
- Consul.AspNetCore 1.6.10.8
- "Consul": {
- "ConsulHost": "http://localhost:8500",
- "ServiceName": "NetCloud.Consul.ServiceA",
- "ServiceIP": "localhost",
- "ServicePort" : 5009
- }
- 添加Consul服务
- public class ConsulOption
- {
- public string ConsulHost { get; set; }
- public string ServiceName { get; set; }
- public string ServiceIP { get; set; }
- public int ServicePort { get; set; }
- }
- public static class ServiceBuilderExtension
- {
- public static IServiceCollection AddConsulService(this IServiceCollection services,IConfiguration configuration)
- {
- var consulSection = configuration.GetSection("Consul");
- services.Configure<ConsulOption>(consulSection);
- var consulOption = consulSection.Get<ConsulOption>();
- services.AddConsul(p =>
- {
- p.Address = new Uri(consulOption.ConsulHost);
- });
- services.AddConsulServiceRegistration(p =>
- {
- p.Address = consulOption.ServiceIP;// 服务绑定IP
- p.ID = Guid.NewGuid().ToString();// 唯一服务Id
- p.Name = consulOption.ServiceName; // 服务名
- p.Port = consulOption.ServicePort; // 服务端口号
- p.Check = new()
- {
- DeregisterCriticalServiceAfter = TimeSpan.FromSeconds(5),
- Interval = TimeSpan.FromSeconds(10), // 健康检查时间间隔
- HTTP = $"http://{p.Address}:{p.Port}/healthCheck/GetHealthCheck", // 健康检查地址
- Timeout = TimeSpan.FromSeconds(5) // 超时时间
- };
- });
- return services;
- }
- }
- Program.cs 代码
- builder.Services.AddConsulService(builder.Configuration);
- 创建健康检查控制器:
- [Route("[controller]")]
- [ApiController]
- public class HealthCheckController : ControllerBase
- {
- [HttpGet]
- public ActionResult GetHealthCheck()
- {
- Console.WriteLine($"进行心跳检测:{DateTime.Now}");
- return Ok("连接正常");
- }
- }
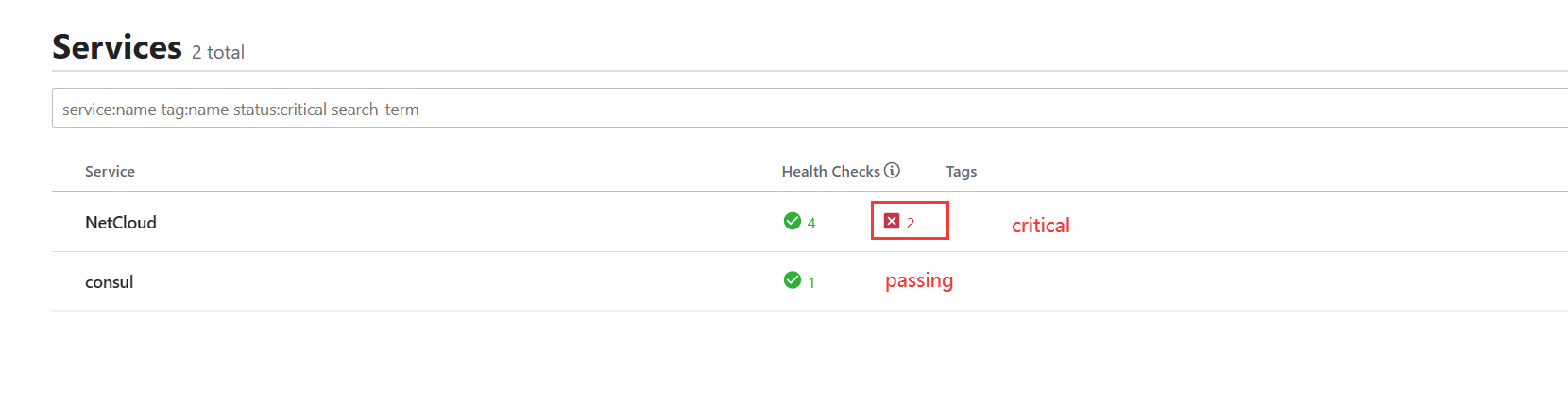
 ORT 列表.
ORT 列表.