
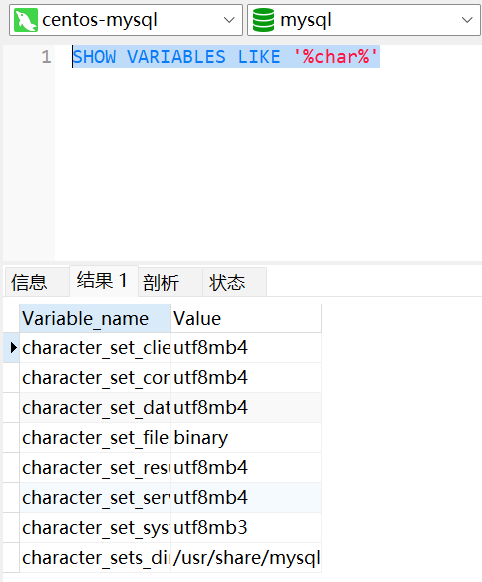
 2.2、utf8与utf8mb4
2.2、utf8与utf8mb4注意:不建议在开发过程中修改此参数,将会丢失所有数据4、sql_mode


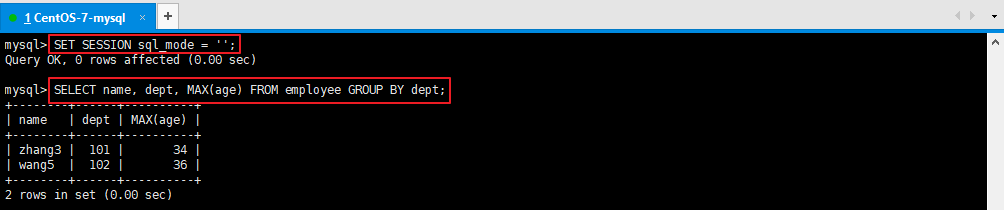





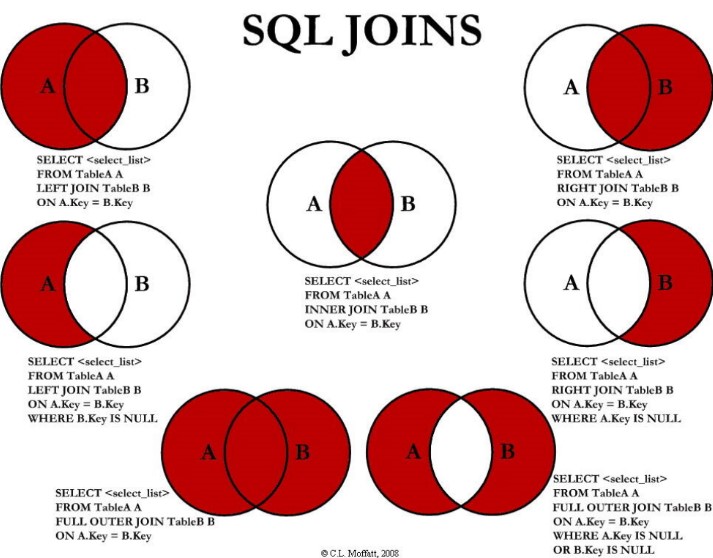
注意:
- UNION和UNION ALL要求字段数量和顺序都一致
- 如果确定两表结果不会重复,则使用UNION ALL提升效率

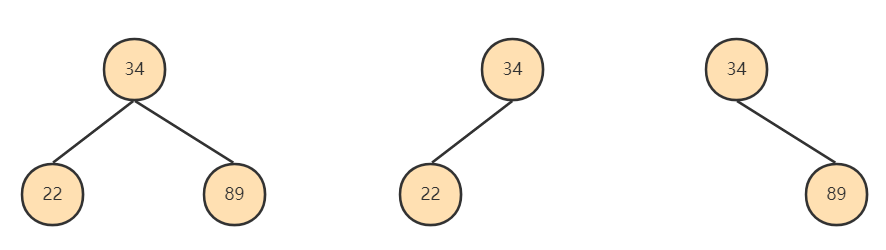
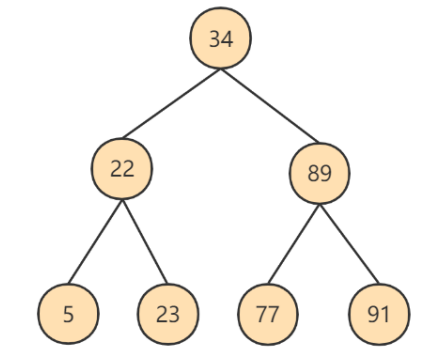
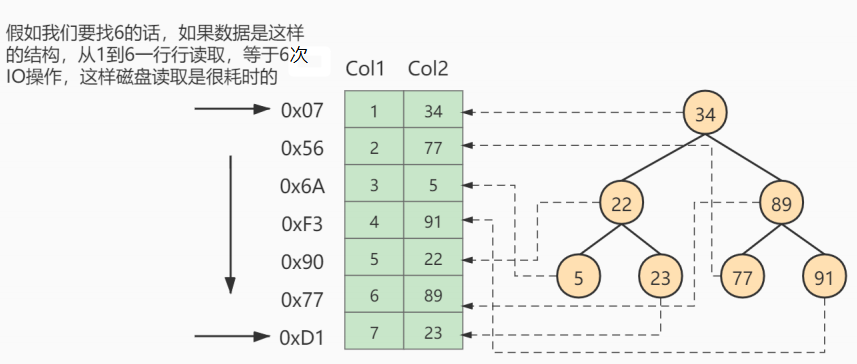
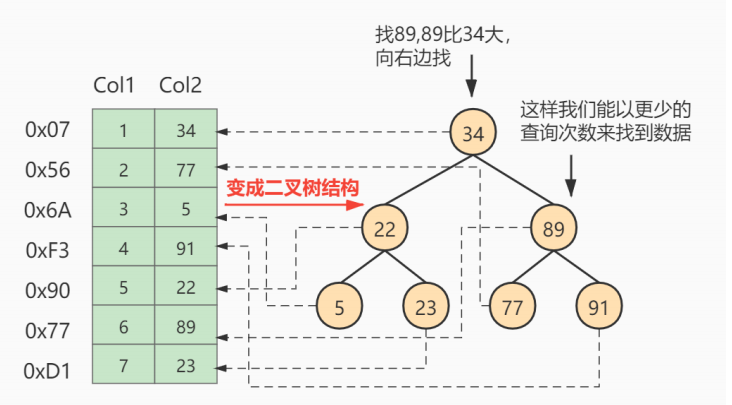
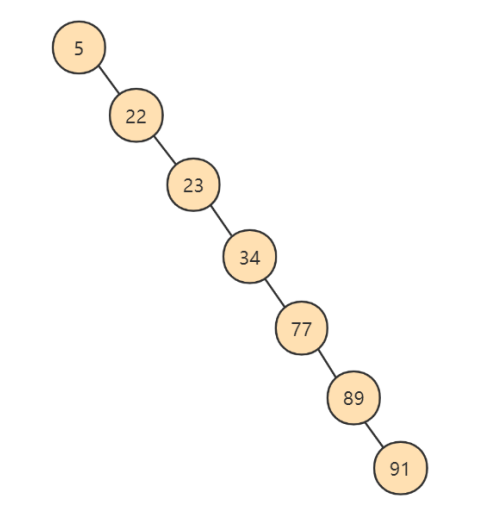



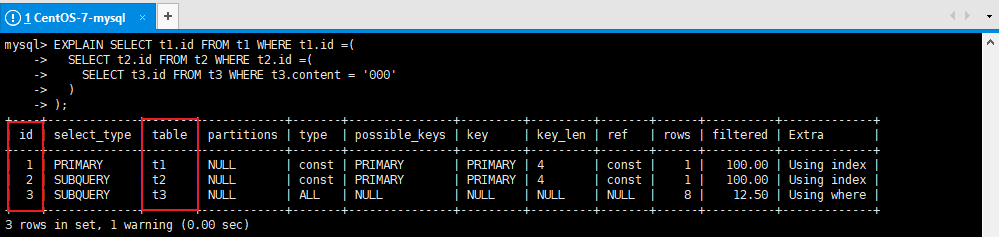







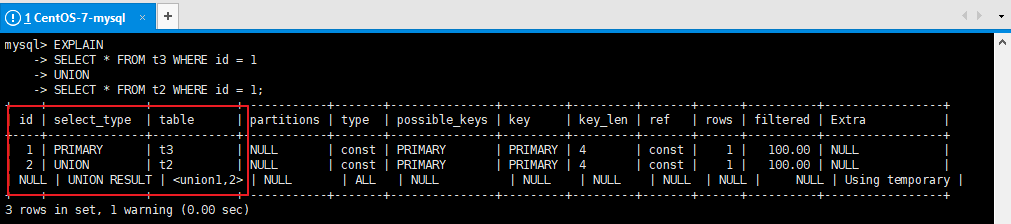
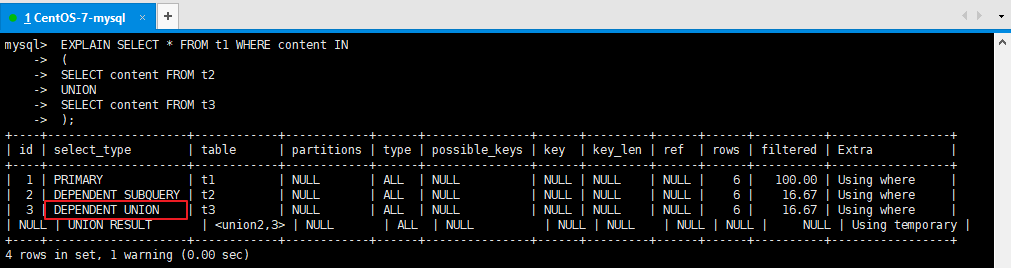



说明:
结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
比较重要的包含:system > const > eq_ref > ref > range > index > ALL
SQL 性能优化的目标:至少要达到 range 级别,要求是 ref 级别,最好是 const级别。(阿里巴巴
开发手册要求)



















课外阅读:在没有索引的情况下,为了优化多表连接,减少磁盘IO读取次数和数据遍历次数,MySQL为我们提供了很多不同的连接缓存的优化算法,可参考https://blog.csdn.net/qq_35423190/article/details/1205049603、准备数据
- Using join buffer (hash join)8.0新增:连接缓存(hash连接) 速度更快
- Using join buffer (Block Nested Loop)从5.7开始:连接缓存(块嵌套循环)
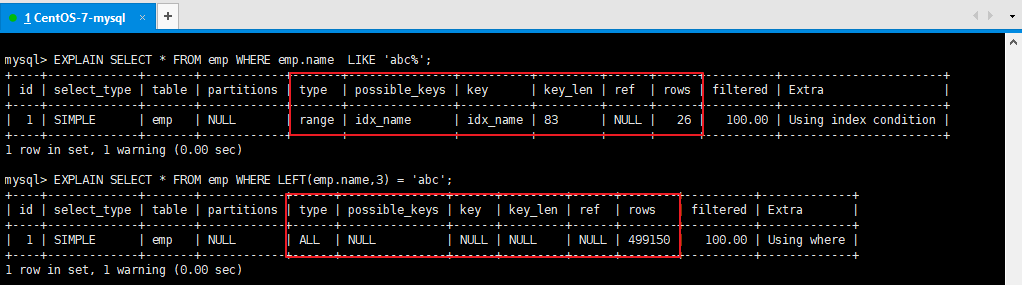

拓展:Alibaba《Java开发手册》4.3、不等于(!= 或者)索引失效
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
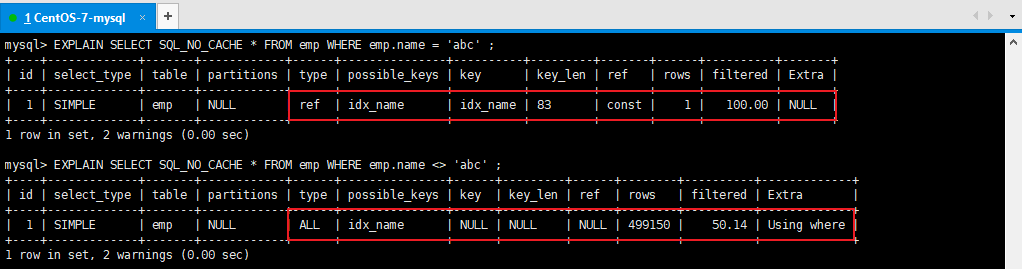
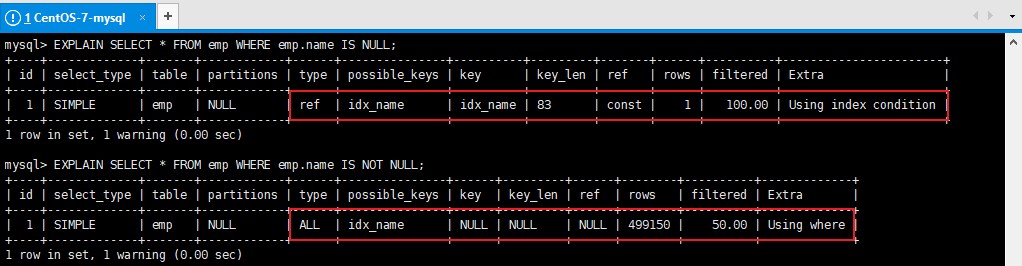
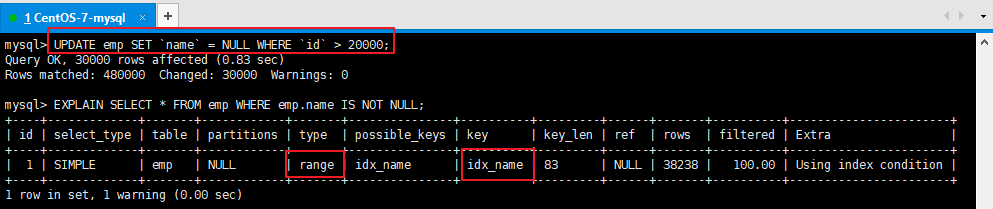
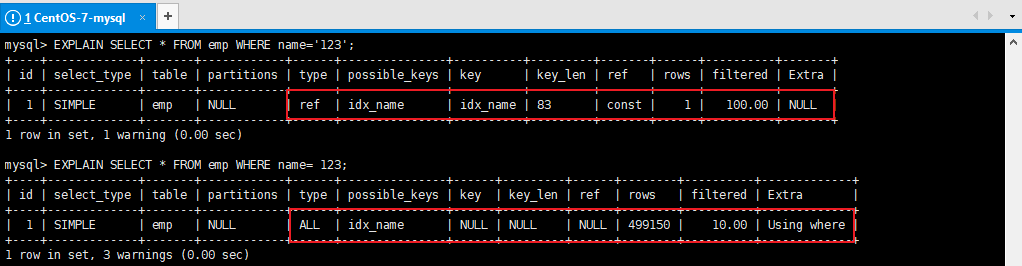

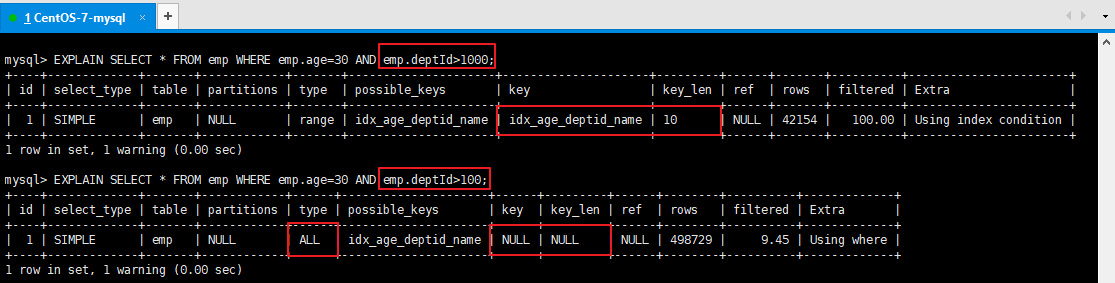
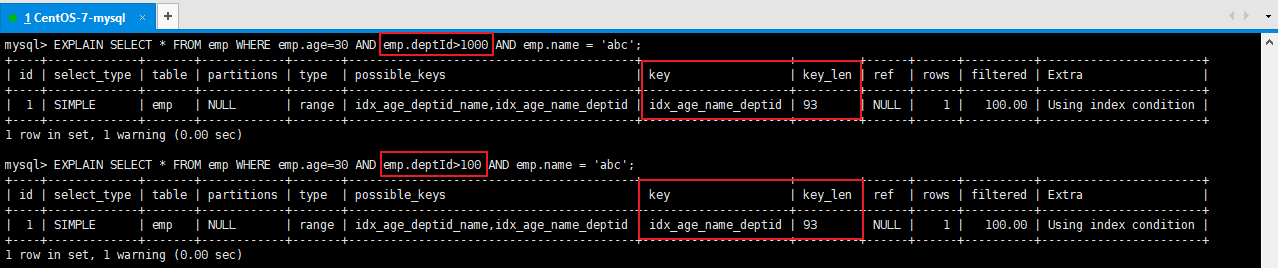




结论:5.3、内连接
针对两张表的连接条件涉及的列,索引要创建在被驱动表上,驱动表尽量是小表
- 如果驱动表上没有where过滤条件
- 当驱动表的连接条件没有索引时,驱动表是全表扫描
- 当针对驱动表的连接条件建立索引时,驱动表依然要进行全索引扫描
- 因此,此时建立在驱动表上的连接条件上的索引是没有太大意义的
- 如果驱动表上有where过滤条件,那么针对过滤条件创建的索引是有必要的
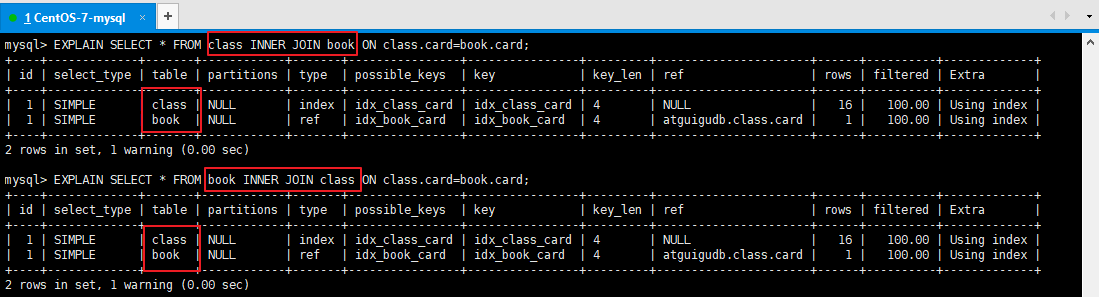



结论:发现即使交换表的位置,MySQL优化器也会自动选择驱动表,自动选择驱动表的原则是:索引创建在被驱动表上,驱动表是小表。5.4、扩展掌门人的练习
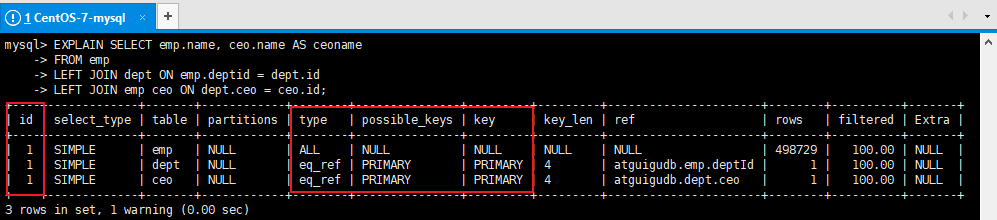
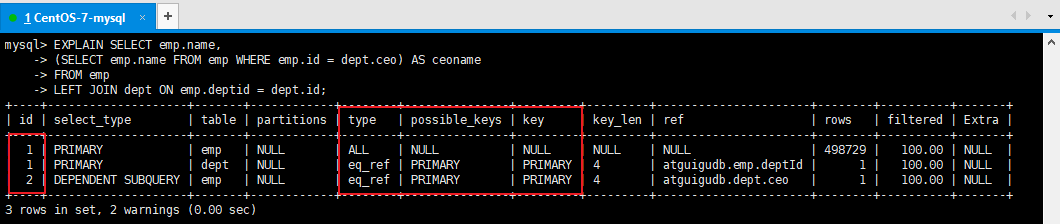
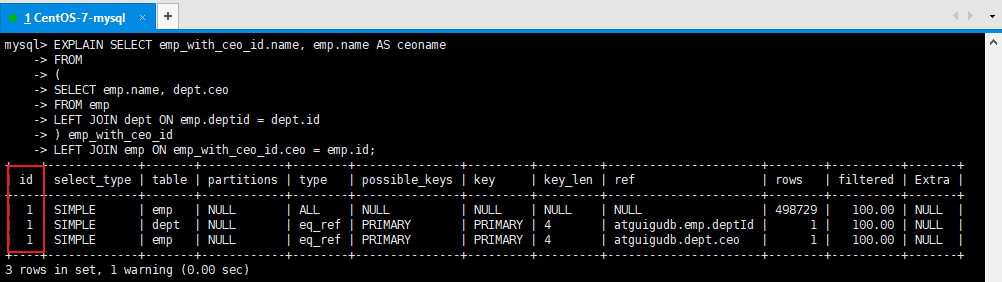
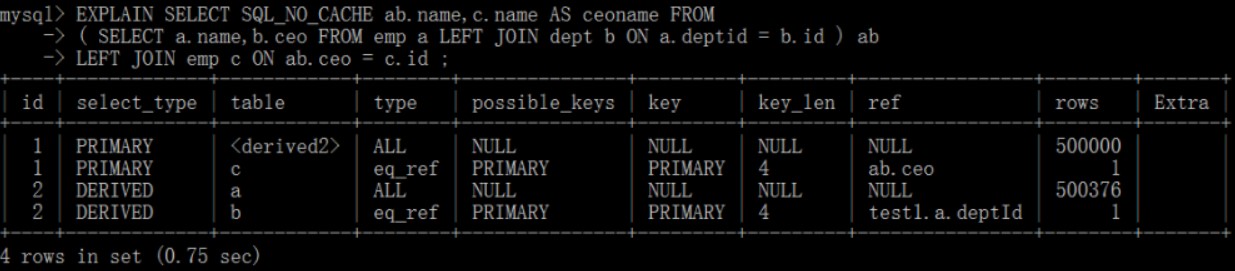
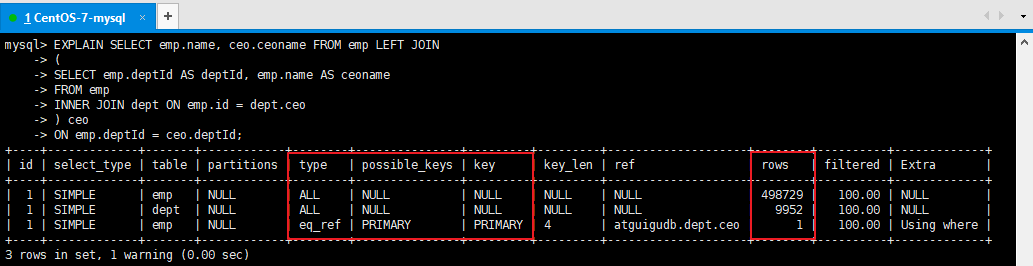
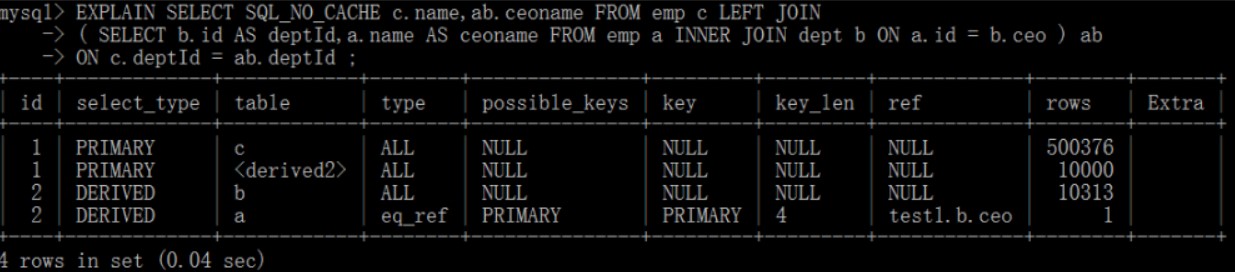



结论:尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx = xx WHERE xx IS NULL替代7、排序优化
以下三种情况不走索引:准备:
- 无过滤,不索引
- 顺序错,不索引
- 方向反,不索引
排序优化的目的是,去掉 Extra 中的 using filesort(手工排序)准备:
| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |