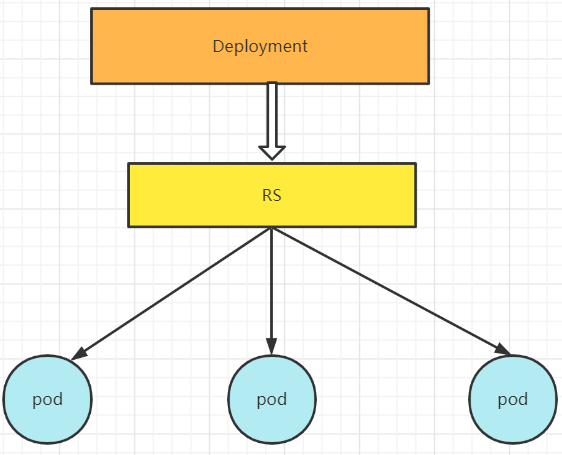
一般情况下,我们并不直接创建 Pod,而是通过 Deployment 来创建 Pod,由 Deployment 来负责创建、更新、维护其所管理的所有 Pods。ReplicationSet(RS)和ReplicationController(RC)区别
这里就需要说一下ReplicationSet(RS)和ReplicationController(RC),RS是在RC基础上发展来的,在新版的Kubernetes中,已经将RC替换为RS 了,它们两者没有本质的区别,都是用于Pod副本数量的维护与更新的,使得副本数量始终维持在用户定义范围内,即如果存在容器异常退出,此时会自动创建新的Pod进行替代;而且异常多出来的容器也会自动回收。
总结不同点在于:RS在RC的基础上支持集合化的selector
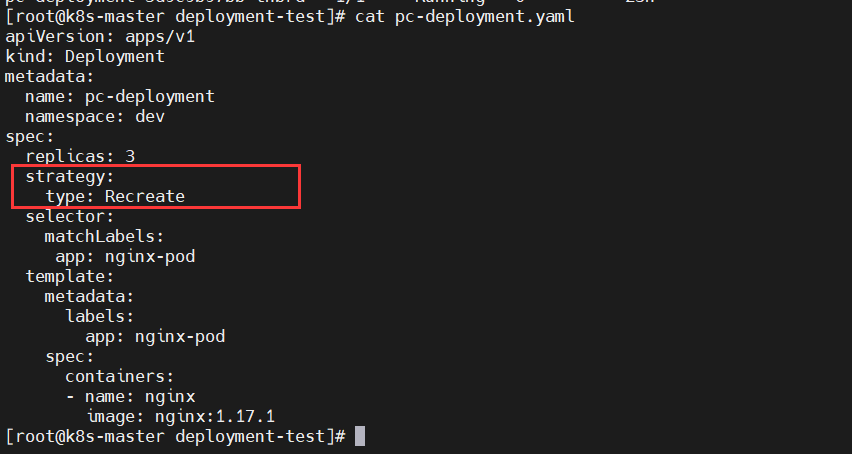
一般情况下RS也是可以单独使用的,但是一般推荐和Deployment一起使用,这样会使得的Deployment提供的一些回滚更新操作同样用于RS上,因为RS不支持回滚更新操作,Deployment支持;二、Deployment工作原理
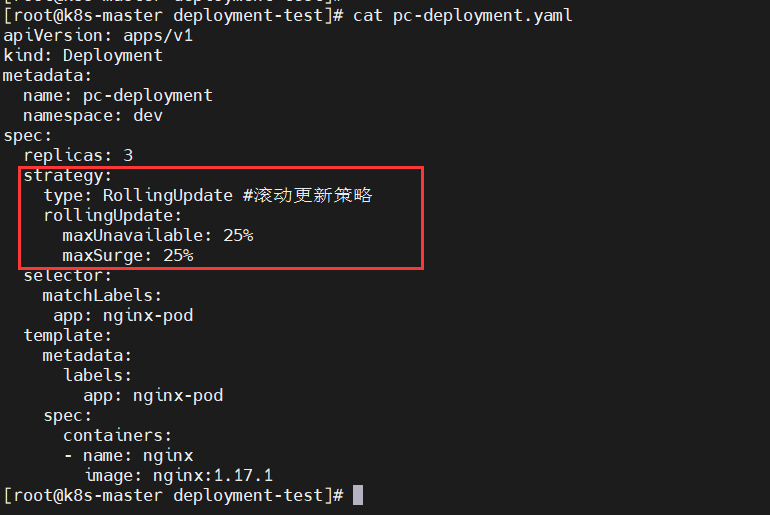
Deployment控制器支持两种更新策略:滚动更新(rolling update)和重新创建(recreate),默认为滚动更新。1)滚动升级
滚动升级是默认的更新策略,它在删除一部分旧版本Pod资源的同时,补充创建一部分新版本的Pod对象进行应用升级,其优势是升级期间,容器中应用提供的服务不会中断,但要求应用程序能够应对新旧版本同时工作的情形,例如新旧版本兼容同一个数据库方案等。不过,更新操作期间,不同客户端得到的响应内容可能会来自不同版本的应用。
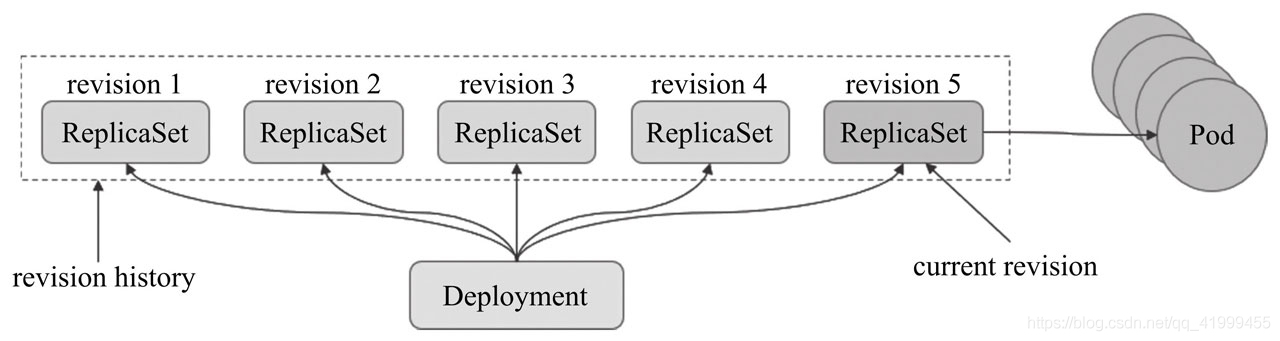
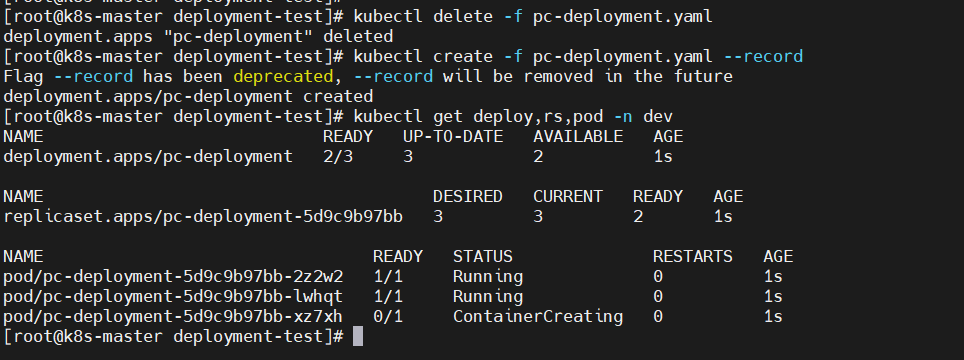
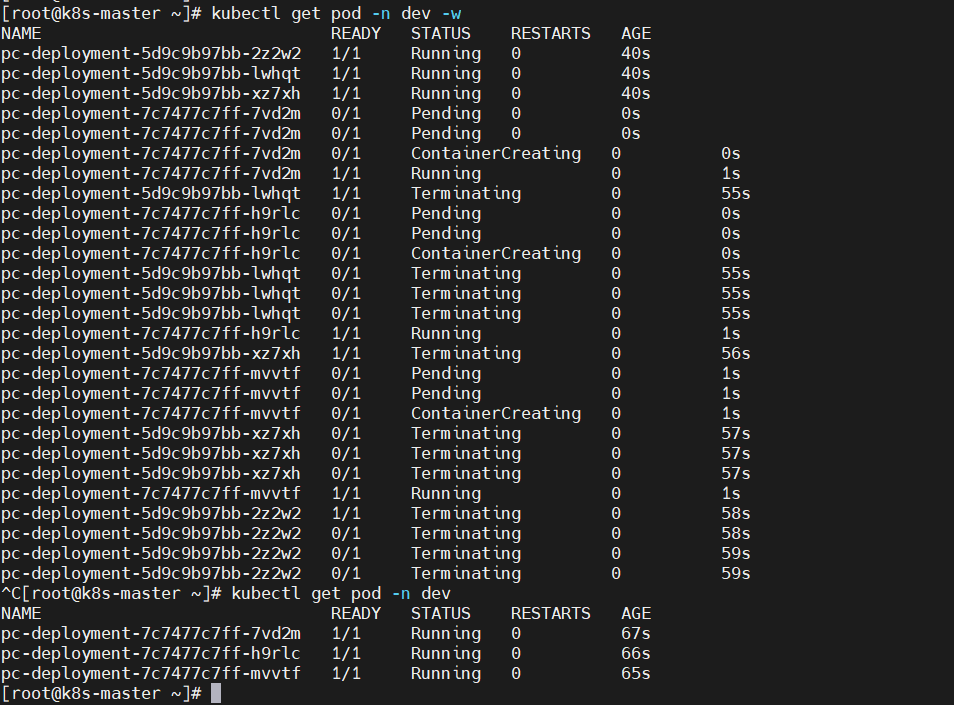
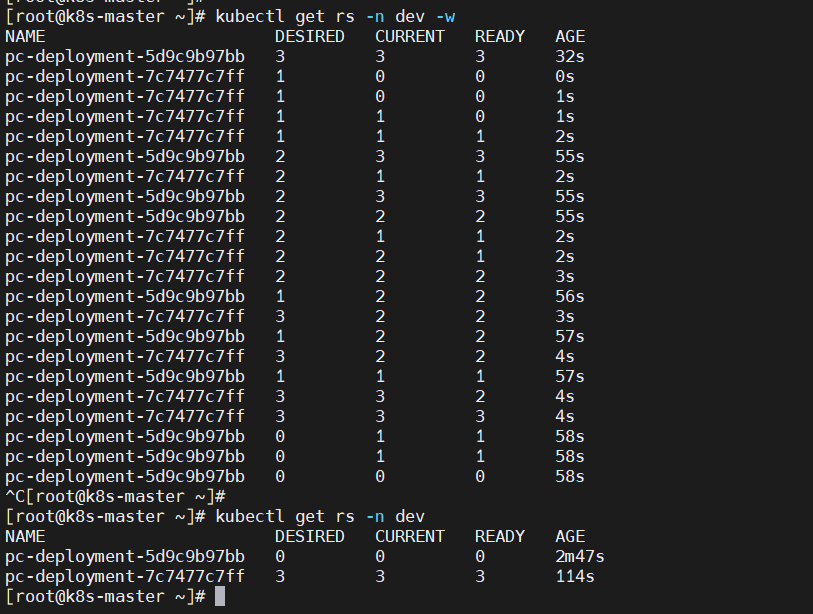
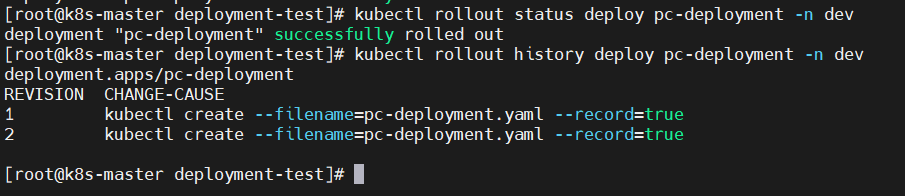
Deployment控制器的滚动更新操作并非在同一个ReplicaSet控制器对象下删除并创建Pod资源,而是将它们分置于两个不同的控制器之下:旧控制器的Pod对象数量不断减少的同时,新控制器的Pod对象数量不断增加,直到旧控制器不再拥有Pod对象,而新控制器的副本数量变得完全符合期望值为止,如图所示:


maxSurge和maxUnavailable属性的值不可同时为0,否则Pod对象的副本数量在符合用户期望的数量后无法做出合理变动以进行滚动更新操作。2)版本回滚
Deployment控制器也支持用户保留其滚动更新历史中的旧ReplicaSet对象版本,这赋予了控制器进行应用回滚的能力:用户可按需回滚到指定的历史版本。控制器可保存的历史版本数量由“spec.revisionHistoryLimit”属性进行定义。当然,也只有保存于revision历史中的ReplicaSet版本可用于回滚,因此,用户要习惯性地在更新操作时指定保留旧版本。


kubectl scale deploy deploy名称 --replicas=pod数量 -n 命名空间过命令行变更pod数量为5个

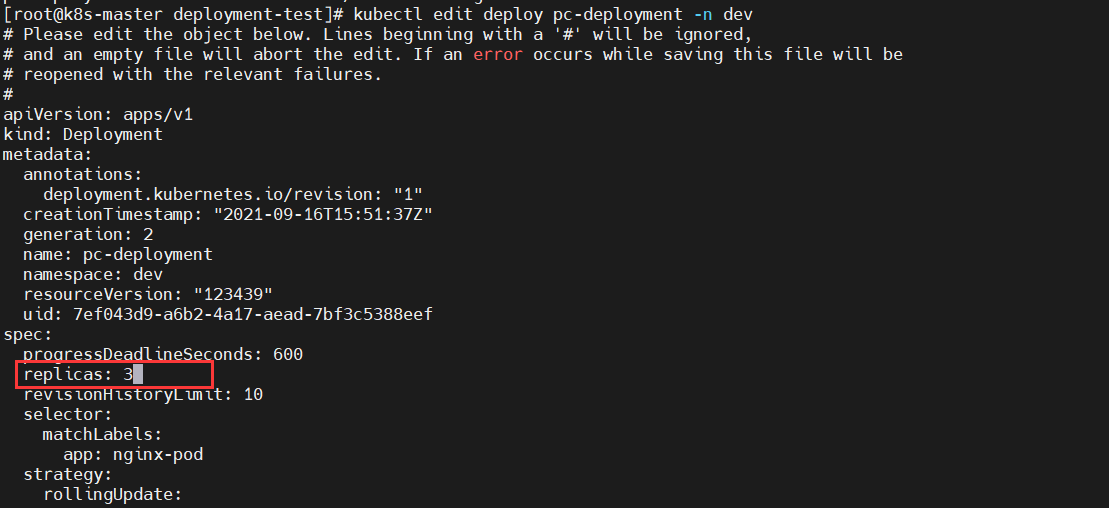
kubectl edit deploy deploy名字 -n 命名空间通过编辑deploy文件编辑pod数量为3个







deployment支持更新过程中的控制,如"暂停(pause)"或"继续(resume)"更新操作。
比如有一批新的pod资源创建完成后立即暂停更新过程,此时,仅存在一部分新版本的应用,主体部分还是旧的版本。然后,再筛选一小部分的用户请求路由到新的pod应用,继续观察能否稳定地按期望的方式运行。确定没问题之后再继续完成余下的pod资源滚动更新,否则立即回滚更新操作。这就是所谓的金丝雀发布,其实也叫做灰度发布。更新deployment版本,并配置暂停deployment

PersistentVolume (PV:持久化存储卷)是集群中由管理员提供或使用存储类动态提供的一块存储。它是集群中的资源,就像节点是集群资源一样。
PV是与Volumes类似的卷插件,但其生命周期与使用PV的任何单个Pod无关。由此API对象捕获存储的实现细节,不管是NFS、iSCSI还是特定于云提供商的存储系统。2)PVC概述
PersistentVolumeClaim(PVC:持久化存储卷声明),PVC 是用户存储的一种声明,PVC 和 Pod 比较类似,Pod 消耗的是节点,PVC 消耗的是 PV 资源,Pod 可以请求 CPU 和内存,而 PVC 可以请求特定的存储空间和访问模式。对于真正使用存储的用户不需要关心底层的存储实现细节,只需要直接使用 PVC 即可。3)通过NFS实现持久化存储
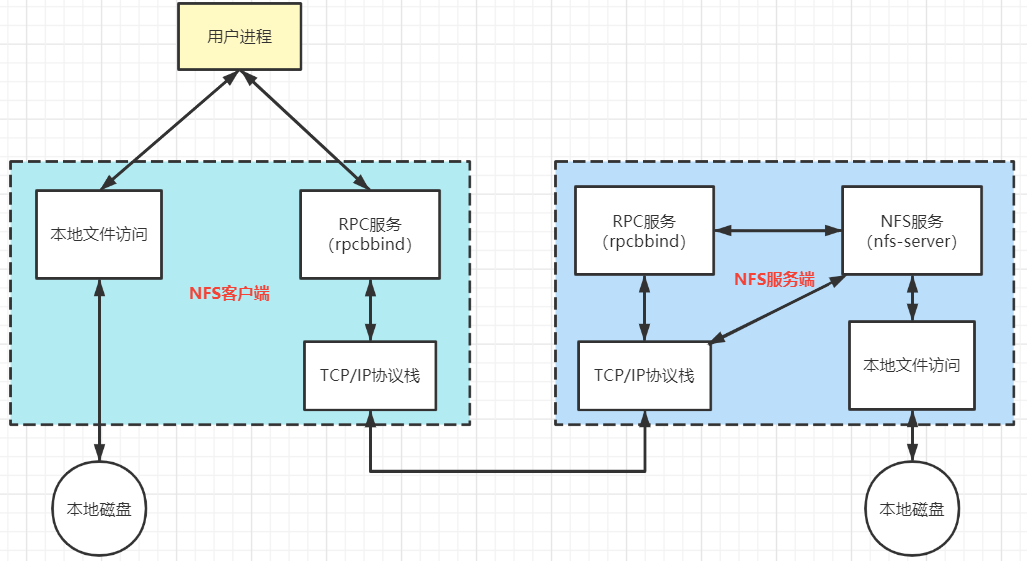
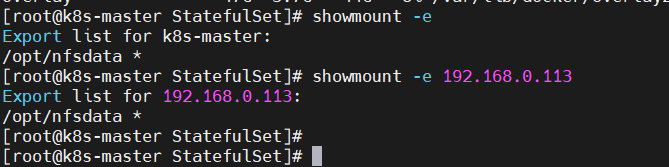
常用选项5、启动rpc和nfs(客户端只需要启动rpc服务)(注意顺序)
-a 全部挂载或者全部卸载
-r 重新挂载
-u 卸载某一个目录
-v 显示共享目录 以下操作在服务端上
-e 显示NFS服务器的共享列表
-a 显示本机挂载的文件资源的情况NFS资源的情况
-v 显示版本号
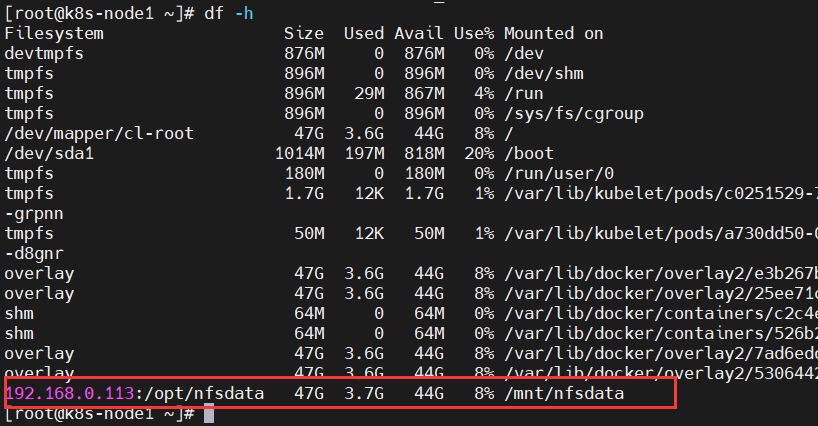

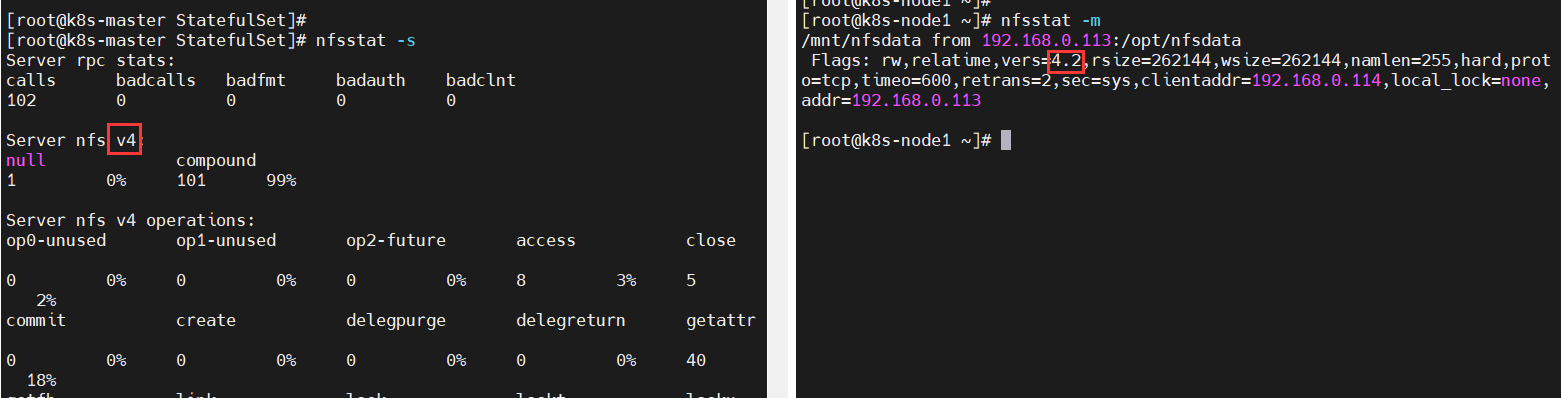
spec.storageClassName 字段对应 StorageClass 配置中的 metedata.name 字段
capacity: #容量执行
volumeMode: 存储卷模式(默认值为filesystem,除了支持文件系统外(file system)也支持块设备(raw block devices))
accessModes: 访问模式
ReadWriteMany :(RWO/该volume只能被单个节点以读写的方式映射),ReadOnlyMany (ROX/该volume可以被多个节点以只读方式映射), ReadWriteMany (RWX/该volume可以被多个节点以读写的方式映射)
persistentVolumeReclaimPolicy: 回收策略 ,Retain(保留)、 Recycle(回收)或者Delete(删除)
storageClassName: 存储类(通过设置storageClassName字段进行设置。如果设置了存储类,则此PV只能被绑定到也指定了此存储类的PVC)
mountOptions: 挂接选项
path: 我的本地挂载路径为
server: NFS 文件系统所在服务器的真实 IP
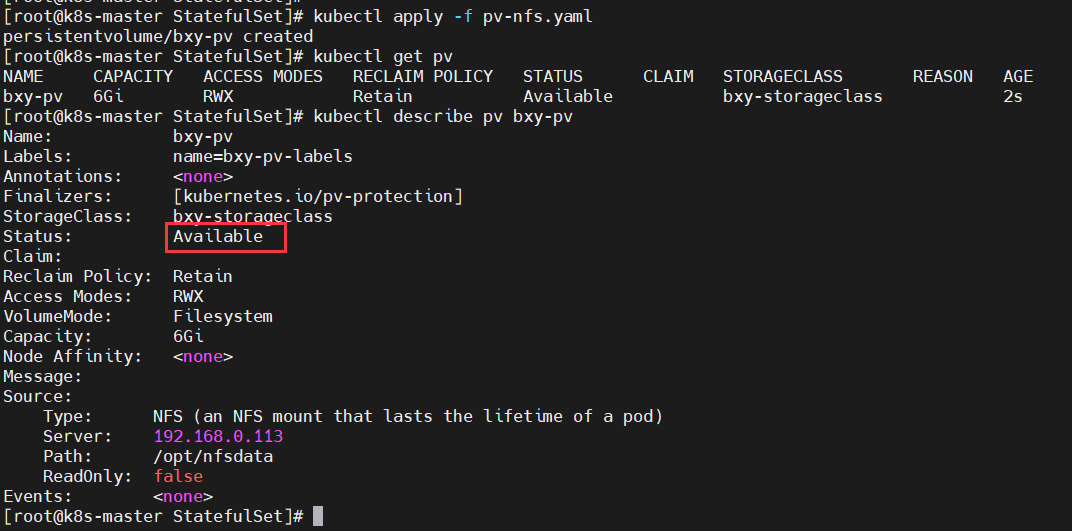
【注意】storage: 5Gi:我写的是 5G ,但实际绑定成功后会自动改变为 PV 中设置的容量大小 6G。
pvc 通过 matchLabels和pv中的label匹配,来关联要使用的存储空间。表明此PVC希望使用Label:name: "bxy-pv-labels"的PV。执行

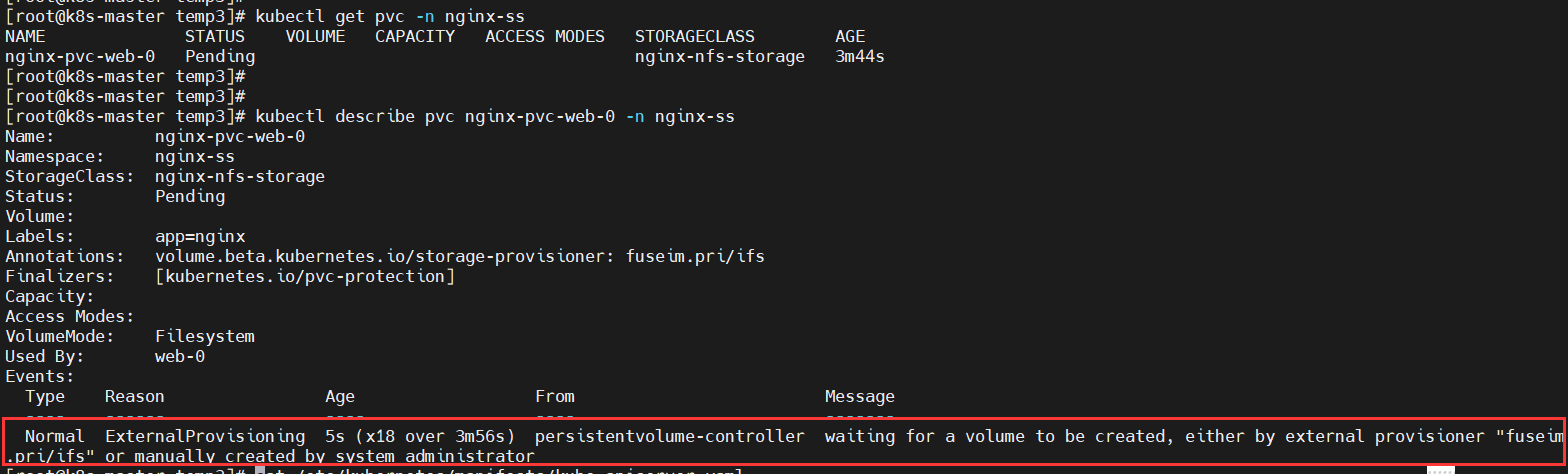
SC是StorageClass的缩写,表示存储类;这种资源主要用来对pv资源的自动供给提供接口;所谓自动供给是指用户无需手动创建pv,而是在创建pvc时对应pv会由persistentVolume-controller自动创建并完成pv和pvc的绑定;使用sc资源的前提是对应后端存储必须支持restfull类型接口的管理接口,并且pvc必须指定对应存储类名称来引用SC;简单讲SC资源就是用来为后端存储提供自动创建pv并关联对应pvc的接口;如下图:
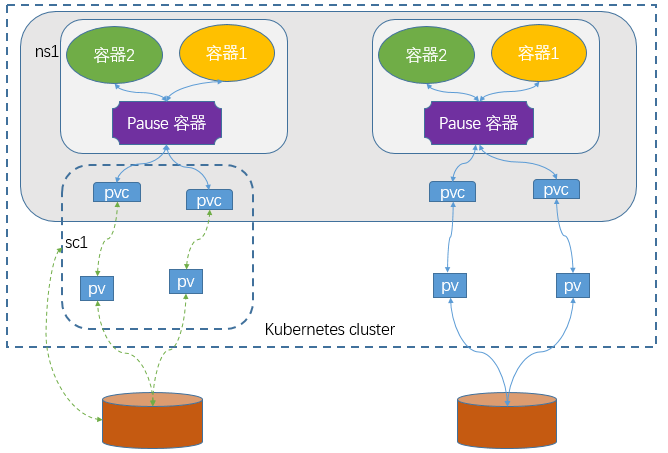
【提示】使用sc动态创建pv,对应pvc必须也是属于对应的sc;上图主要描述了用户在创建pvc时,引用对应的sc以后,对应sc会调用底层存储系统的管理接口,创建对应的pv并关联至对应pvc。创建sc资源
【提示】在创建pvc时用storageClassName字段来指定对应的SC名称即可。上述是官方文档中的一个示例,在创建sc资源时,对应群组是storage.k8s.io/v1,类型为StorageClass;provisioner字段用于描述对应供给接口名称;parameters用来定义向对应存储管理接口要传递的参数。7)基于动态sc(StorageClass:存储类)创建一个pv
nfs-client-provisioner 是k8s简易的NFS外部提供者(provisioner),本身不提供NFS,做为NFS的客户端为StorageClass提供存储。

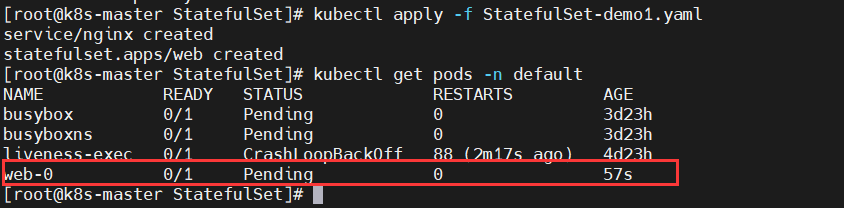
StatefulSet是用来管理有状态应用的工作负载API对象,实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,称为”有状态应用“。
StatefulSet本质上是Deployment的一种变体,在v1.9版本中已成为GA版本,它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称,启停顺序,在StatefulSet中,Pod名字称为网络标识(hostname),还必须要用到共享存储。
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。除此之外,StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod副本创建了一个DNS域名,这个域名的格式为:
$(podname).(headless server name)2)常规service和无头服务区别
FQDN:$(podname).(headless server name).namespace.svc.cluster.local
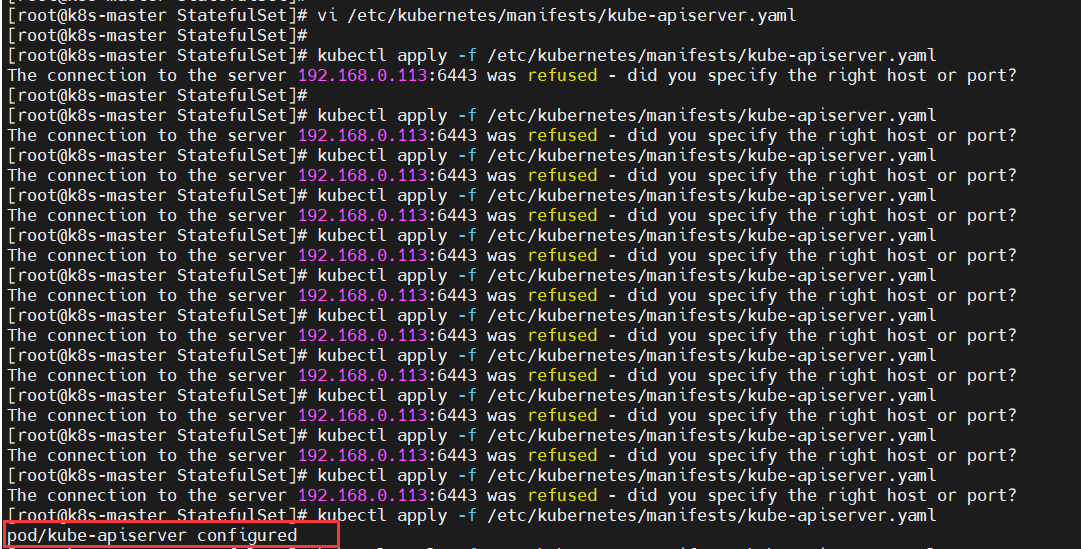
修改 /etc/kubernetes/manifests/kube-apiserver.yaml 文件,并在其启动参数中增加一行 – –feature-gates=RemoveSelfLink=false,如下第 43行所示:


DaemonSet 确保全部(或者一些)Node 上运行一个 Pod 的副本,通常用于实现系统级后台任务。比如ELK服务创建DaemonSet
DaemonSet的描述文件和Deployment非常相似,只需要修改Kind,并去掉副本数量的配置即可。

Job控制器用于调配pod对象运行一次性任务,容器中的进程在正常运行结束后不会对其进行重启,而是将pod对象置于completed状态。若容器中的进程因错误而终止,则需要依据配置确定重启与否,未运行完成的pod对象因其所在的节点故障而意外终止后会被重新调度。简单示例
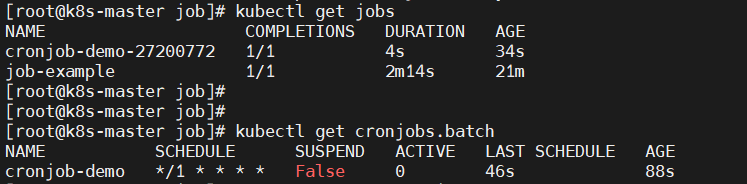
CronJob其实就是在Job的基础上加上了时间调度,我们可以:在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。这个实际上和我们Linux中的crontab就非常类似了。
一个CronJob对象其实就对应中crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。crontab的格式如下:
分 时 日 月 星期 要运行的命令 第1列分钟0~59 第2列小时0~23) 第3列日1~31 第4列月1~12 第5列星期0~7(0和7表示星期天) 第6列要运行的命令现在,我们用CronJob来管理我们上面的Job任务
ReplicationController用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的Pod来替代;而如果异常多出来的容器也会自动回收。2)ReplicaSet主要功能(RS)
在新版本的Kubernetes中建议使用ReplicaSet来取ReplicationController。ReplicaSet跟ReplicationController没有本质的不同,只是名字不一样,并且ReplicaSet支持集合式的selector。
虽然ReplicaSet可以独立使用,但一般还是建议使用 Deployment 来自动管理ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如ReplicaSet不支持rolling-update但Deployment支持)。
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |