ToB企服应用市场:ToB评测及商务社交产业平台
标题:
Spark快速上手(1)window下环境配置
[打印本页]
作者:
立聪堂德州十三局店
时间:
2022-8-20 22:38
标题:
Spark快速上手(1)window下环境配置
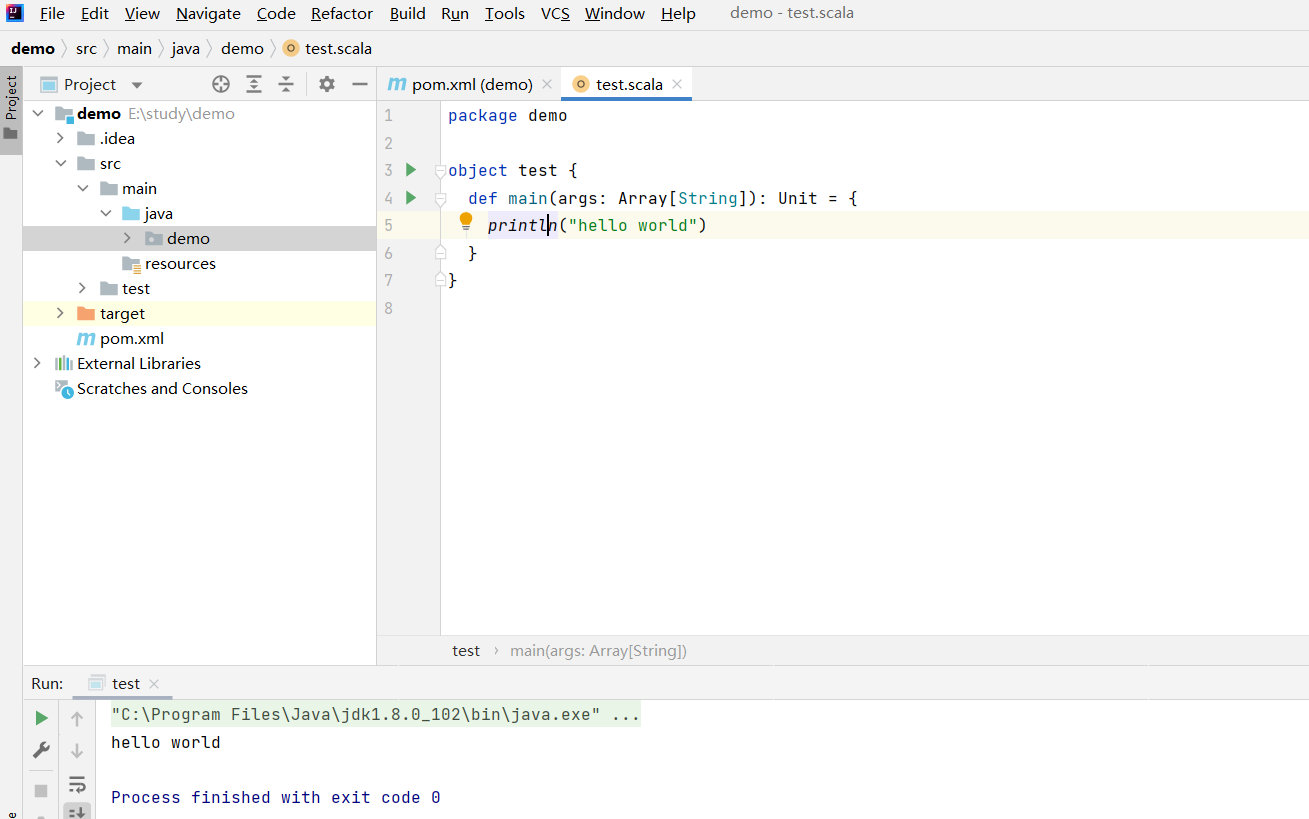
笔者使用的开发环境是IntelliJ IDEA Community Edition 2021.3.3
scala版本是2.11.8,与Spark2.0严格对应。
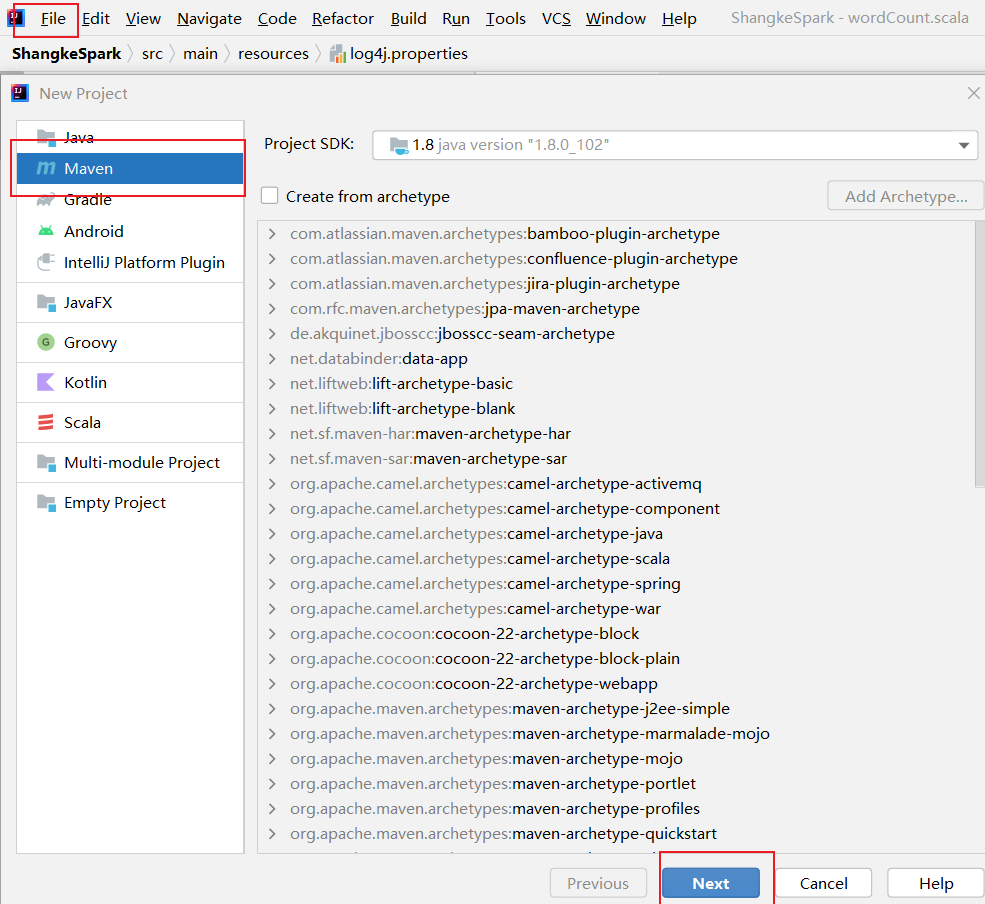
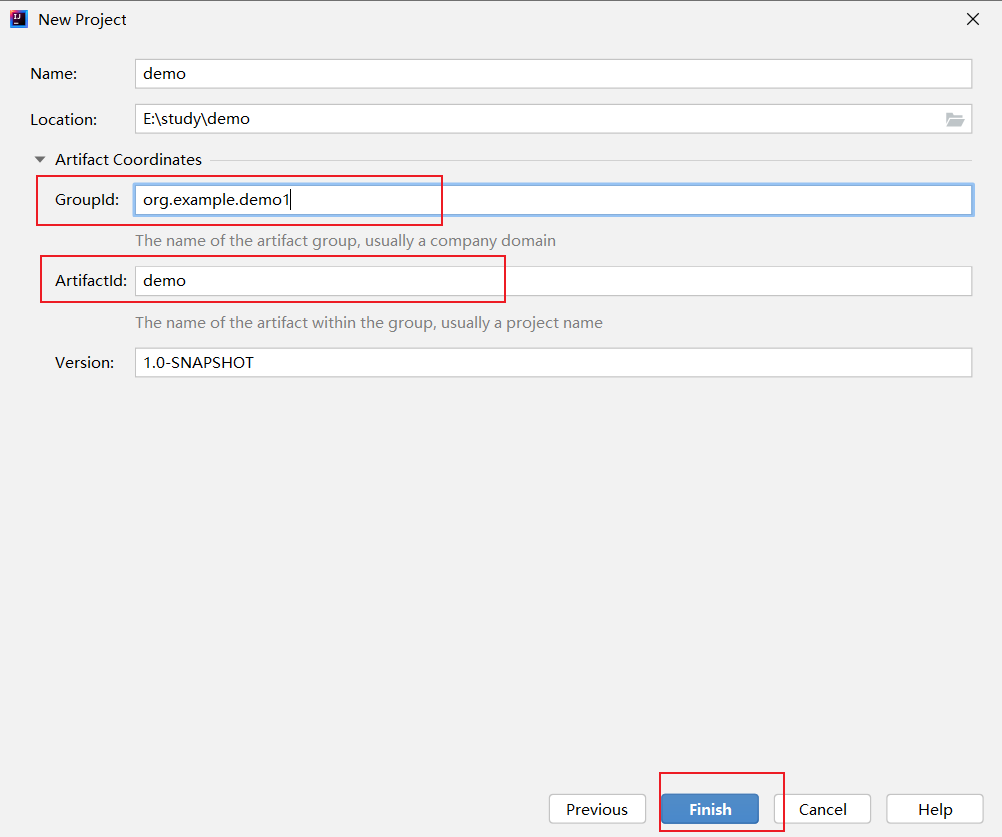
在maven环境中导入scala框架
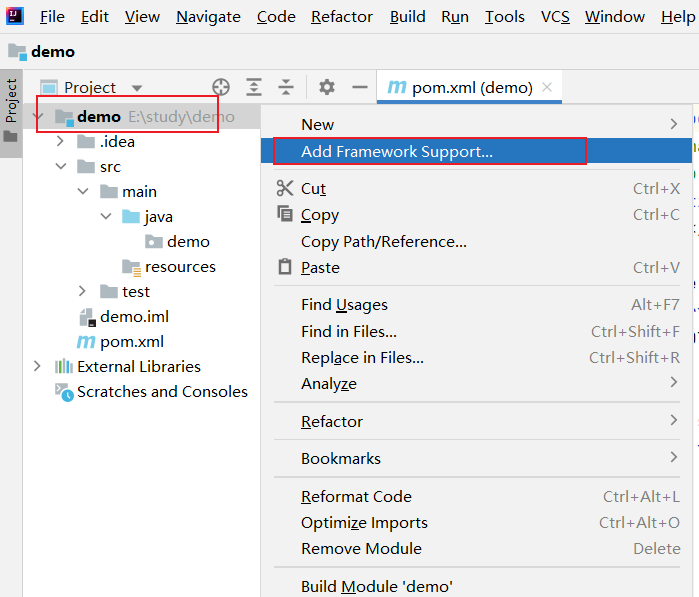
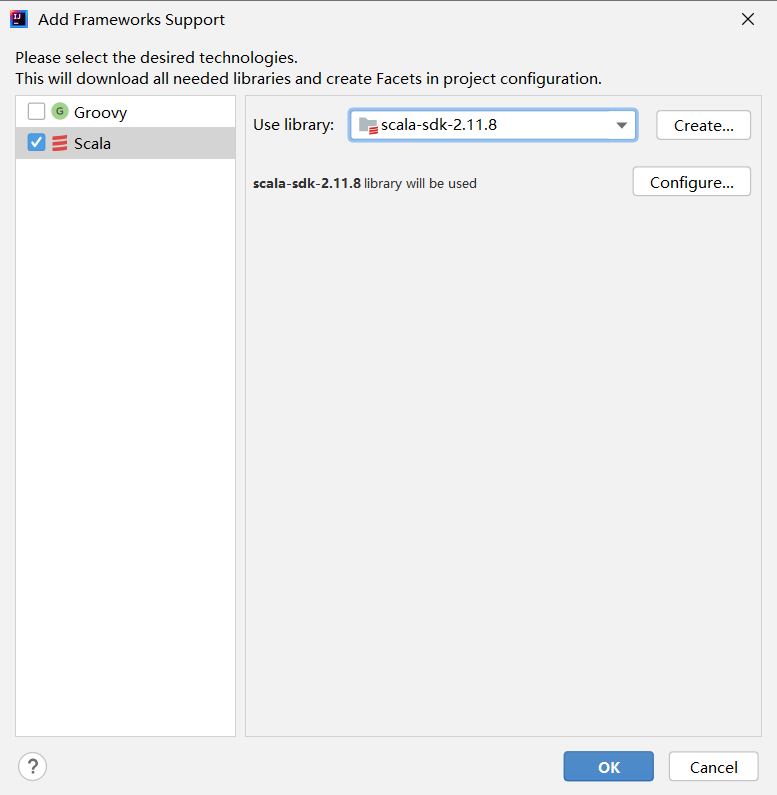
导入Scala框架
导入成功后在main/java 路径中可以创建新的scala类
至此,scala 配置完成。
spark 框架调用测试WordCount案例
①首先,检查一下 spark相关导包是否正常
scala、hadoop版本都要满足spark版本。
其中hadoop为了能在window系统下运行,需要下载
https://github.com/cdarlint/winutils
中对应的版本bin目录中的hadoop.dll和winutils.exe,添加到hadoop的bin目录下。
但是笔者尝试发现,官网下载的最旧版本的spark 和 hadoop 难以适配上述代码仓库中很久没有更新的文件,故尝试利用手头实验使用的文件适配。
笔者使用版本:
scala-2.11.8
spark-2.0.0-bin-hadoop2.7
hadoop-2.7.7
使用的文件在如下链接中分享
链接:
https://pan.baidu.com/s/1e3BAlF0SaPMn8iXp9v5fYA
提取码:unsk
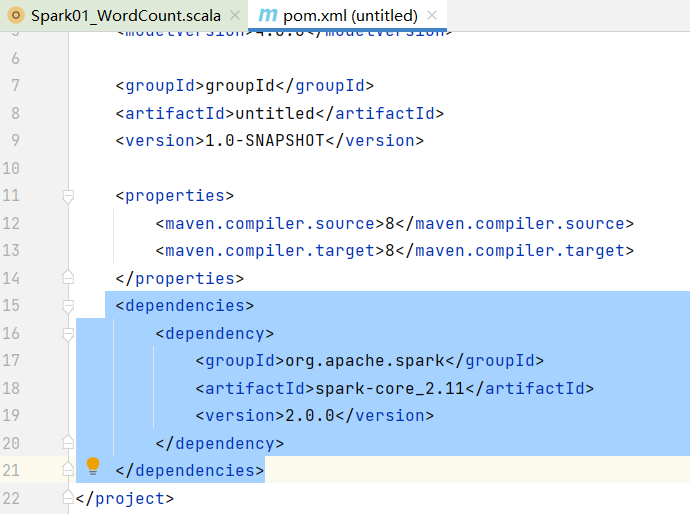
②然后,在pom文件中添加依赖,这个是版本严格对应的
代码如下:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>
复制代码
[/code] ③添加spark框架
[img]https://img2022.cnblogs.com/blog/2409071/202206/2409071-20220630150537218-1545502031.png[/img]
[img]https://img2022.cnblogs.com/blog/2409071/202206/2409071-20220630150519945-1971768785.png[/img]
[img]https://img2022.cnblogs.com/blog/2409071/202206/2409071-20220630150710639-344044536.png[/img]
这样,scala中就能正常导入spark包了
[img]https://img2022.cnblogs.com/blog/2409071/202206/2409071-20220630150759685-749726147.png[/img]
④hadoop 相关需要注意的配置
如果是直接使用的我传的文件,只需要添加系统变量 HADOOP_HOME:hadoop文件夹路径
Path:hadoop文件夹/bin 路径 即可
如果使用的hadoop文件是自己的,请满足提示①的前提下完成上述步骤
⑤wordCount.scala 样例
代码如下
[code]package demo<br><br>import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}<br><br>object wordCount {
def main(args: Array[String]): Unit = {
// 创建 Spark 运行配置对象
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建 Spark 上下文环境对象(连接对象)
val sc : SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.textFile("input/word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭 Spark 连接
sc.stop()
}
}
复制代码
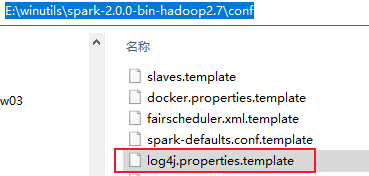
需要在demo目录下创建 input文件夹,并在其中添加word.txt文件<br>⑥关于log日志:<br>运行程序过程中会产生大量日志,为了更好地查看执行结果,可以在src/main/resources目录下创建log4j.properties文件,添加<br>日志配置来取消显示<br><br>spark包中提供对应的模板,不过是临时文件。<br><br>
复制代码
[/code][img]https://img2022.cnblogs.com/blog/2409071/202206/2409071-20220630152951218-105662405.png[/img]
将新文档中 rootCategory一行中第一个值改为ERROR即可
⑦[b]笔者在尝试运行scala示例过程中曾报出 xxx not found的错误,后经排查发现是部分框架文件没用成功传至maven仓库中,后通过手动添加转移的办法解决了这一问题。[b]经检查,maven仓库地址在C盘符(应为idea默认目录),故[/b]笔者认为该情况的发生可能跟开发环境没有赋予管理员权限运行有关。[/b]
[code]<br><br>
复制代码
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/)
Powered by Discuz! X3.4