一次插入多条数据
insert into t_user(字段名1,字段名2) values(),(),(),();
insert into t_user(id,name,birth,create_time) values
(1,'zs','1980-10-11',now()),
(2,'lisi','1981-10-11',now()),
(3,'wangwu','1982-10-11',now());
复制代码
2.4修改数据update
update 表名 set 字段名1=值1,字段名2=值2,字段名3=值3... where 条件;
没有条件限制会导致所有数据全部更新。
update t_user set name = 'jack', birth = '2000-10-11' where id = 2;
update t_user set name = 'jack', birth = '2000-10-11', create_time = now() where id = 2;
复制代码
2.5删除数据
delete语句删除数据的原理?(delete属于DML语句!!!)
表中的数据被删除了,但是这个数据在硬盘上的真实存储空间不会被释放!!!
这种删除缺点是:删除效率比较低。
这种删除优点是:支持回滚,后悔了可以再恢复数据!!!
truncate语句删除数据的原理?
这种删除效率比较高,表被一次截断,物理删除。
这种删除缺点:不支持回滚。
这种删除优点:快速。
2.5.1delete
delete from 表名 where 条件;
没有条件,整张表的数据会全部删除!
delete from t_user where id = 2;
2.5.2truncate
truncate table dept_bak; (这种操作属于DDL操作。)
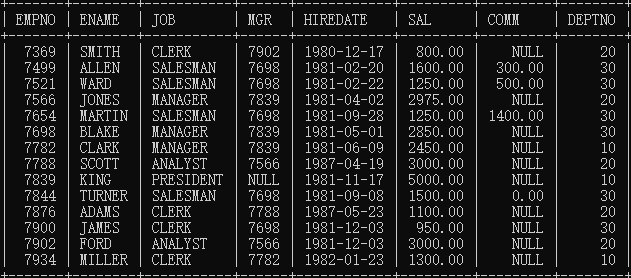
下列演示内容所用表 emp 员工表
salgarde 工资等级表
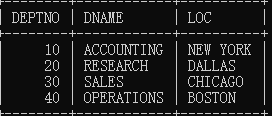
dept 部门表
3.基础增删改
3.单表查询
3.1基础条件查询
select 字段1,字段2,字段3.... from 表名 where 条件;
= 等于
查询薪资等于800的员工姓名和编号?
select empno,ename from emp where sal = 800;
查询SMITH的编号和薪资?
select empno,sal from emp where ename = 'SMITH'; //字符串使用单引号
复制代码
或!= 不等于
查询薪资不等于800的员工姓名和编号?
select empno,ename from emp where sal != 800;
select empno,ename from emp where sal 800; // 小于号和大于号组成的不等号 < 小于 <strong>=) 大于等于**
查询薪资小于等于3000的员工姓名和编号?
select empno,ename,sal from emp where sal <= 3000;
复制代码
and 并且 or 或者
查询薪资大于等于3000的员工姓名和编号?
select empno,ename,sal from emp where sal >= 3000;
between … and …. 两个值之间, 等同于 >= and <=
查询薪资在2450和3000之间的员工信息?包括2450和3000
第一种方式:>= and <= (and是并且的意思。)
select empno,ename,sal from emp where sal >= 2450 and sal <= 3000;
复制代码
in 包含,相当于多个 or (not in 不在这个范围中)
查询哪些员工的津贴/补助为null?
mysql> select empno,ename,sal,comm from emp where comm = null;
查询哪些员工的津贴/补助不为null?
select empno,ename,sal,comm from emp where comm is not null;
复制代码
not 可以取非,主要用在 is 或 in 中
select * from emp where sal > 2500 and (deptno = 10 or deptno = 20);
第三点:分组函数不能够直接使用在where子句中。 找出比最低工资高的员工信息。 select ename,sal from emp where sal > min(sal); 表面上没问题,运行一下? ERROR 1111 (HY000): Invalid use of group function
5.分组查询
5.1 group by
找出每个工作岗位的工资和?
lower 转换小写
mysql> select lower(ename) as ename from emp;
upper 转换大写
mysql> select * from t_student;
substr 取子串(substr( 被截取的字符串, 起始下标,截取的长度))
select substr(ename, 1, 1) as ename from emp;
注意:起始下标从1开始,没有0.
找出员工名字第一个字母是A的员工信息?
第一种方式:模糊查询
select ename from emp where ename like 'A%';
第二种方式:substr函数
select
ename
from
emp
where
substr(ename,1,1) = 'A';
concat函数进行字符串的拼接
select concat(empno,ename) from emp;
length 取长度
select length(ename) enamelength from emp;
trim 去空格
mysql> select * from emp where ename = ' KING';
str_to_date 将字符串转换成日期
date_format 格式化日期
format 设置千分位
round 四舍五入
select 字段 from 表名;
select ename from emp;
select 'abc' from emp; // select后面直接跟“字面量/字面值”
mysql> select 'abc' as bieming from emp;
select round(1236.567, 1) as result from emp; //保留1个小数
select round(1236.567, 2) as result from emp; //保留2个小数
select round(1236.567, -1) as result from emp; // 保留到十位。
rand() 生成随机数
mysql> select round(rand()*100,0) from emp; // 100以内的随机数
ifnull 可以将 null 转换成一个具体值
ifnull是空处理函数。专门处理空的。
在所有数据库当中,只要有NULL参与的数学运算,最终结果就是NULL。
mysql> select ename, sal + comm as salcomm from emp;