更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
 从分布式架构来看,ByteHouse 具备 MPP 1.0 特点:
从分布式架构来看,ByteHouse 具备 MPP 1.0 特点: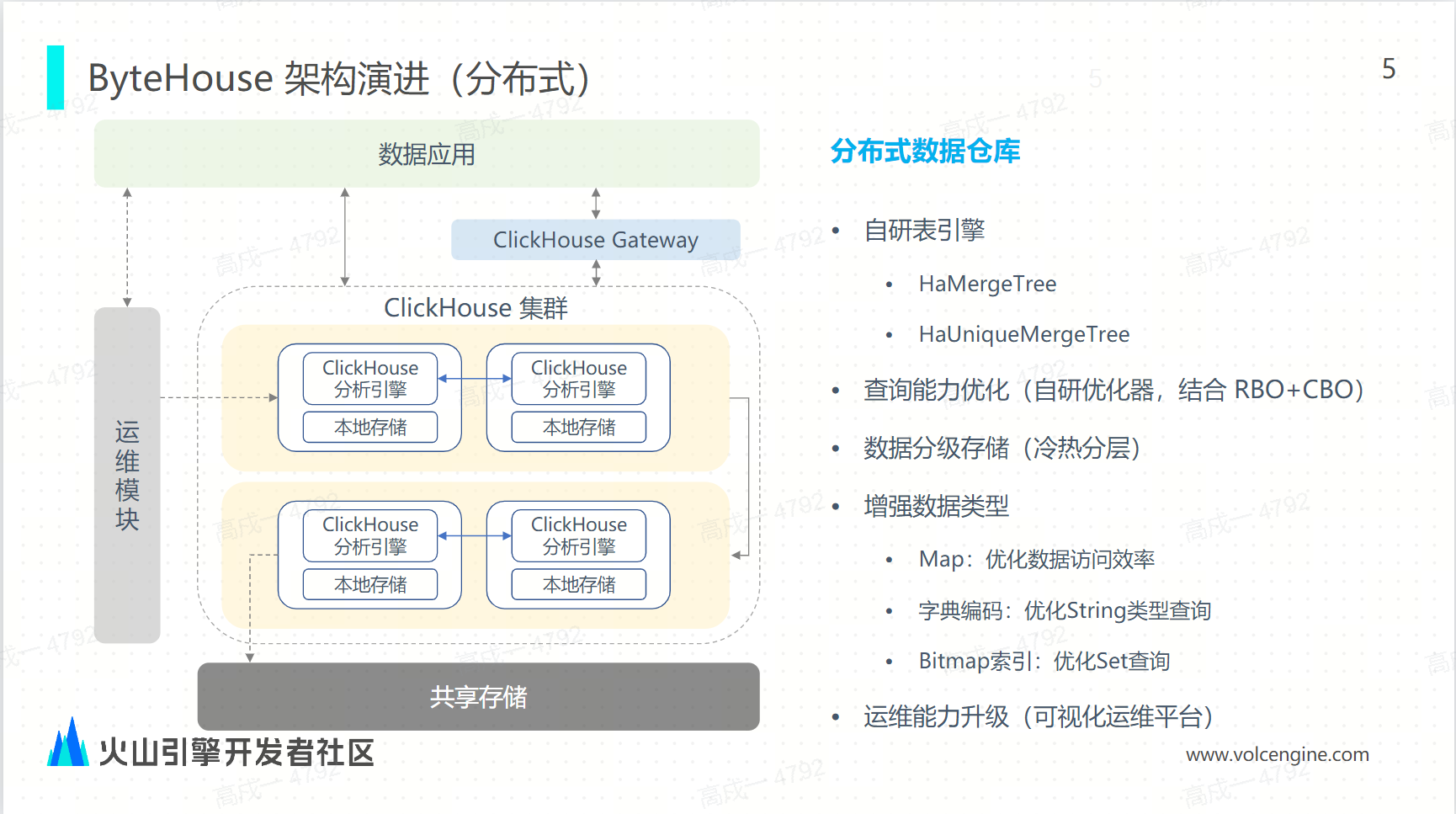 但 MPP 1.0 存在资源隔离、扩容等痛点,由此演进到云原生架构,即 MPP 2.0:其中存算分离通过结合 shared-everything 存储和 shared-nothing 计算层,避免了传统 MPP 架构中数据重新分配 (re-sharding) 的问题。
但 MPP 1.0 存在资源隔离、扩容等痛点,由此演进到云原生架构,即 MPP 2.0:其中存算分离通过结合 shared-everything 存储和 shared-nothing 计算层,避免了传统 MPP 架构中数据重新分配 (re-sharding) 的问题。 ByteHouse 技术优势
ByteHouse 技术优势 这里具体再介绍一下 ByteHouse 自研引擎的优势——与导入密切相关的表引擎。
这里具体再介绍一下 ByteHouse 自研引擎的优势——与导入密切相关的表引擎。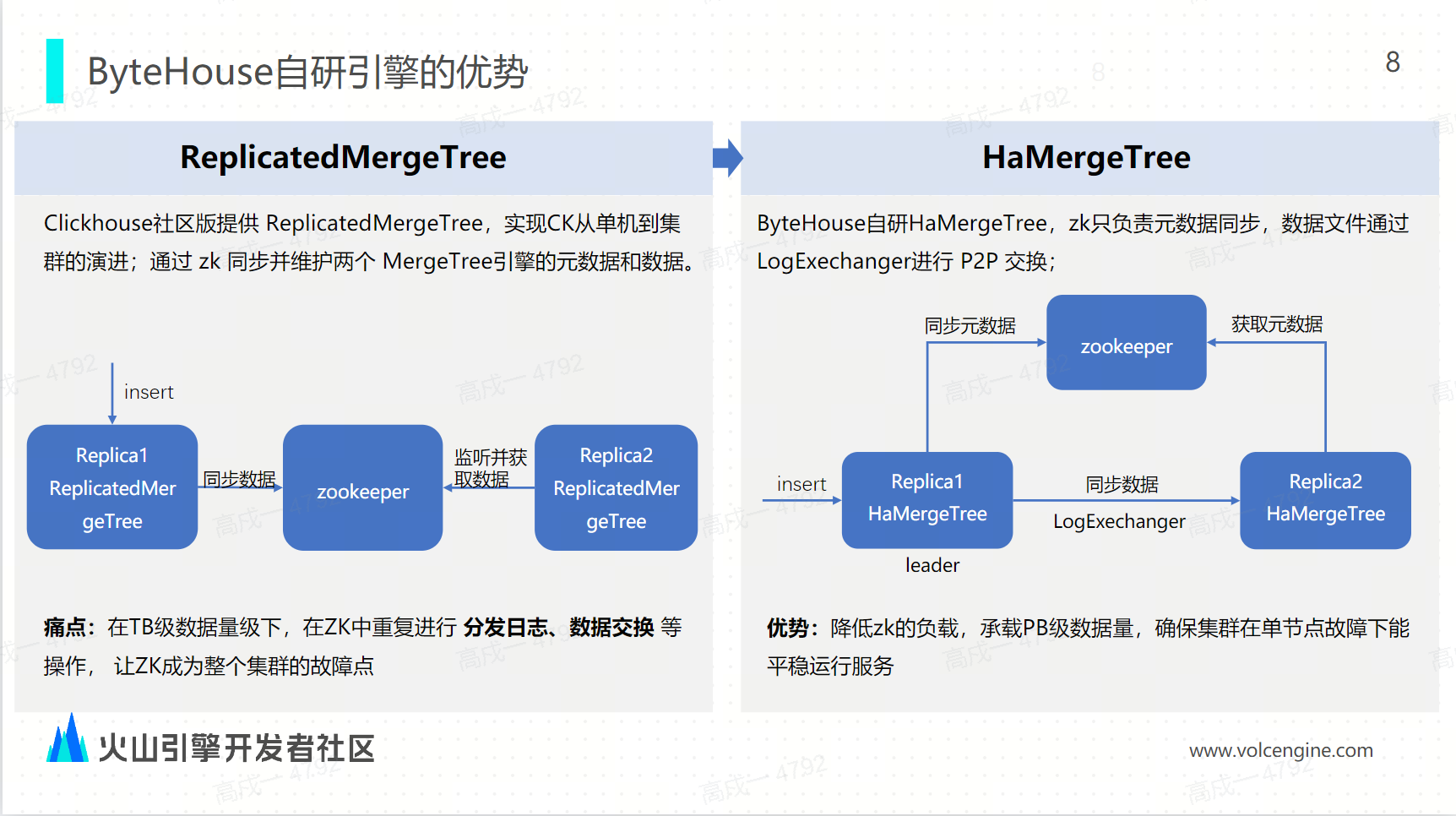



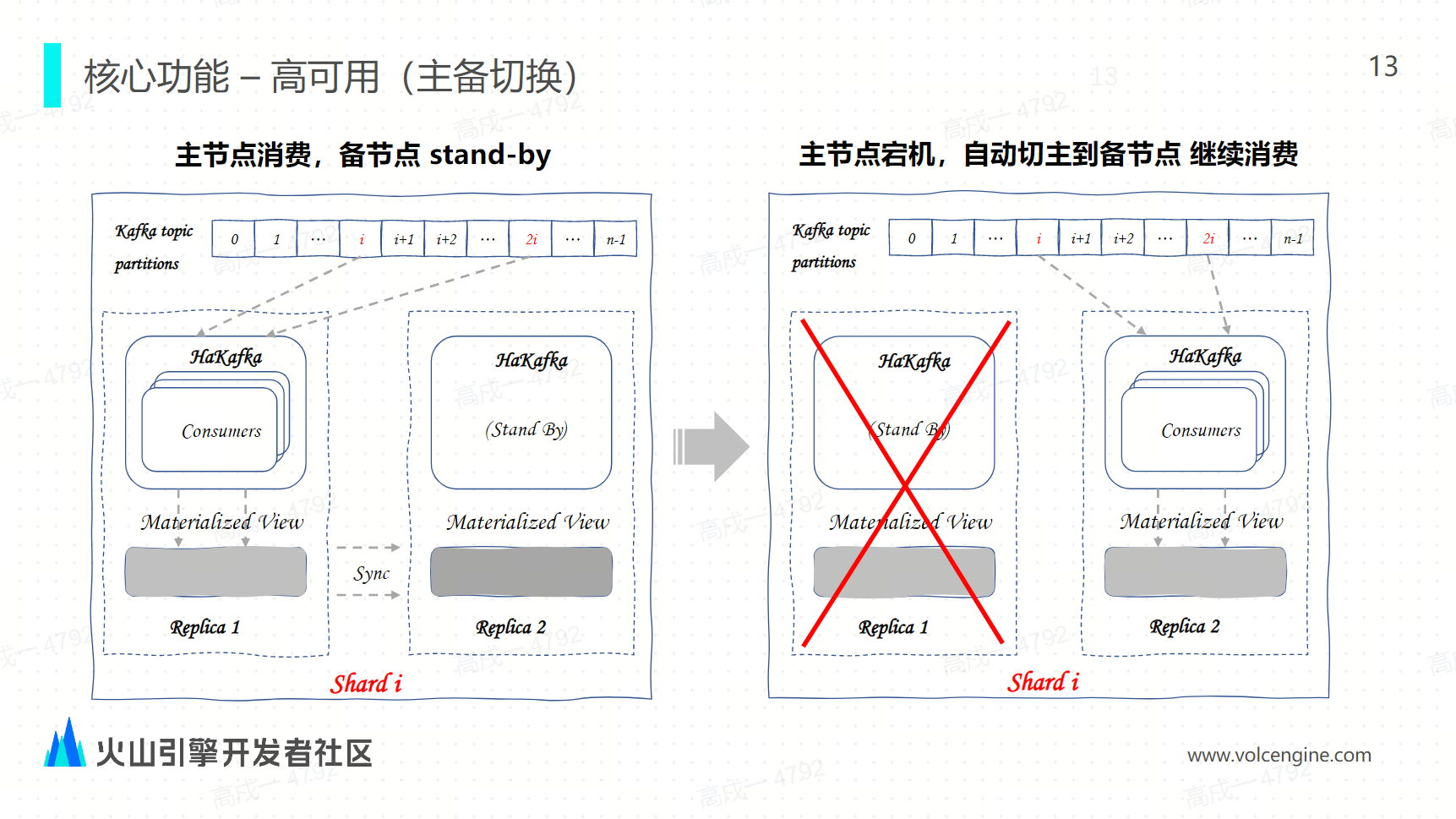
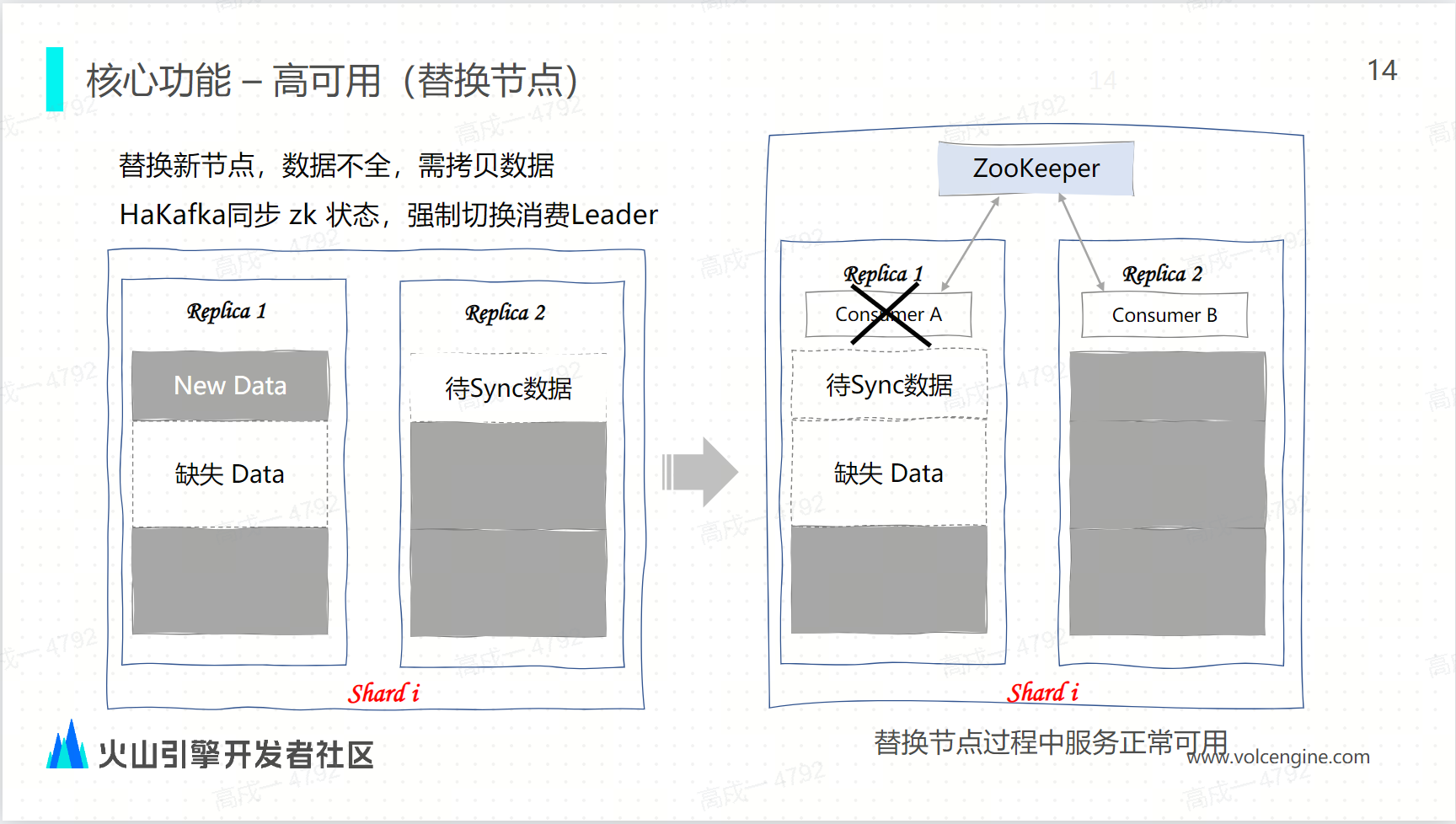
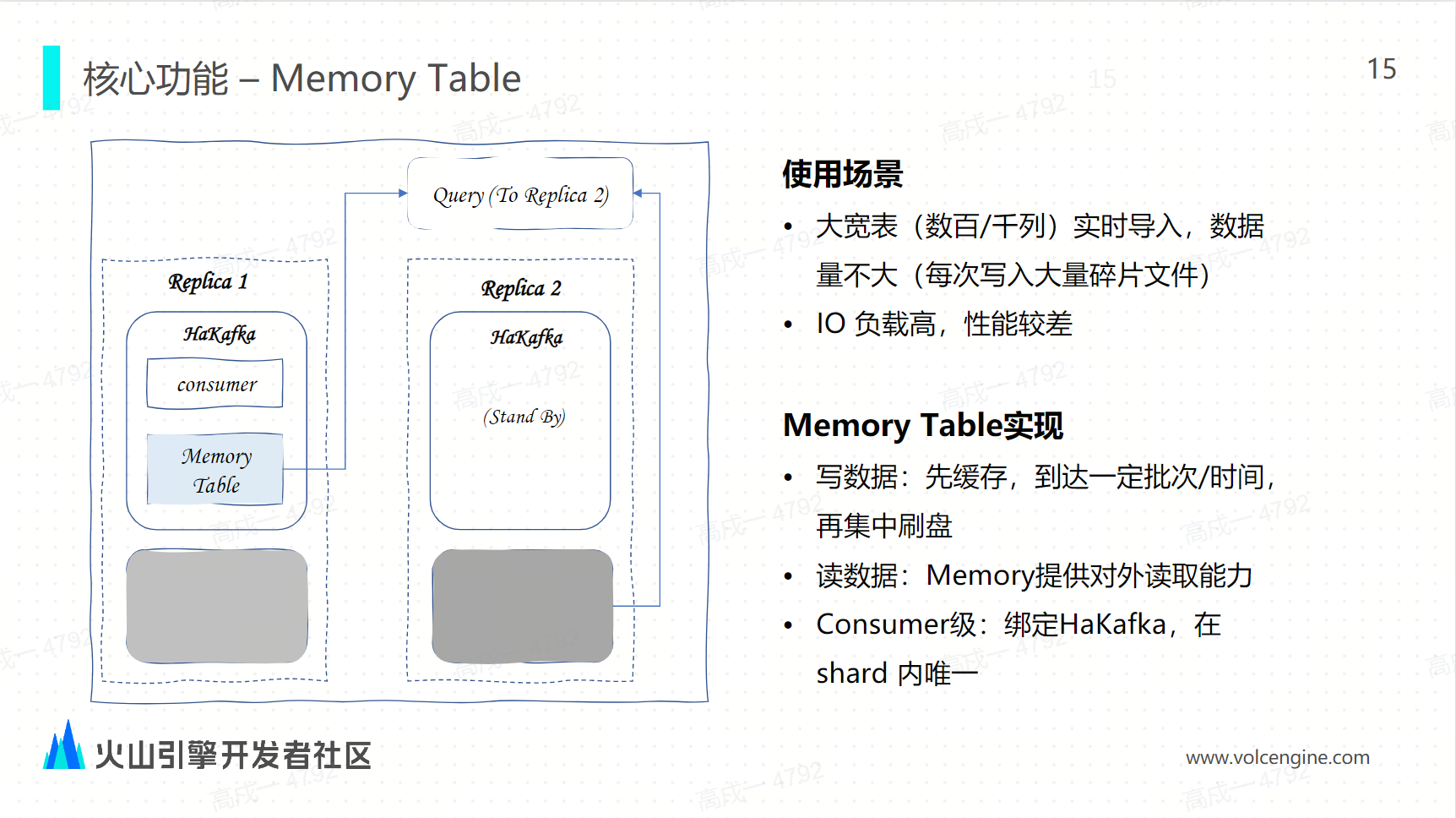
 在云原生架构下的 Kafka 引擎是如何通过事务来实现 exactly once:
在云原生架构下的 Kafka 引擎是如何通过事务来实现 exactly once: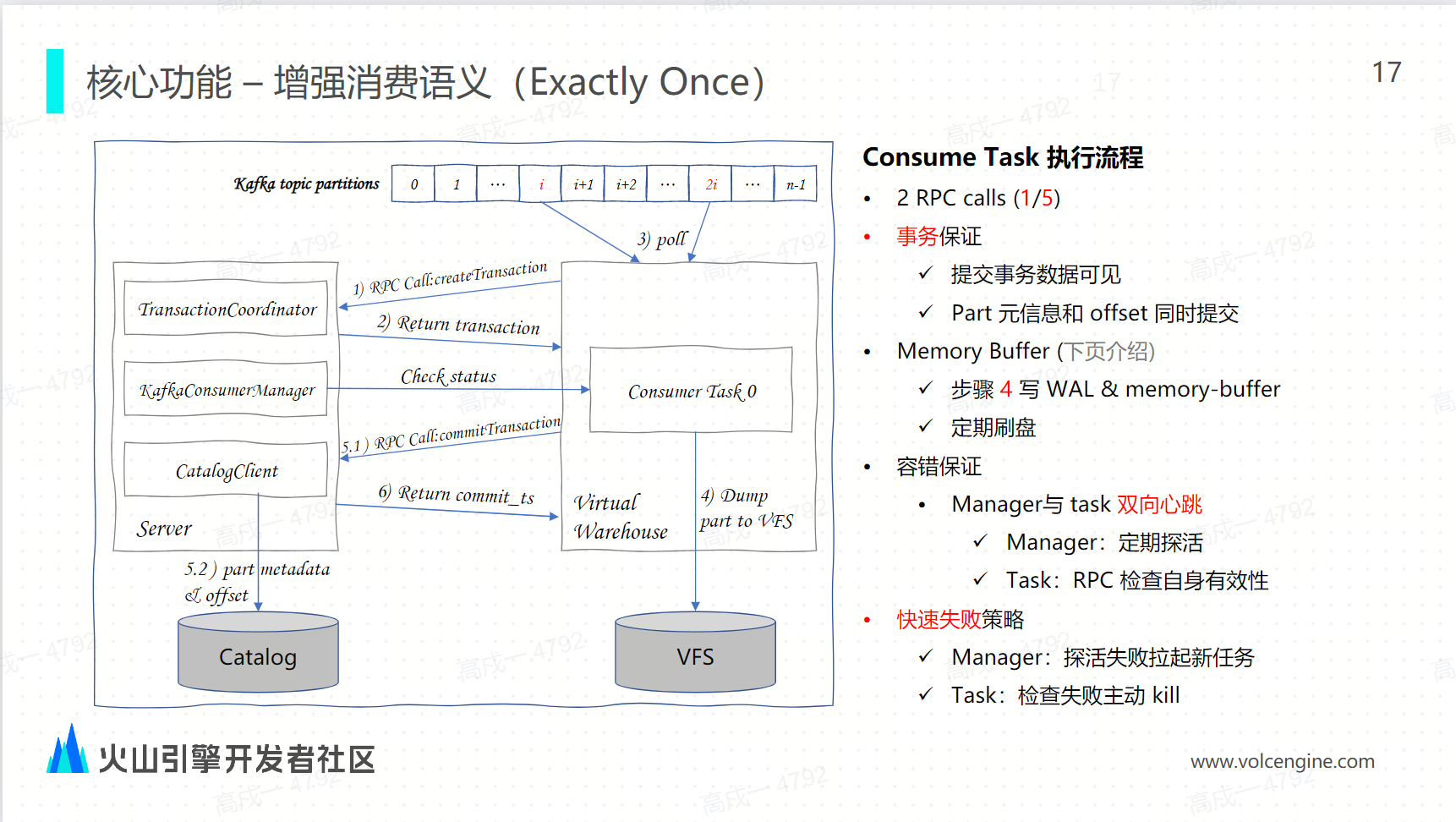
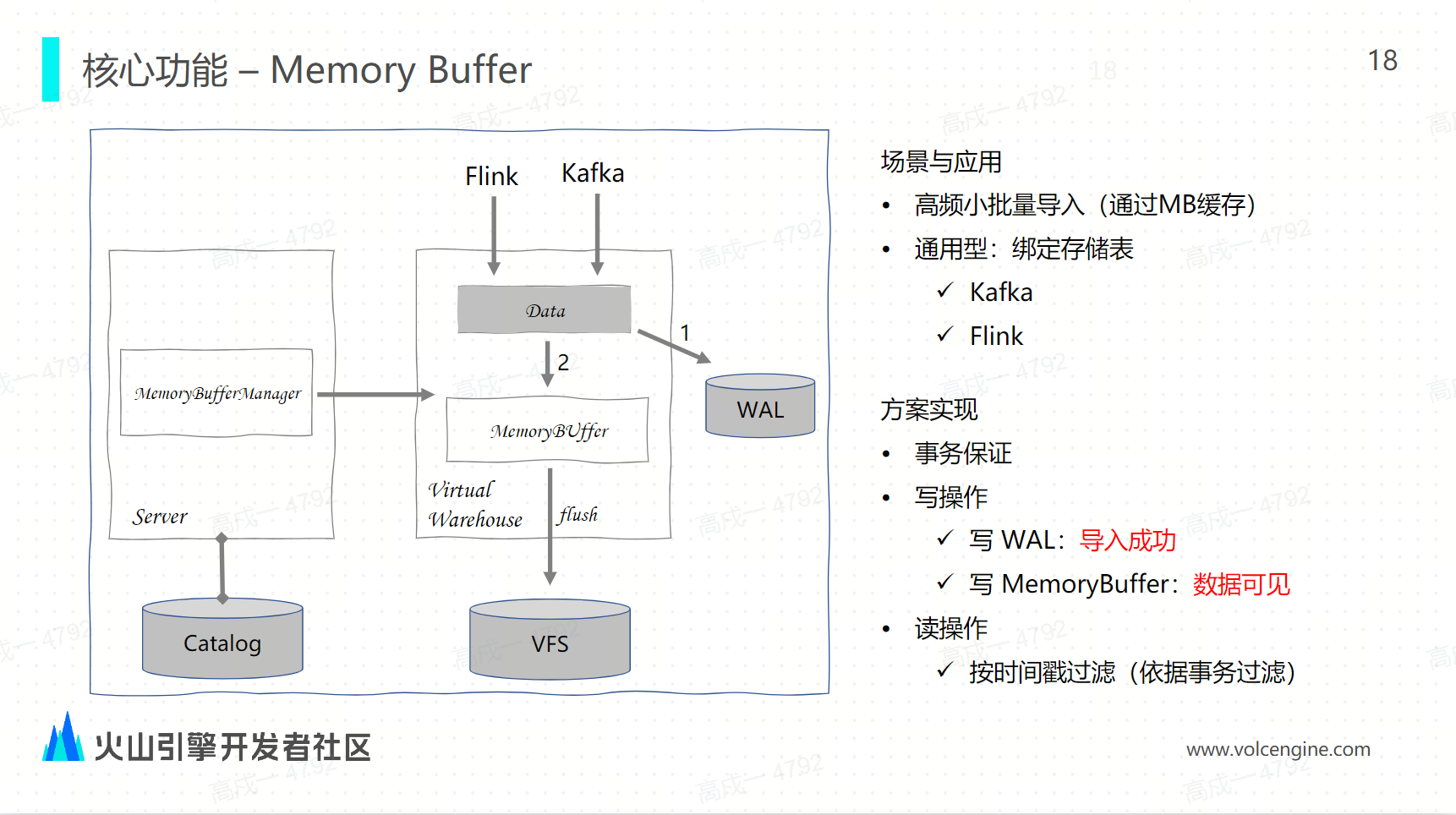 增强 Materialzed MySQL 实现方案
增强 Materialzed MySQL 实现方案 ByteHouse 的物化 MySQL 结合了 HaUniqueMergeTree 表引擎:结合这样的表引擎之后,它就能够实现数据的实时去重能力,同时它能够支持分布式的能力,我们通过底层的中间的参数优化,比如 include tables、 exclude tables、 SKIP DDL 等等能够允许用户自定义同步的表的同步范围。
ByteHouse 的物化 MySQL 结合了 HaUniqueMergeTree 表引擎:结合这样的表引擎之后,它就能够实现数据的实时去重能力,同时它能够支持分布式的能力,我们通过底层的中间的参数优化,比如 include tables、 exclude tables、 SKIP DDL 等等能够允许用户自定义同步的表的同步范围。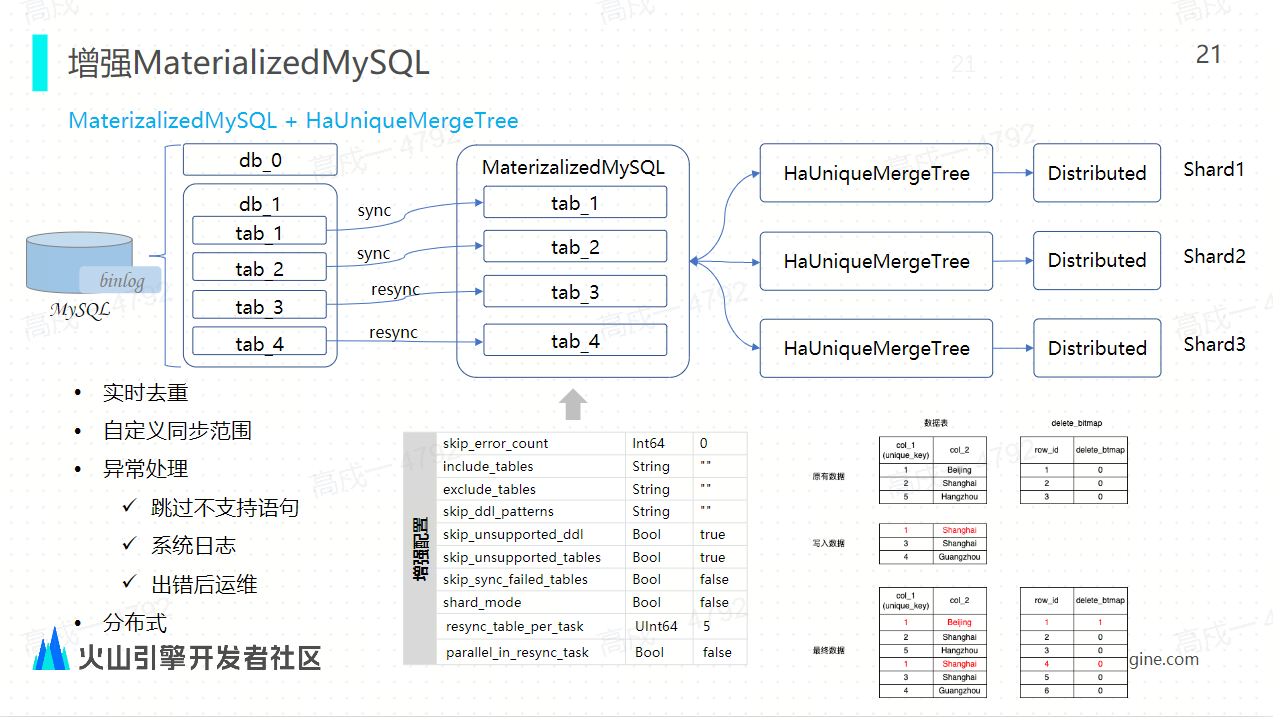 ByteHouse 增强 Materialzed MySQL 核心功能实现
ByteHouse 增强 Materialzed MySQL 核心功能实现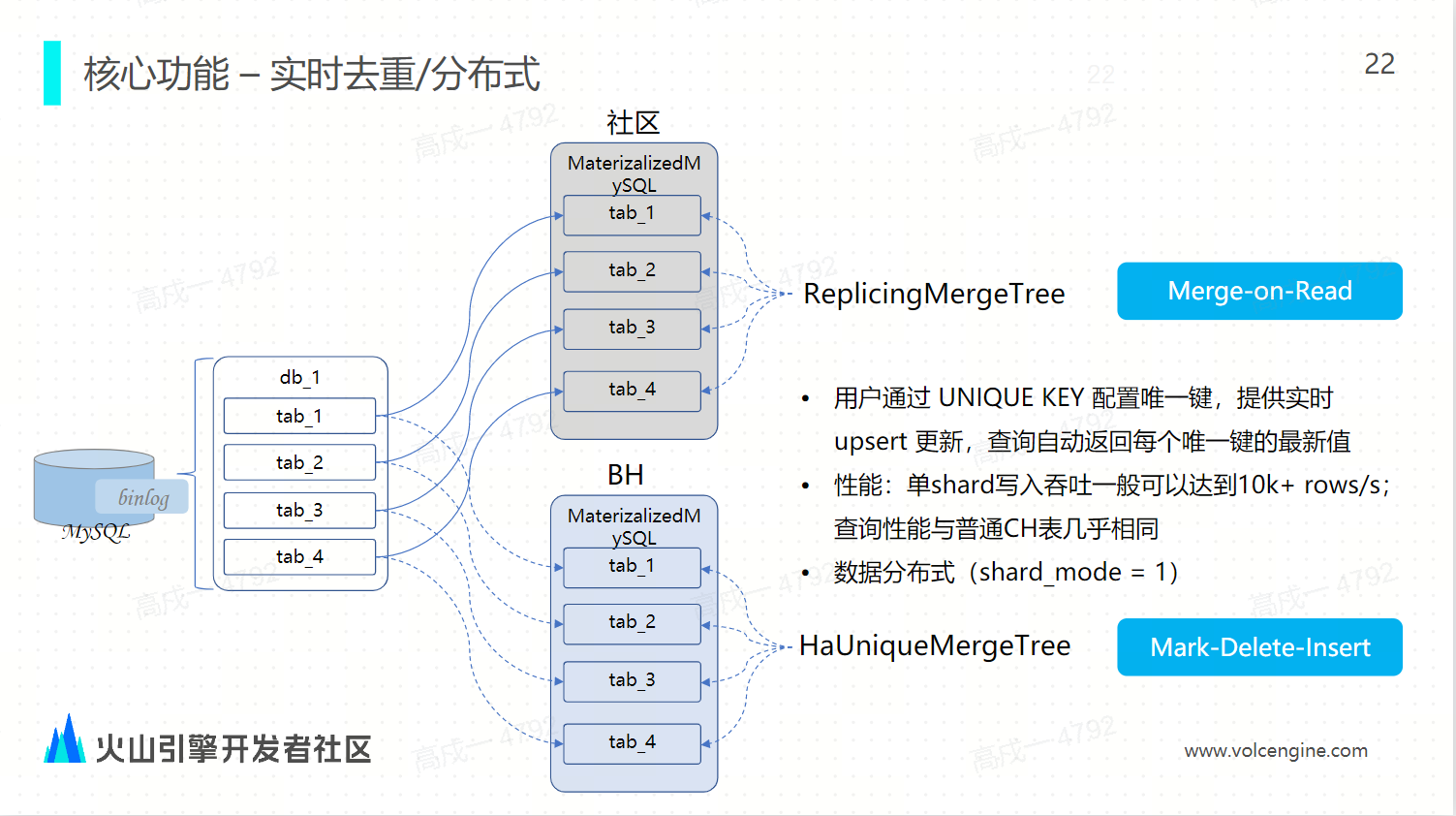
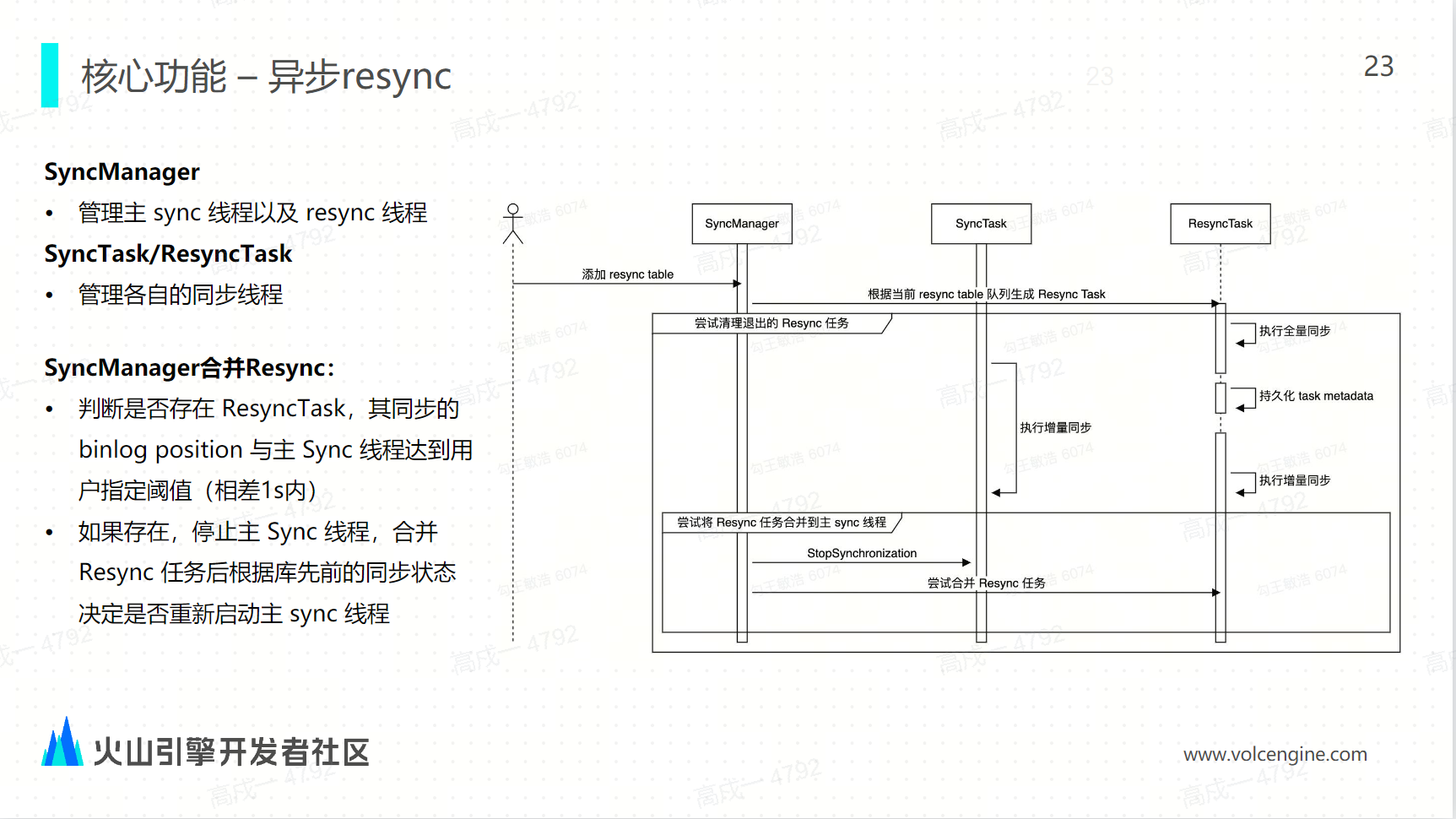
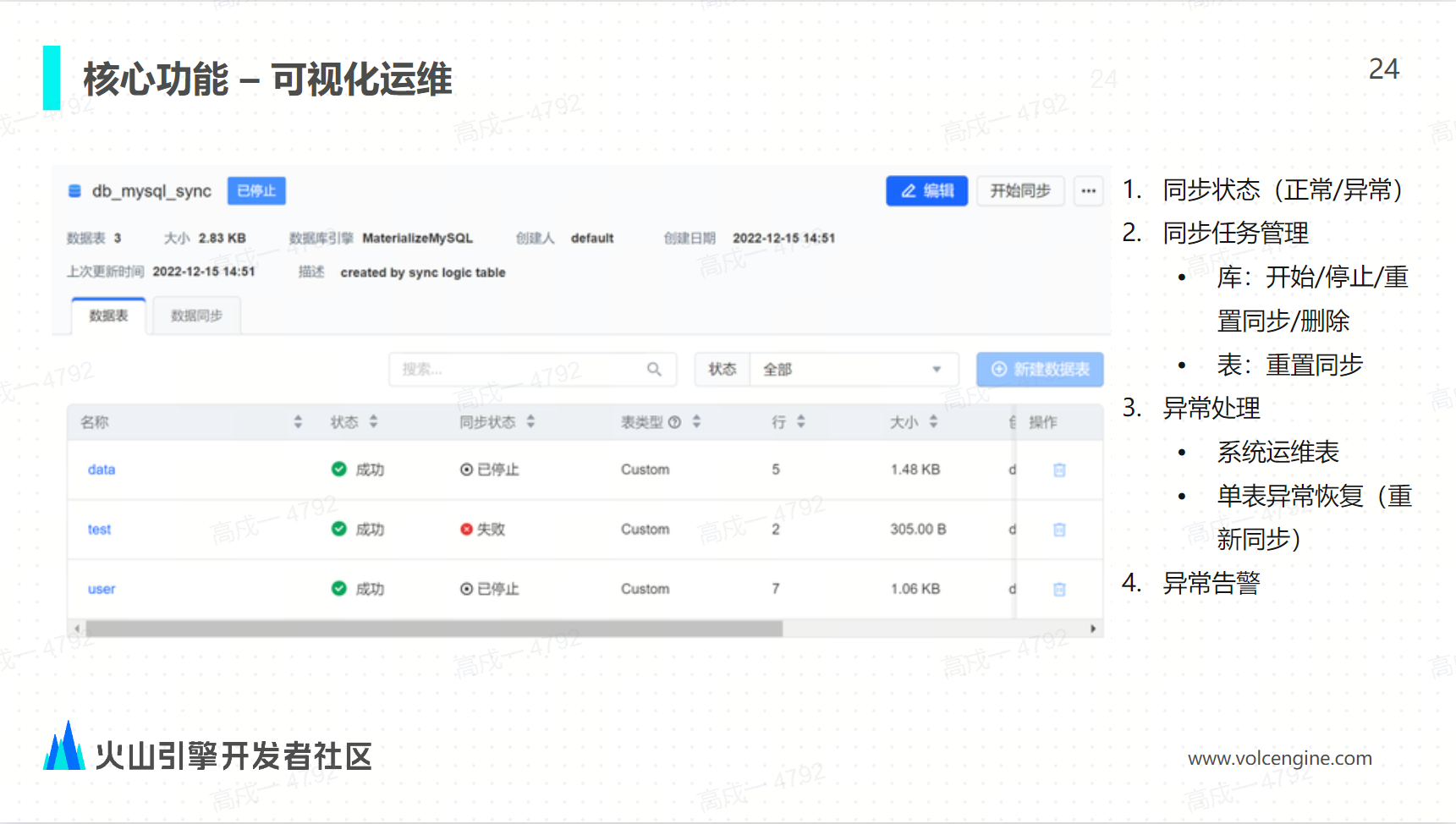 案例实践与未来展望
案例实践与未来展望 案例二:营销实时数据的监控
案例二:营销实时数据的监控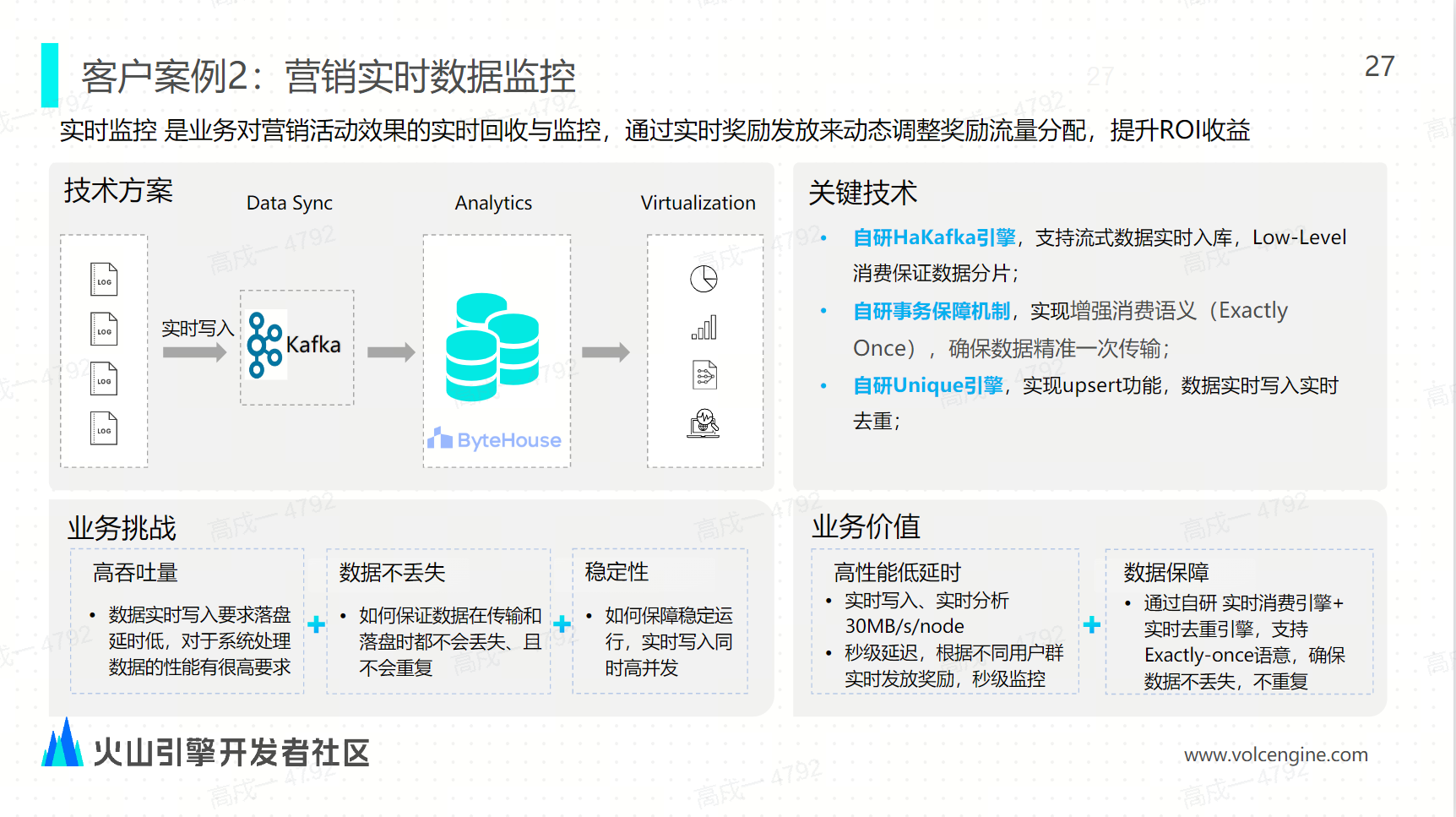 案例三:游戏广告的数据分析
案例三:游戏广告的数据分析 未来战略:全链路和一体化
未来战略:全链路和一体化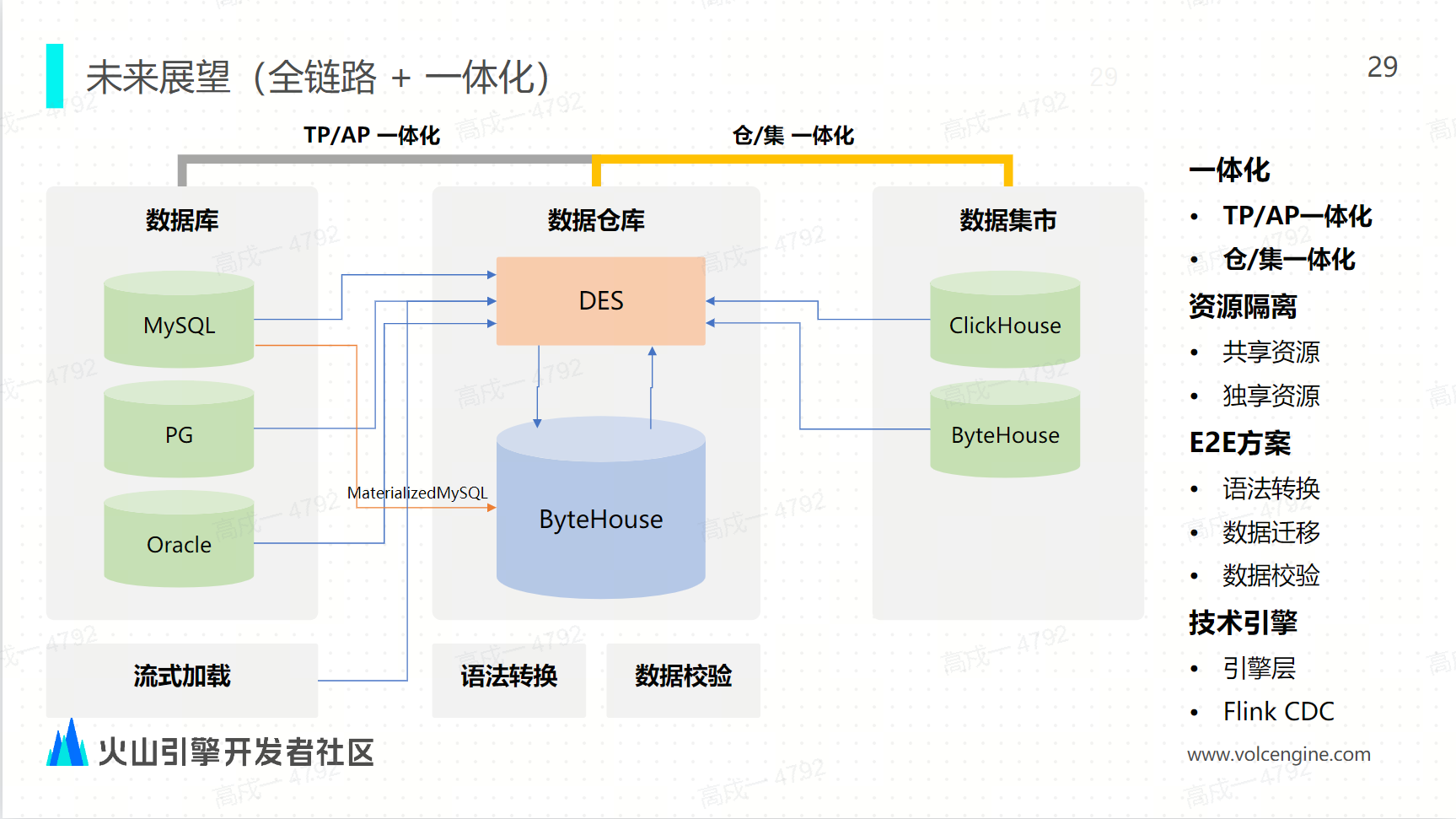
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |