




PerFile中包含了对sql注入、shiro反序列化等漏洞的检测插件。PerFolder和PerServer中主要包含信息泄露检测插件。
以-u选项指定一个url进行扫描为例:
Python w13scan -u http://127.0.0.1/dvwa/vulnerabilities/sqli/?id=1
w13scan会在初始化之后,会调用loader插件来分析该url,可以从Main函数中看到这一过程:

上述命令会将url解析为:
PerFile :http://127.0.0.1/dvwa/vulnerabilities/sqli/?id=1
PerServer :http://127.0.0.1
PerFolder :http://127.0.0.1/dvwa/vulnerabilities/
PerFolder :http://127.0.0.1/dvwa/
PerFolder :http://127.0.0.1/
PerFolder :http://127.0.0.1/dvwa/vulnerabilities/sqli/
然后loader插件会调用PerFile目录下的所有插件针对
http://127.0.0.1/dvwa/vulnerabilities/sqli/?id=1
接着调用PerFolder下的所有插件攻击
http://127.0.0.1/dvwa/vulnerabilities/、http://127.0.0.1/dvwa/、http://127.0.0.1/
最后调用PerServer目录下的插件攻击
http://127.0.0.1
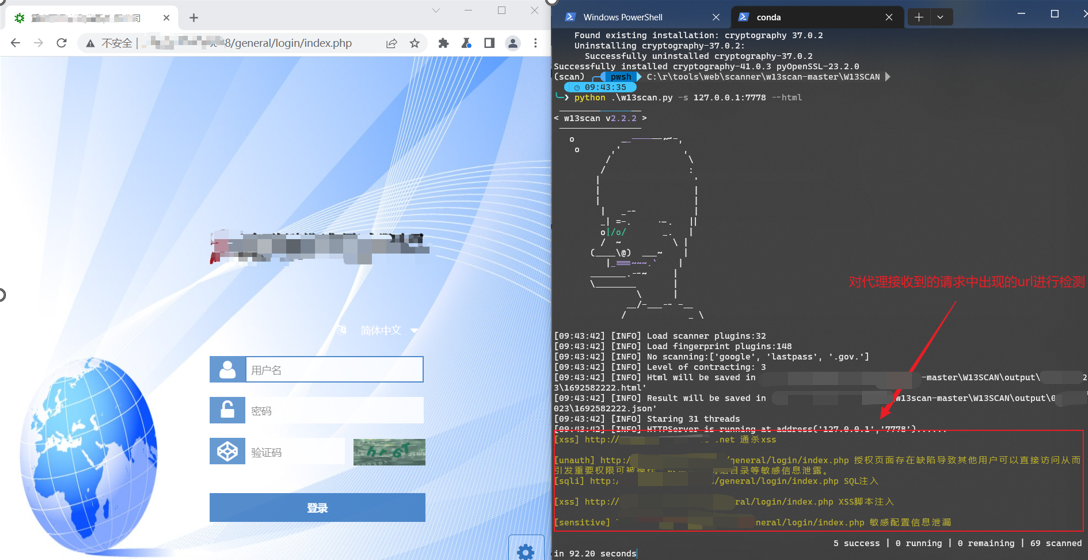
只有loader插件会创建新的任务,包括目录遍历等,因此w13scan不具备爬虫功能,只会针对给定url通过loader插件进行解析,然后调用所有的插件进行检测。整个过程示意图如下: