摘要:索引就是数据表中数据和相应的存储位置的列表,利用索引可以提高在表或视图中的查找数据的速度。本文分享自华为云社区《数据库开发指南(六)索引和视图的使用技巧、方法与综合应用》,作者: bluetata 。
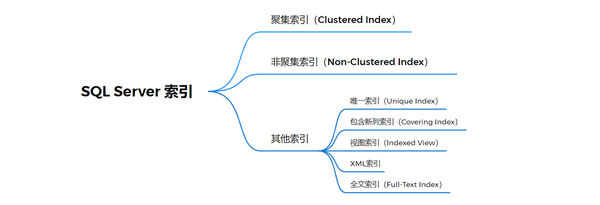 1.2.1 聚集索引
1.2.1 聚集索引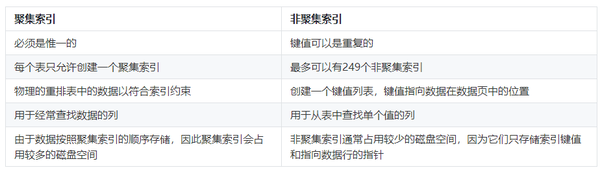 1.2.4 其他类型索引
1.2.4 其他类型索引请注意过多的索引也可能会带来维护开销和存储成本,因此需要在权衡索引数量和性能提升之间找到平衡点。定期监控和评估索引的使用情况也是重要的,以确保索引仍然对数据库性能产生积极影响。1.5 不适合创建索引的列
| 欢迎光临 qidao123.com技术社区-IT企服评测·应用市场 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |