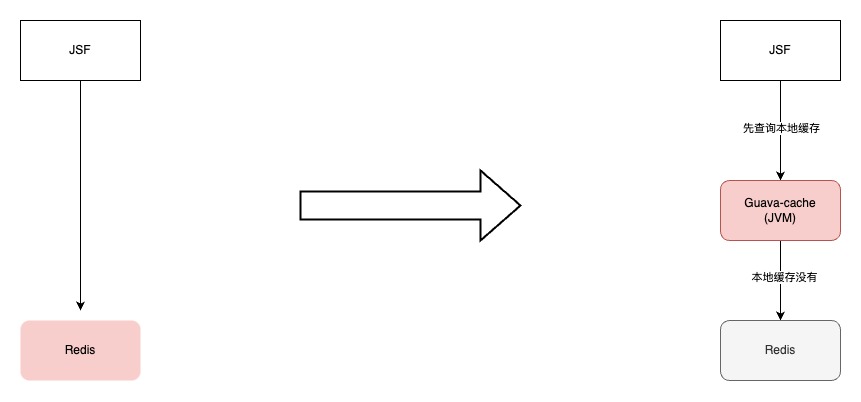
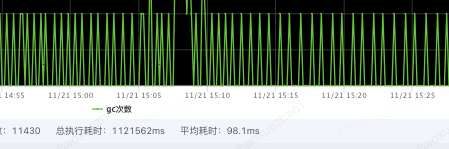
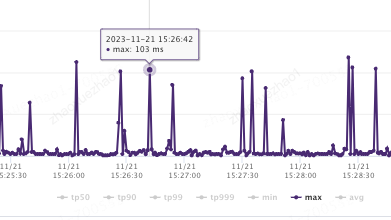

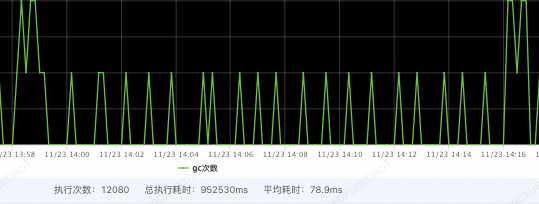
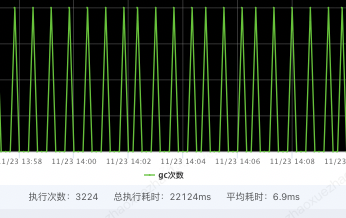
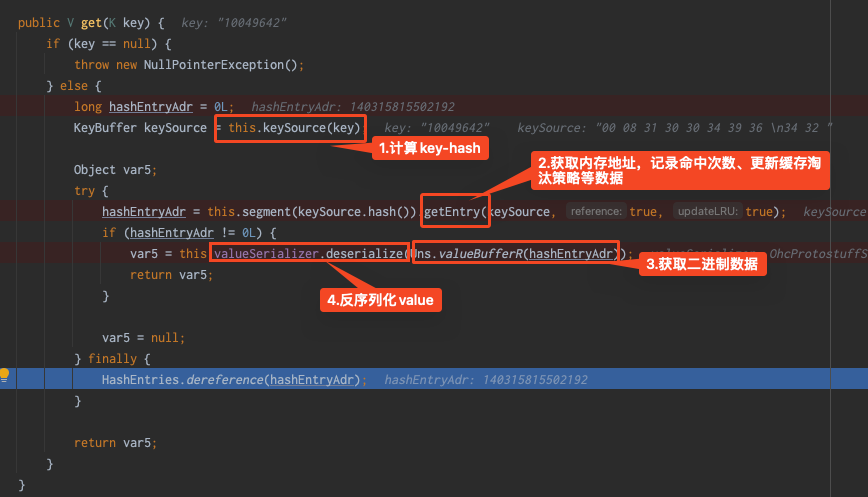
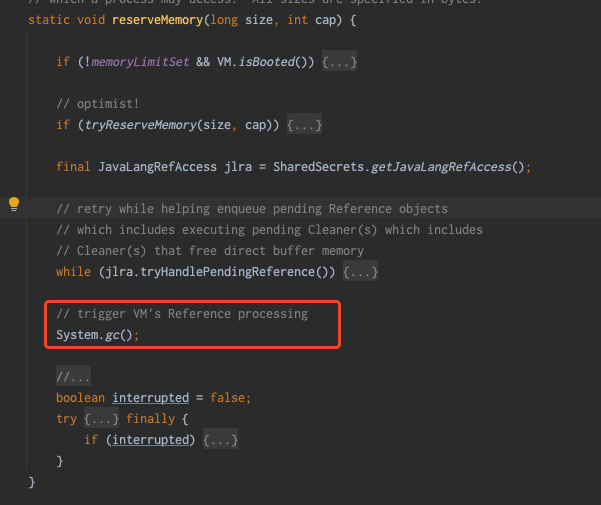
hitCount :缓存命中次数,表示从缓存中成功获取数据的次数。 missCount :缓存未命中次数,表示尝试从缓存中获取数据但未找到的次数。 evictionCount :缓存驱逐次数,表示因为缓存空间不足而从缓存中移除的数据项数量。 expireCount :缓存过期次数,表示因为缓存数据过期而从缓存中移除的数据项数量。 size :缓存当前存储的数据项数量。 capacity :缓存的最大容量,表示缓存可以存储的最大数据项数量。 free :缓存剩余空闲容量,表示缓存中未使用的可用空间。 rehashCount :重新哈希次数,表示进行哈希表重新分配的次数。 put(add/replace/fail) :数据项添加/替换/失败的次数。 removeCount :缓存移除次数,表示从缓存中移除数据项的次数。 segmentSizes(#/min/max/avg) :段大小统计信息,包括段的数量、最小大小、最大大小和平均大小。 totalAllocated :已分配的总内存大小,表示为负数时表示未知。 lruCompactions :LRU 压缩次数,表示进行 LRU 压缩的次数。通过定期采集OHCacheStates信息,来监控本地缓存数据、命中率=[命中次数 / (命中次数 + 未命中次数)]等,并添加相关报警。同时通过缓存状态信息,来判断过期策略、段数、容量等设置是否合理,命中率是否符合预期等。
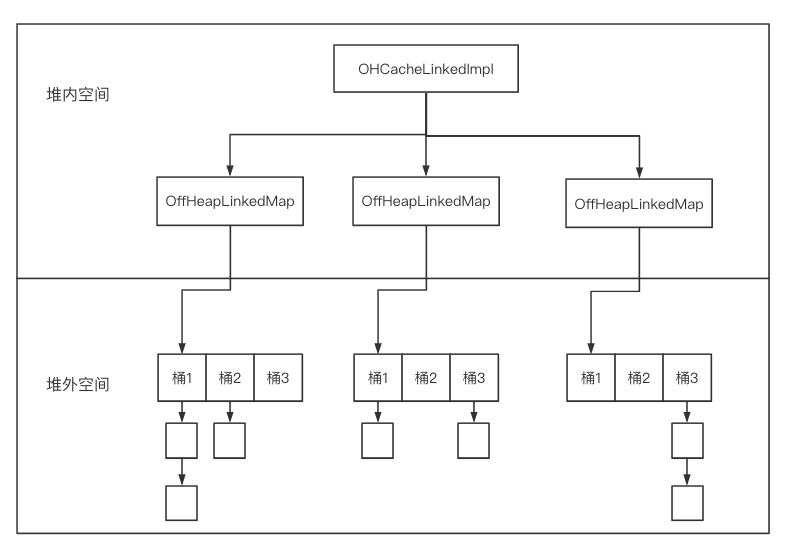






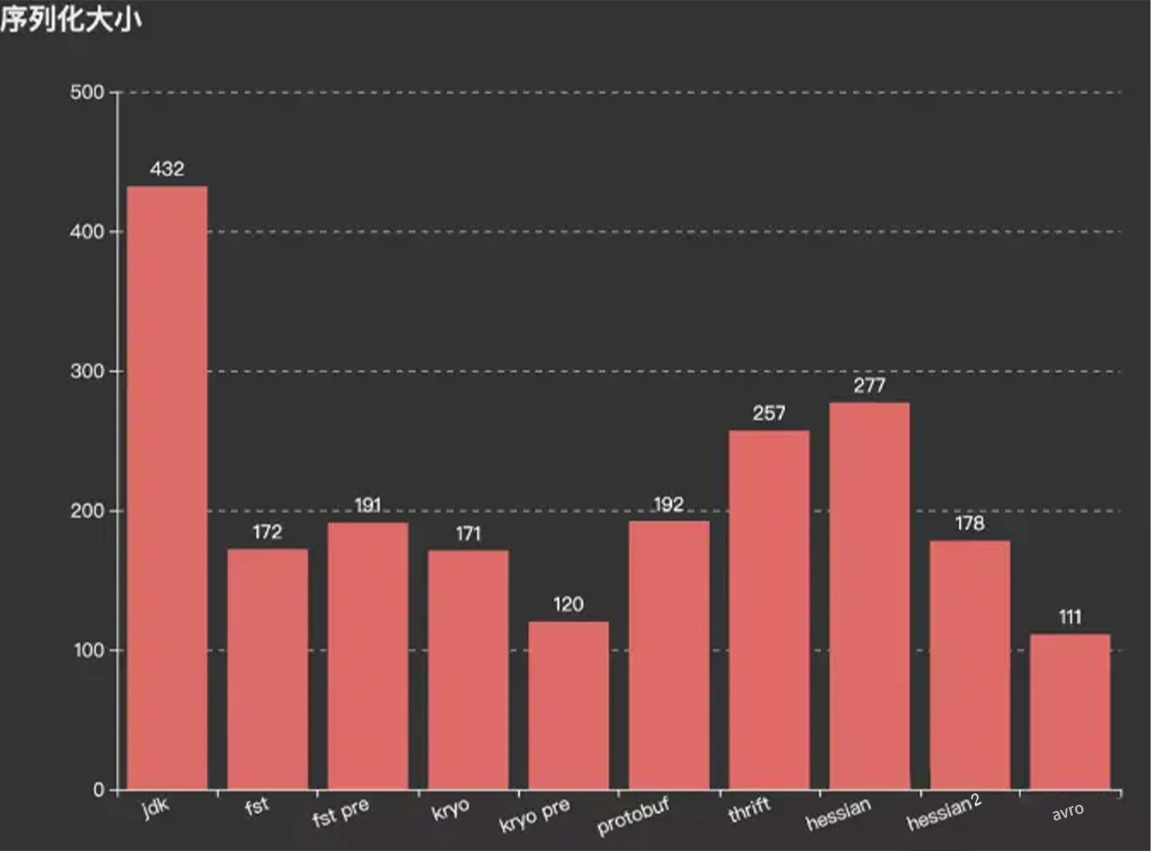
对象:{"paramID":1,"paramName":"John Doe"} 正常JSON字符串:{"paramID":1,"paramName":"John Doe"} 压缩字段名JSON字符串:Hold hold , One more thing....
作者:京东零售 赵雪召
来源:京东云开发者社区 转载请注明来源
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |