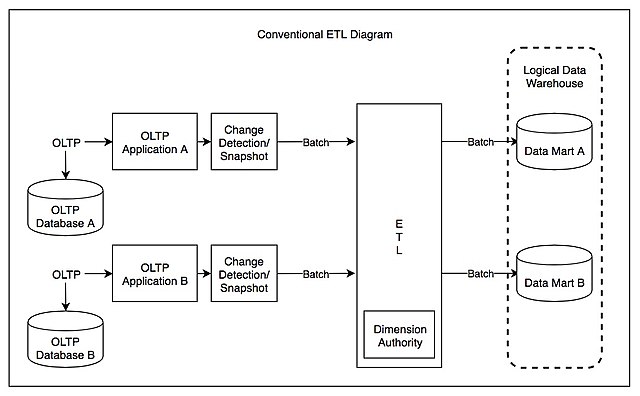
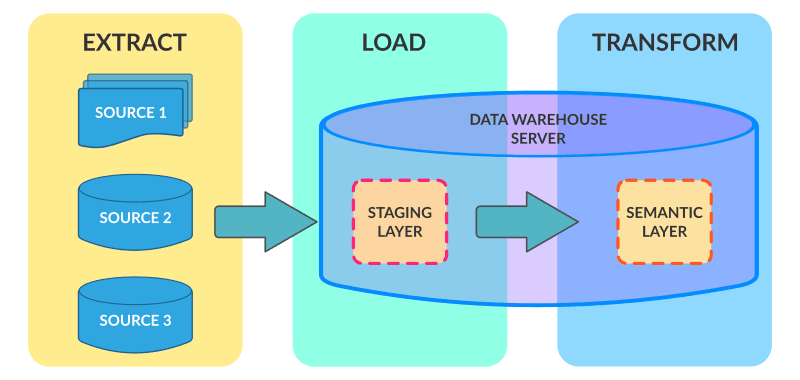
随着数据量越来越大,数据仓库的硬件成本与ETL硬件成本双向增长,而新的MPP技术、分布式技术出现导致在数据仓库中后期和大数据兴起时代,ETL的架构逐步走向ELT架构。例如,当年数据仓库最大厂商Teradata、至今流行的Hadoop Hive架构,都是ELT架构。它们的特点就是,将数据通过各种工具,几乎不做join,group等复杂转化,只做标准化(Normolization)直接抽取到数据仓库里数据准备层(Staging Layer),再在数据仓库中通过SQL、H-SQL,从数据准备层到数据原子层(DWD Layer or SOR Layer);后期再将原子层数据进入汇总层(DWS Layey or SMA Layer),最终到指标层(ADS Layer or IDX Layer)。虽然Teradata面向的结构化数据,Hadoop面向非结构化数据,但全球大数据和数据仓库几乎用的同一套架构和方法论来实现3-4层数据存储架构。
优点:利用数据仓库高性能计算处理大数据量处理,硬件ROI更高;同时,复杂业务逻辑可以通过SQL来用数据分析师和懂业务逻辑的技术人员来处理,而无需懂ETL(如Spark, MapReduce)降低数据处理人员总成本。
缺点:只适用于数据源比较简单、量比较大的情况,面对复杂的数据源明显处理方式不足;同时直接加载,数据准备层到数据原子层复杂度过高,无法通过SQL处理,往往利用Spark、MapReduce处理,而数据重复存储率较高;无法支持实时数据仓库等需求。
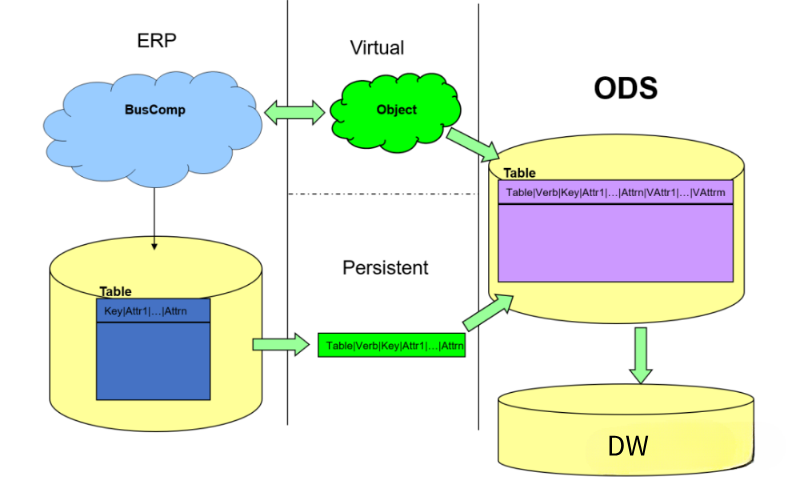
面对ELT的数据仓库无法加载复杂数据源,实时性比较差的问题,曾经有一个过渡性解决方案被各种公司方法采用,叫做ODS(Operational Data Store)方案。将复杂的数据源通过实时CDC或者实时API或者短时间批量(Micro-Batch)的方式ETL处理到ODS存储当中,然后再从ODS ELT到企业数据仓库当中,目前,还有很多企业采用此种方式处理。也有部分企业,把ODS放置在数据仓库当中,通过Spark、MapReduce完成前期的ETL工作,再在数据仓库(Hive、Teredata、Oracle、DB2)当中完成后期的业务数据加工工作。
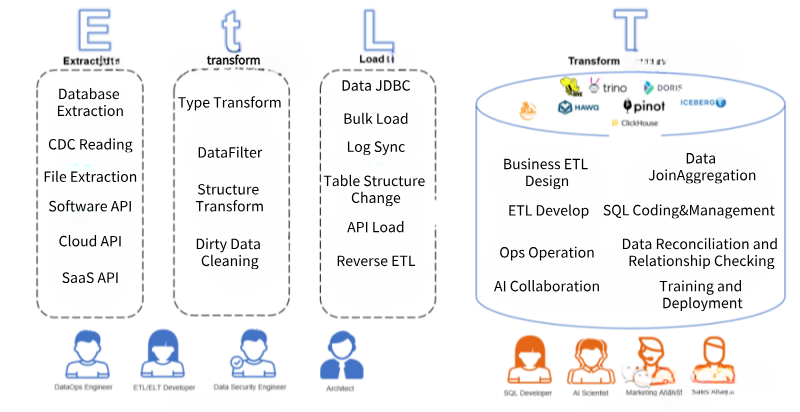
其实此时,EtLT初期的人群已经形成,它的特点是人群划分开,复杂的数据抽取、CDC、数据结构化、规整化的过程,往往由数据工程师实现,我们叫做小“t”,它的目标是从源系统到数据仓库底层数据准备层或者数据原子层;而复杂的带有业务属性的数据原子层到数据汇总层到数据指标层的处理(带有Group by、Join等复杂操作)往往是擅长使用SQL的业务数据工程师或者数据分析师来处理。
而ODS架构的独立项目也随着数据量级变大和EtLT架构的出现逐步淡出历史舞台。
EtLT (2020-未来)
EtLT的架构是由James Densmore 在《Data Pipelines Pocket Reference 2021》中总结提到的一个现代全球流行的数据处理架构。EtLT也是随着现代数据架构(Modern Data Infrastructure)变化而产生的。
EtLT架构产生的背景
在现代数据架构当中还有一种新型架构出现,它们以尽可能减少数据在不同数据存储间流动,直接通过连接器或者快速数据加载后直接提供复杂数据查询而见长,例如 Starburst的TrinoDB(前PrestDB)和基于Apache Hudi的OneHouse。这些工具都以数据缓存以及即席跨数据源查询为目标,各种ETL、ELT工具亦无法支撑新型的Big Data Federation架构。
大模型大爆发
随着2022年ChatGPT的出现,AI模型已经具备在企业应用中普及的算法基础,阻碍AI应用模型落地的更多的是数据的供给,数据湖和Big Data Federation出现解决了数据存储和查询问题。而数据供给侧,传统的ETL和ELT和流计算都形成了瓶颈,亦或无法快速打通各种复杂传统、新兴数据源、亦或无法用一套代码同时支持AI训练和AI线上的数据差异化需求。
企业数据社群分裂
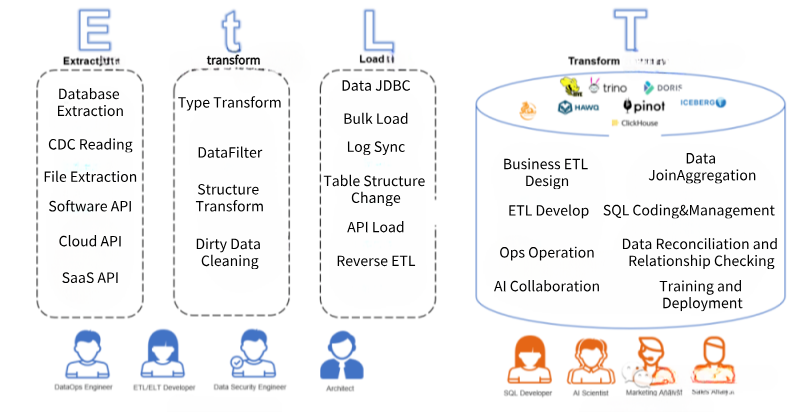
E(xtract)抽取:从数据源角度来看,支持传统的线下数据库、传统文件、传统软件同时,还要支持新兴云上数据库、SaaS软件API以及Serverless数据源的抽取;从数据抽取方式来看,需要支持实时CDC(Change Data Capture)对数据库Binlog日志的解析,也要支持实时计算(例如Kafka Streaming),同时也需要支持大批量数据读取(多线程分区读取、限流读取等)。