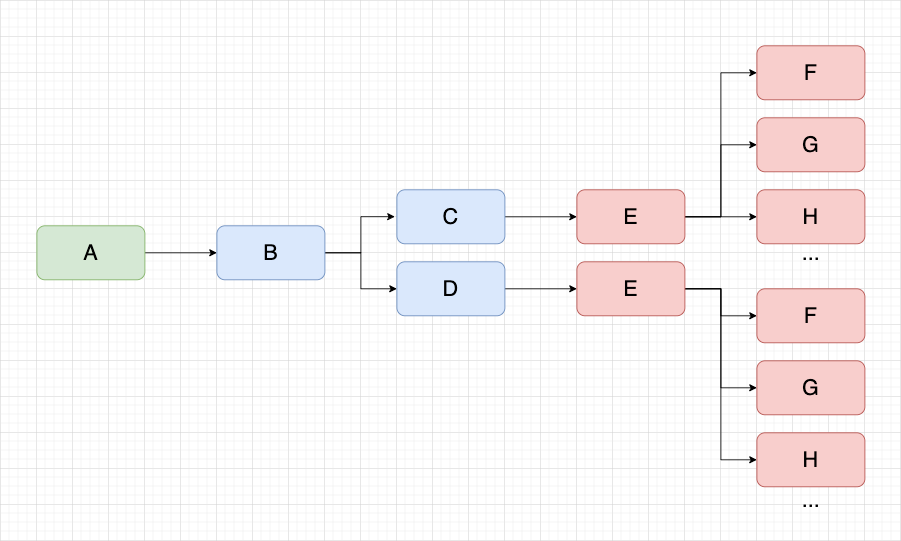
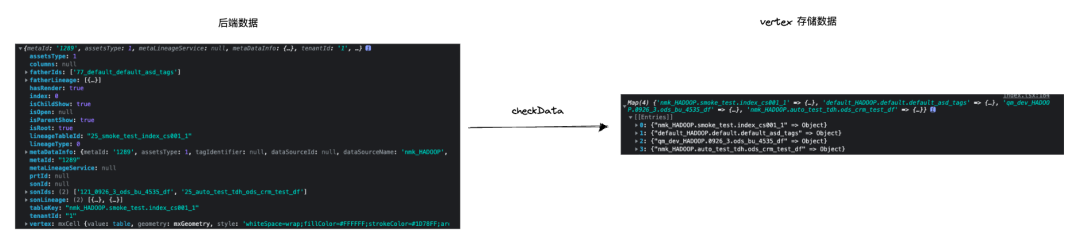
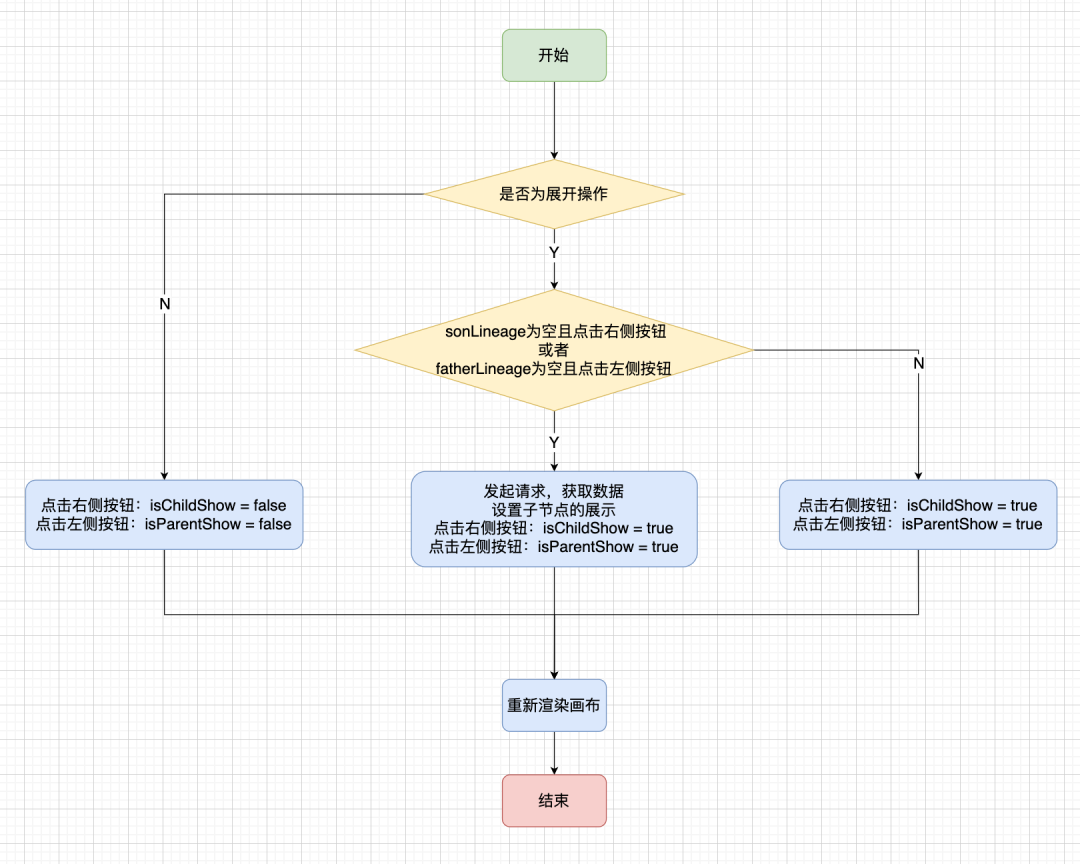
在资产的 A 任务血缘链路中,C/D 任务下游均为 E 任务,当我们同时打开了 C/D 任务的下游节点,就会发现大量的重复节点出现,但本质上他们是一模一样的任务节点,如下图。
当一条血缘上的任务越多,出现上述问题的概率增大,会导致画布内容显示的都是重复节点,查看血缘关系效率低下。
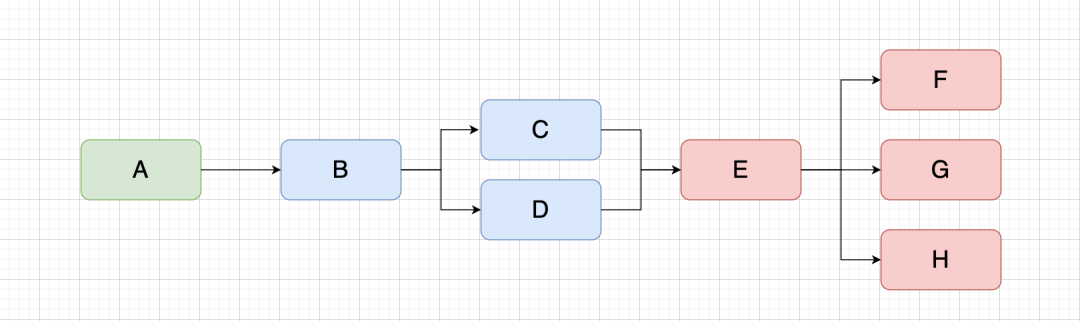
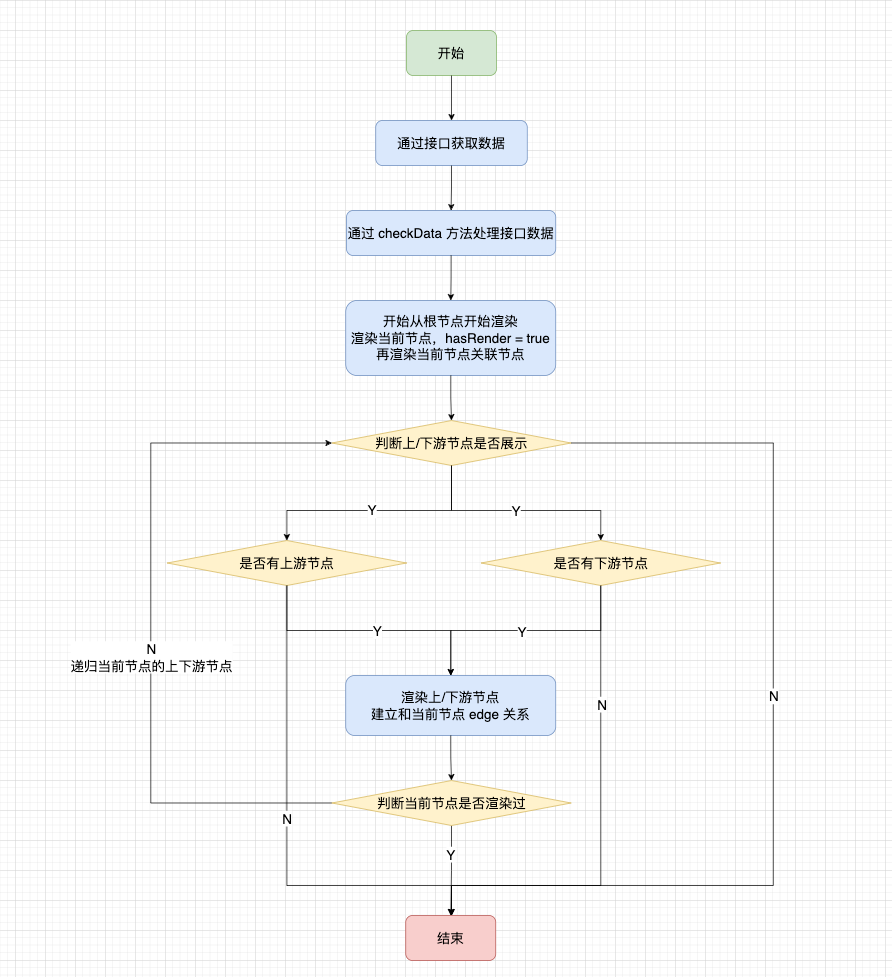
期望能够做到同一个节点只在画布中展示一次,在这个节点存在于画布中时,后续再有相同节点就做共用,如下图。
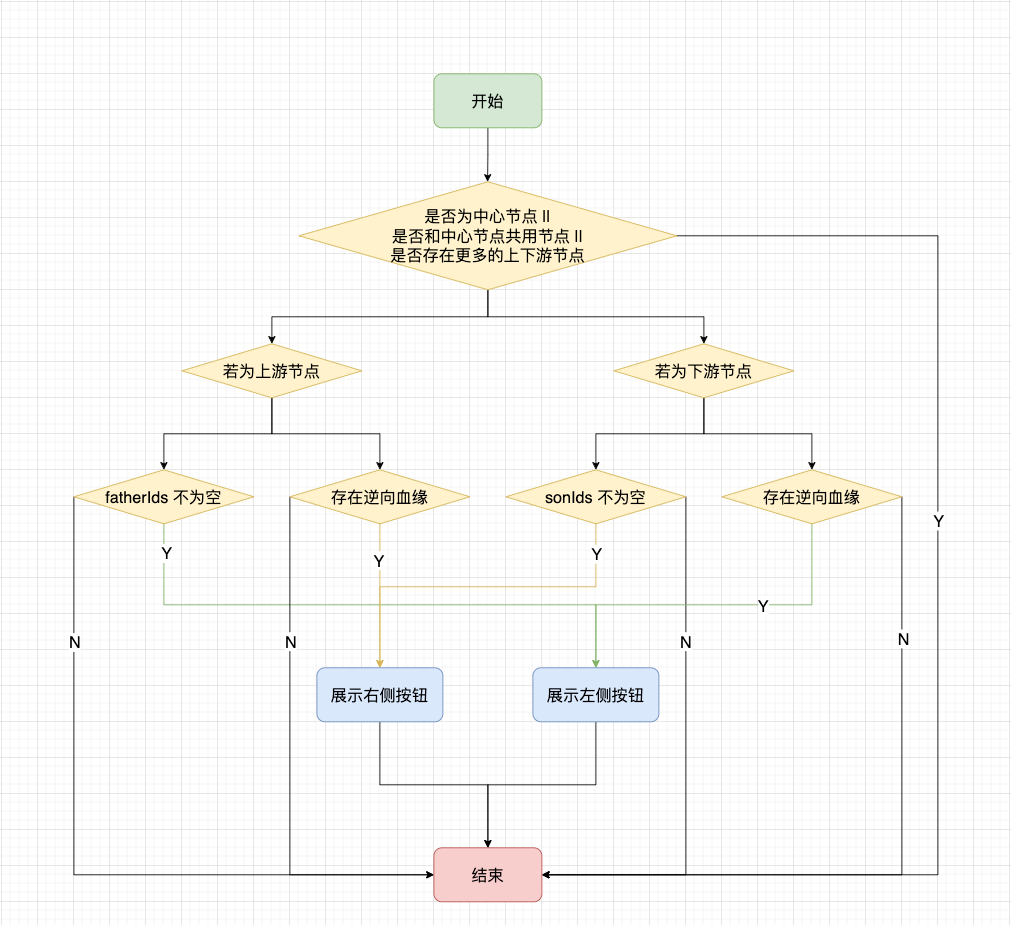
逆向血缘的展示
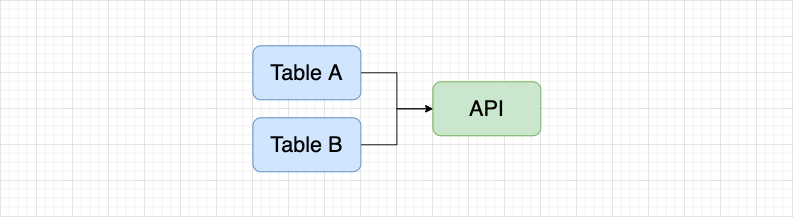
先简单介绍一下,何为逆向血缘?用 API 任务举例子来说:
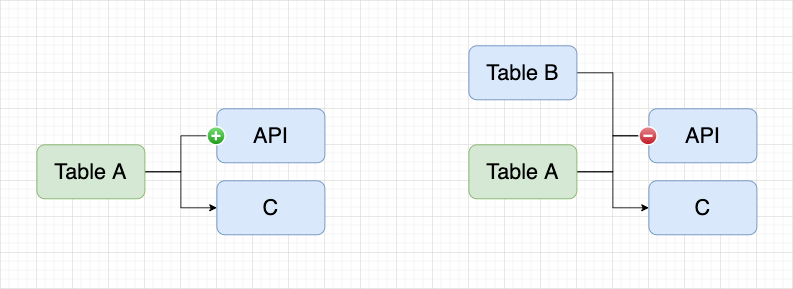
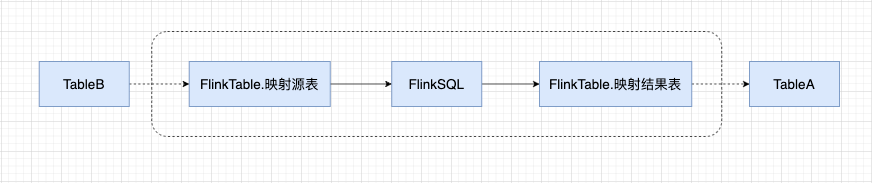
在 API 平台中,通过 DQL 模式使用两张表创建一个 API,在资产平台以 API 任务进入血缘就会展示如下图的血缘关系。如果 Table A 已经同步到了资产平台,以 Table A 表进入血缘,希望展示如下图的血缘关系。
由于 API 是由 Table A/B 共同生成的,因此需要在 API 左侧展示加号,能够将 Table B 加载出来,这就是逆向血缘,也是全链路实现的重要一环。
相似数据源