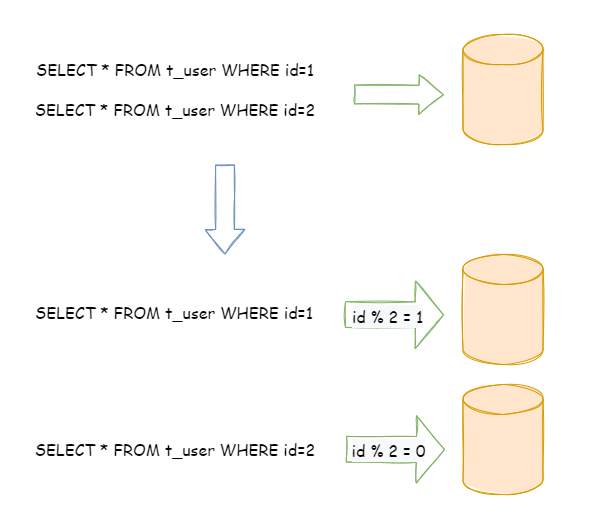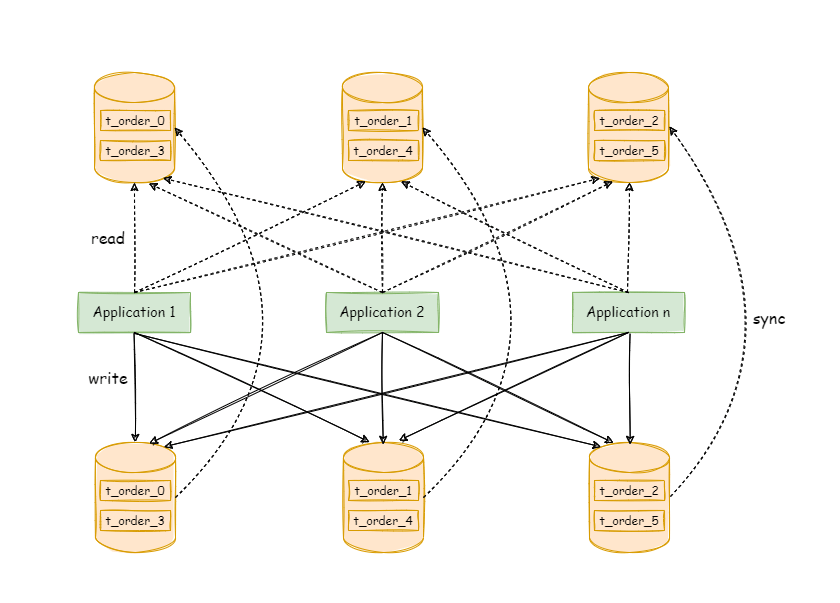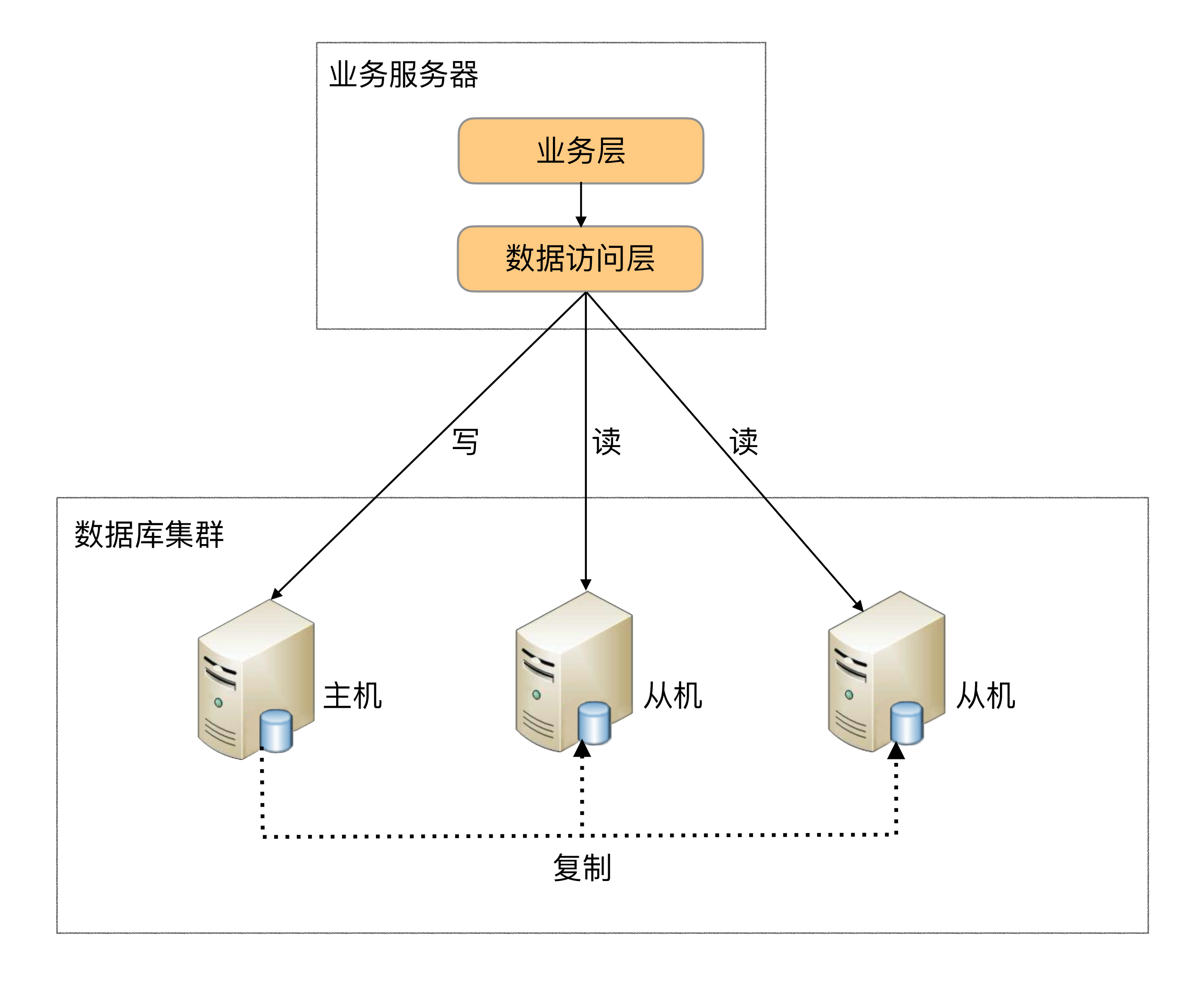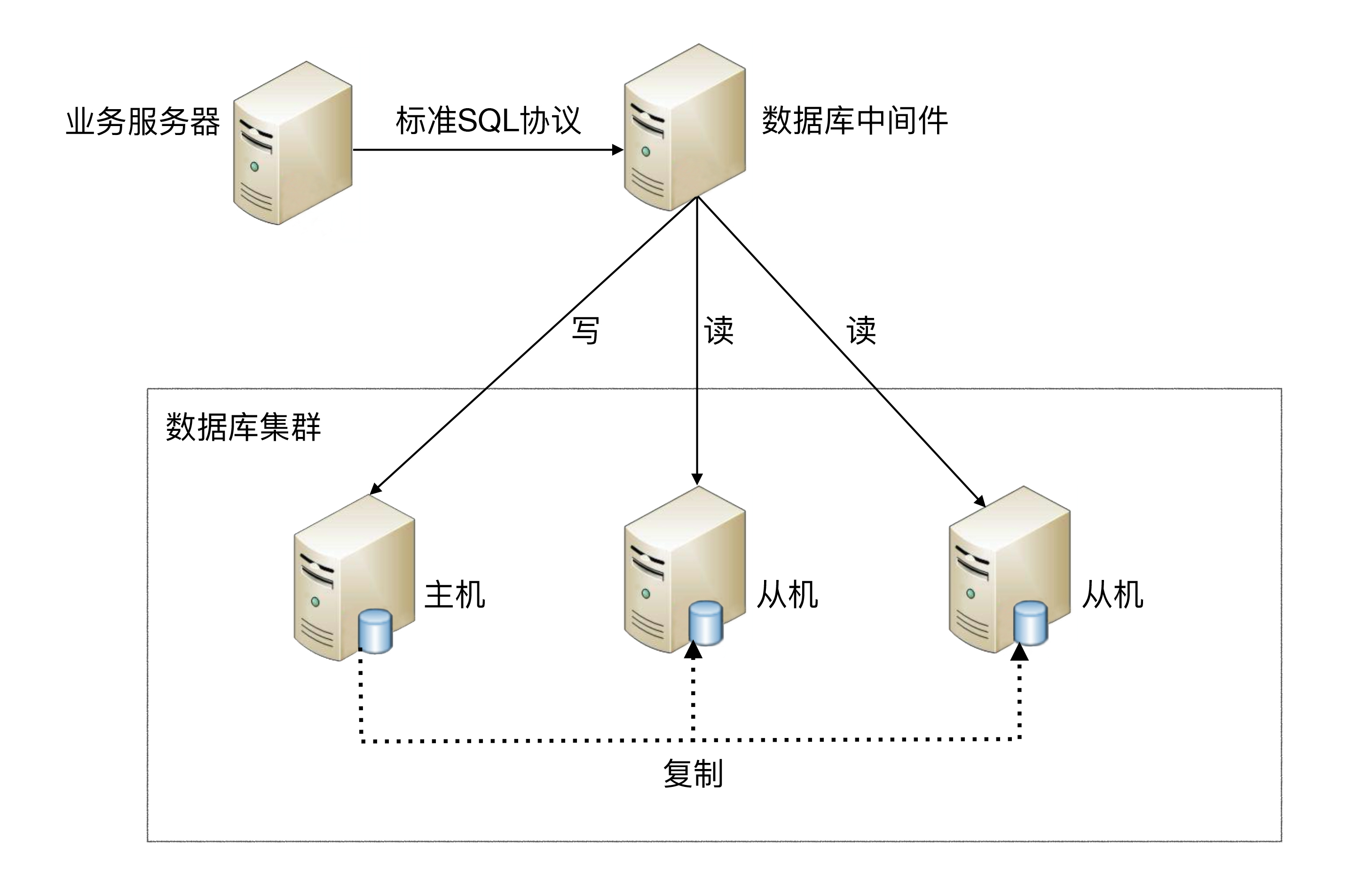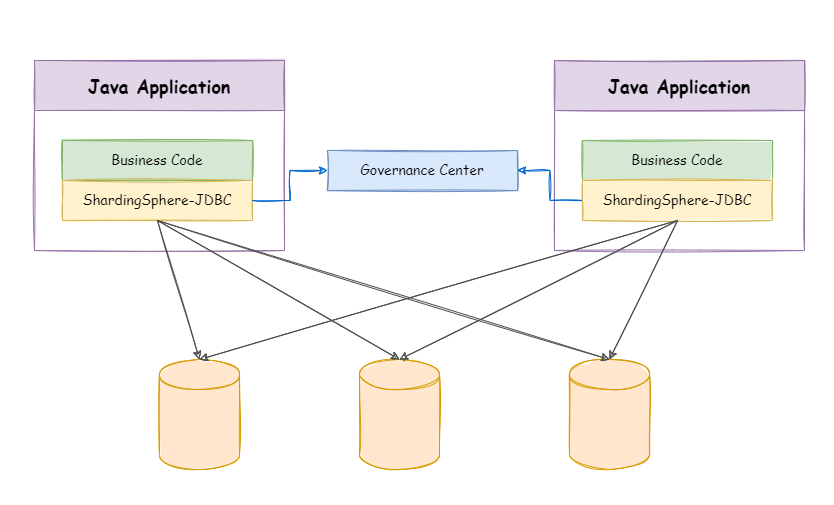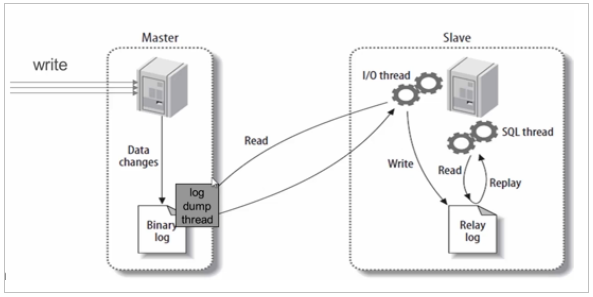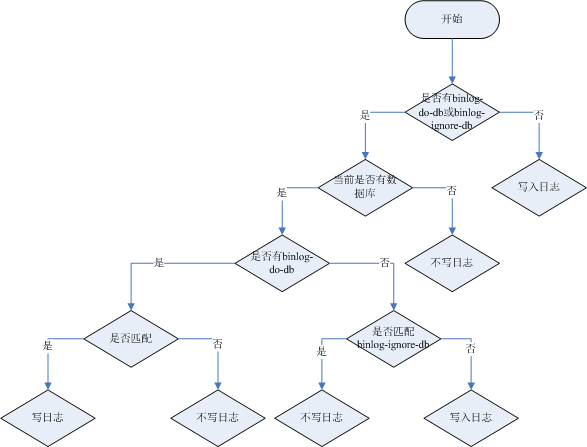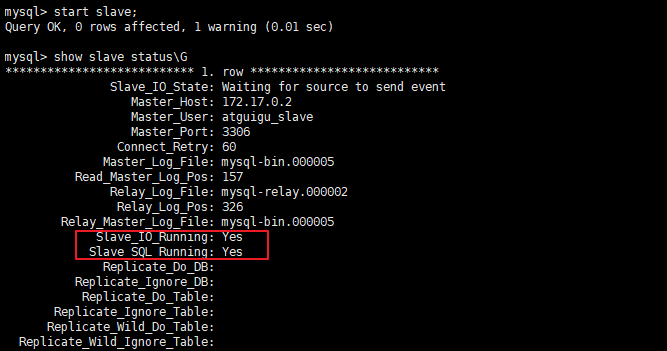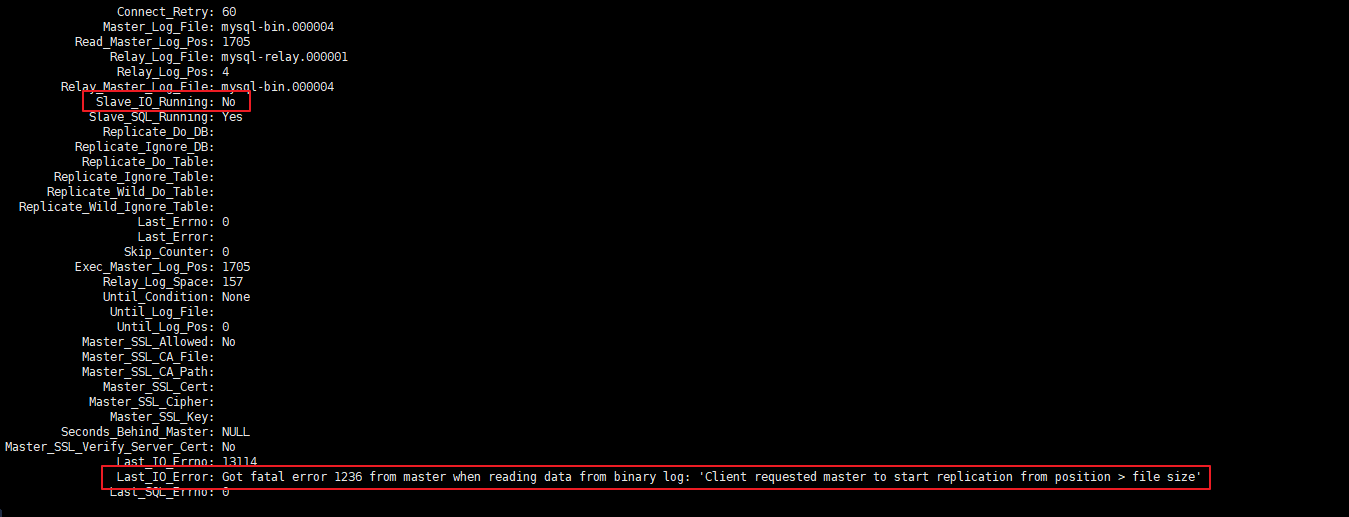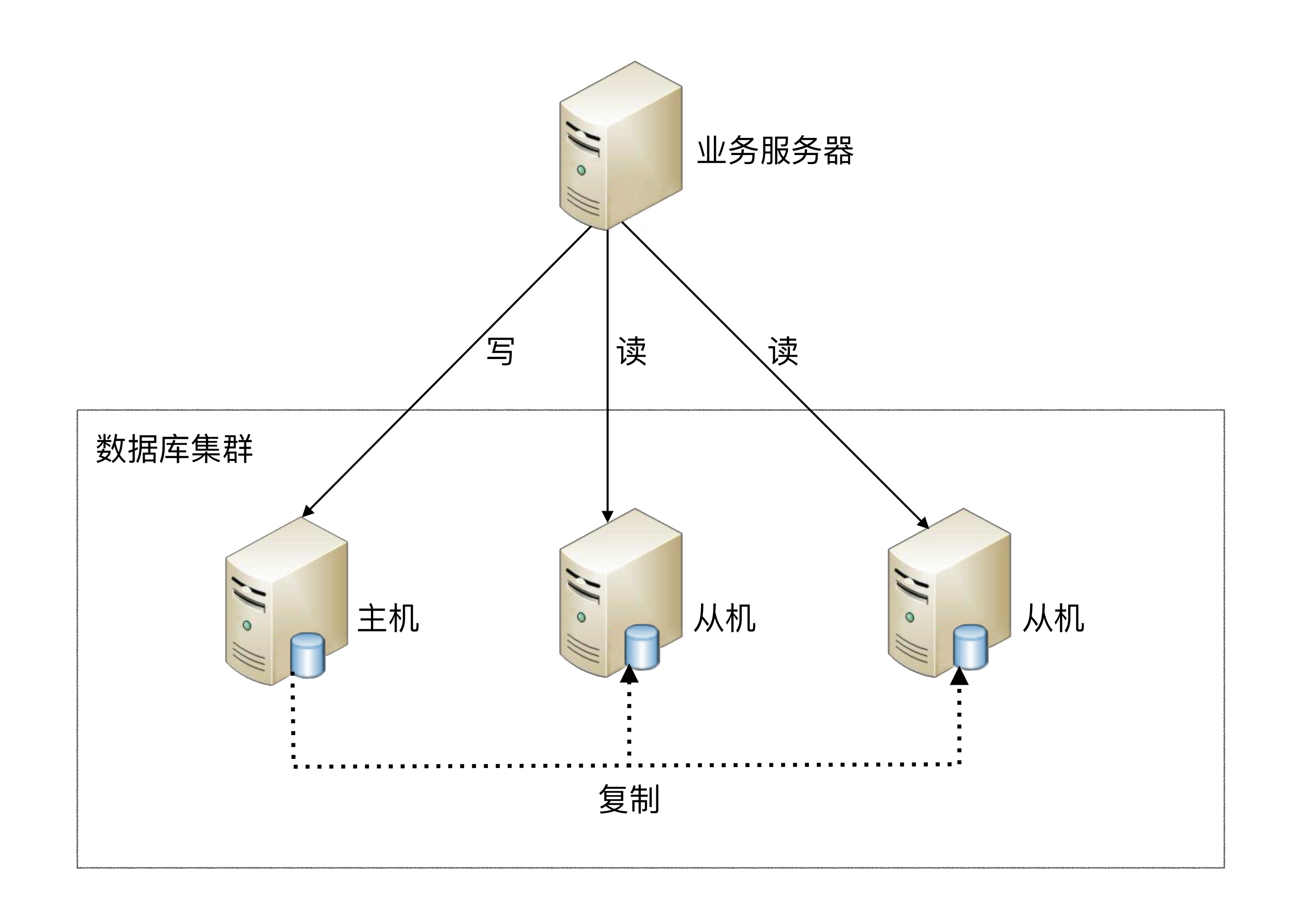
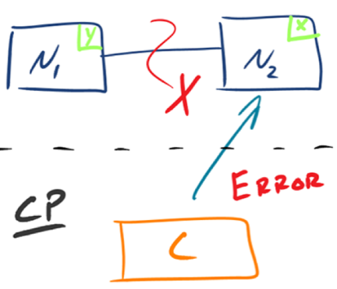
- CP:如下图所示,为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
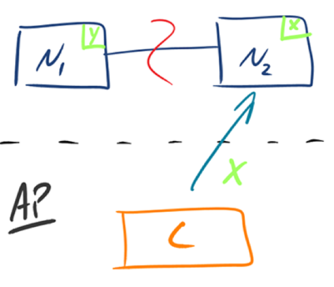
- AP:如下图所示,为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。