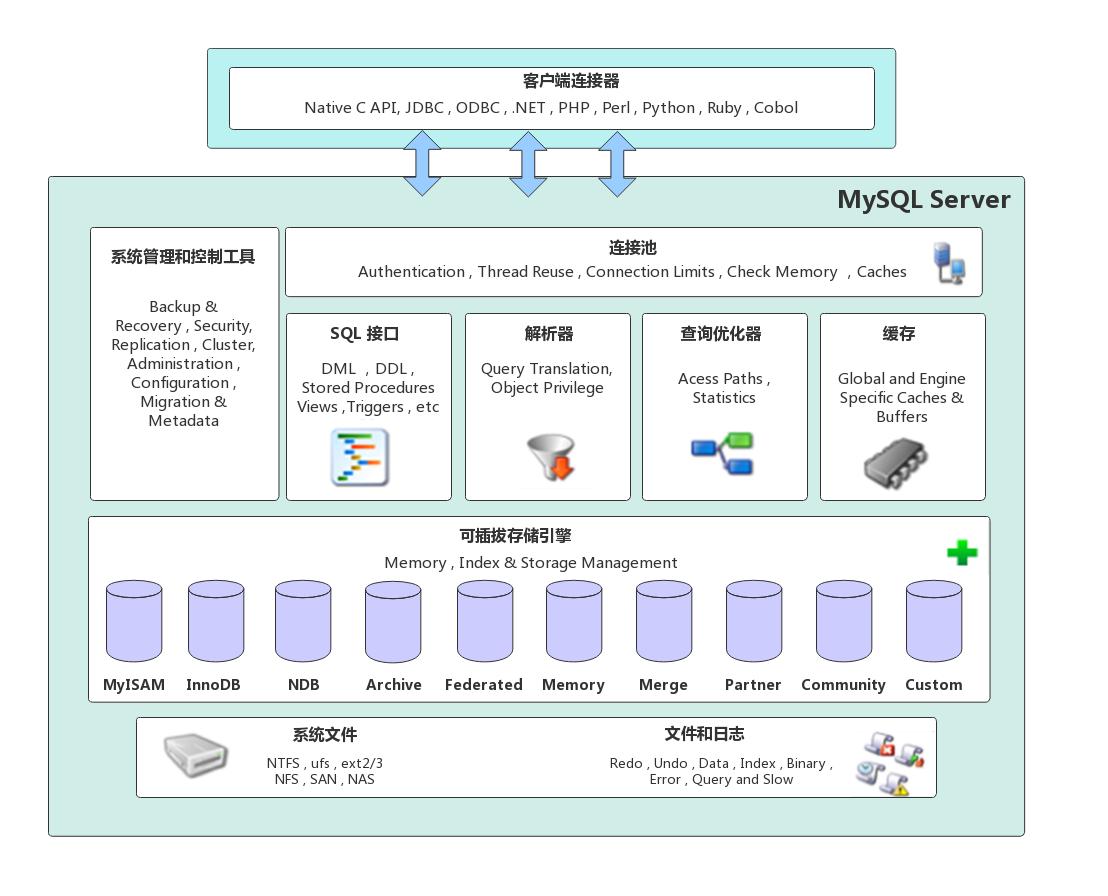
MySQL作为一个流行的开源关系型数据库管理系统,它可以运行在多种平台上,支持多种存储引擎,提供了灵活的数据操作和管理功能。MySQL的逻辑架构可以分为三层:连接层、服务层和引擎层,下方是网上流传度很广的一张架构图。
需要注意的是, 上图描述的是MySQL5.7及以前的逻辑架构,MySQL8.0中正式移除了查询缓存组件, 因为从收集的数据来看查询缓存的命中率很低,即使是在MySQL5.7中查询缓存这个选项也是默认关闭的,所以本篇文章就不对缓存这款内容做解析了。具体可以查看官方的一篇博客: MySQL :: MySQL 8.0:停用对查询缓存的支持
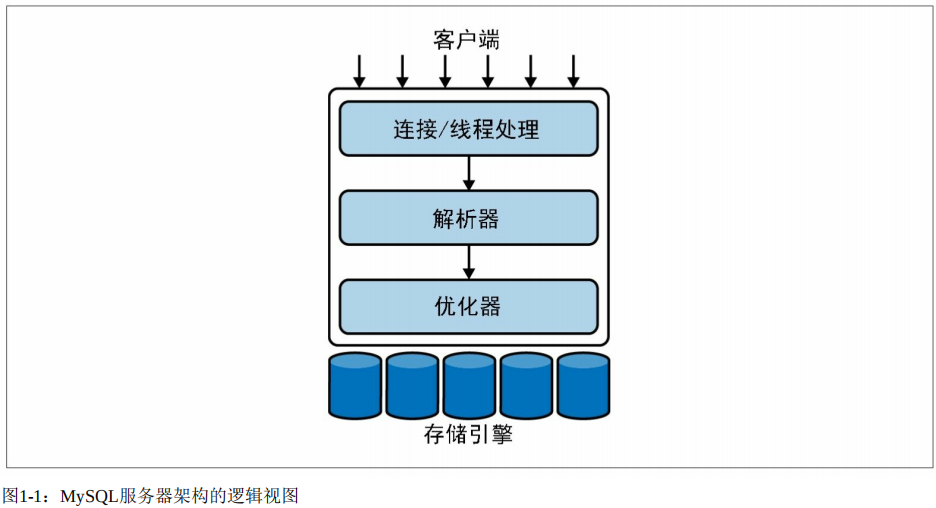
事实上,如果不去关注其内部的细节,《高性能MySQL》一书中的这张简图也足够让我们对其逻辑架构有一个直观的认知:
1、连接层详解