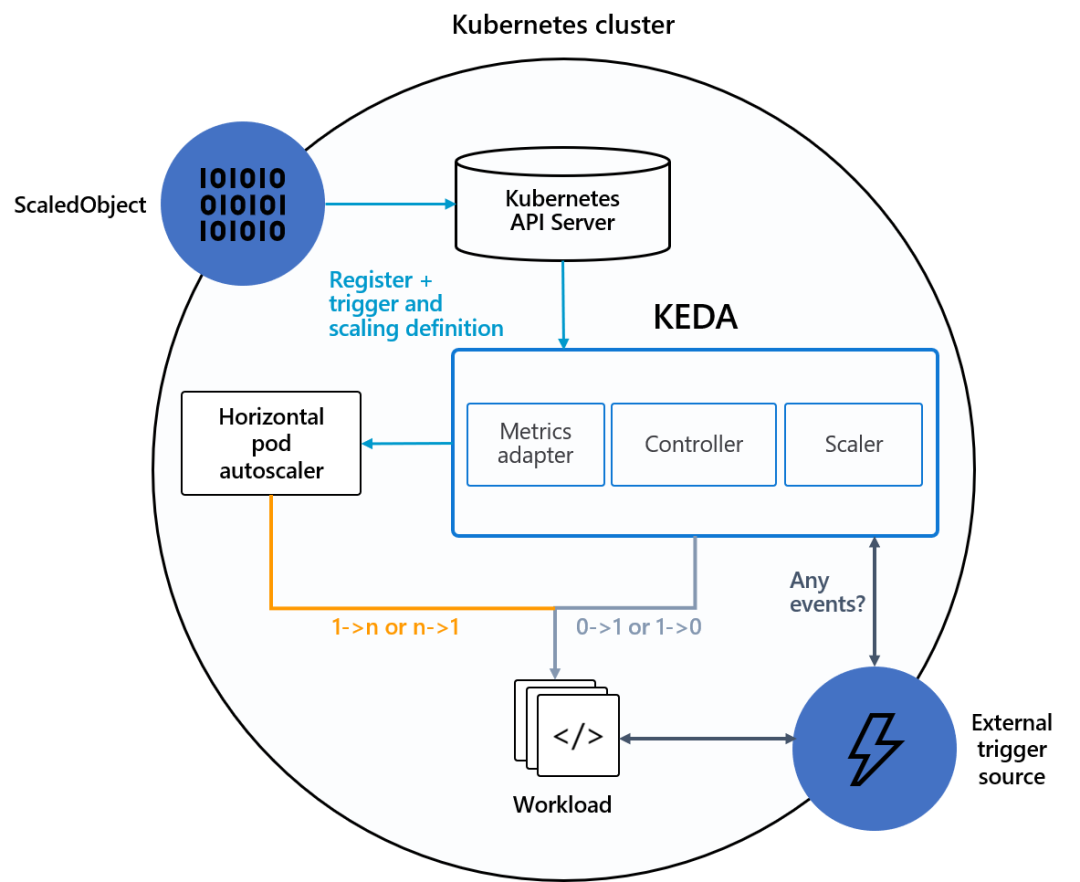

说明:4.1 定时弹性
原生Deployment对象不支持灰度发布策略,所以改用 Argo-Rollout 资源对象,下面示例均采用 Argo-Rollout 演示
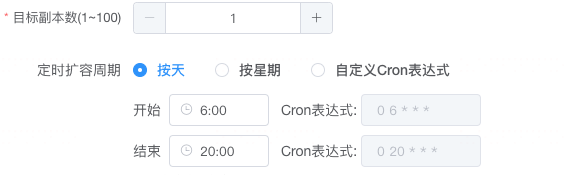
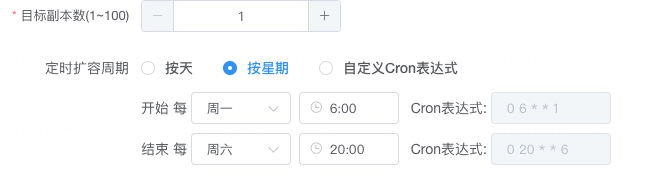

说明:
基于 Prometheus 拉取真实资源使用情况,并屏蔽刚启动的 Pod
-default 为基线应用,cluster、zone 是 Prometheus remote_write 到 VictoriaMetrics 新增便签,便于区分集群和区域
VictoriaMetrics 是统一汇总、查询层,方便不同集群使用一套数据源
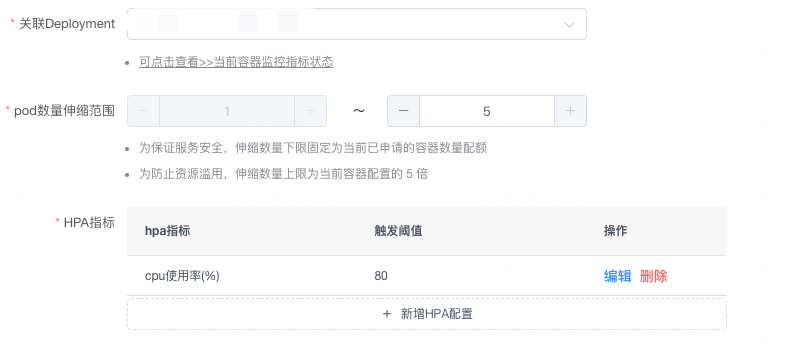
说明:
QPS 取自 CAT 数据,SRE这边将 CAT 数据使用工具写入到 VictoriaMetrics 中
前端设计、消息通知 和 基于资源的弹性使用的一套模版,都属于基于指标触发的 HPA,这里不再赘述
⚠️ HPA 在计算目标副本数时会有一个10%的波动因子。如果在波动范围内,HPA 并不会调整副本数目。缩容时间
| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |