Spring Cloud 是一个服务治理平台,是若干个框架的集合,提供了全套的分布式系统解决方案。包含了:服务注册与发现、配置中心、服务网关、智能路由、负载均衡、断路器、监控跟踪、分布式消息队列等等。
Spring Cloud 通过 Spring Boot 风格的封装,屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、容易部署的分布式系统开发工具包。开发者可以快速的启动服务或构建应用、同时能够快速和云平台资源进行对接。微服务是可以独立部署、水平扩展、独立访问(或者有独立的数据库)的服务单元,Spring Cloud 就是这些微服务的大管家,采用了微服务这种架构之后,项目的数量会非常多,Spring Cloud 做为大管家需要管理好这些微服务,自然需要很多小弟来帮忙。
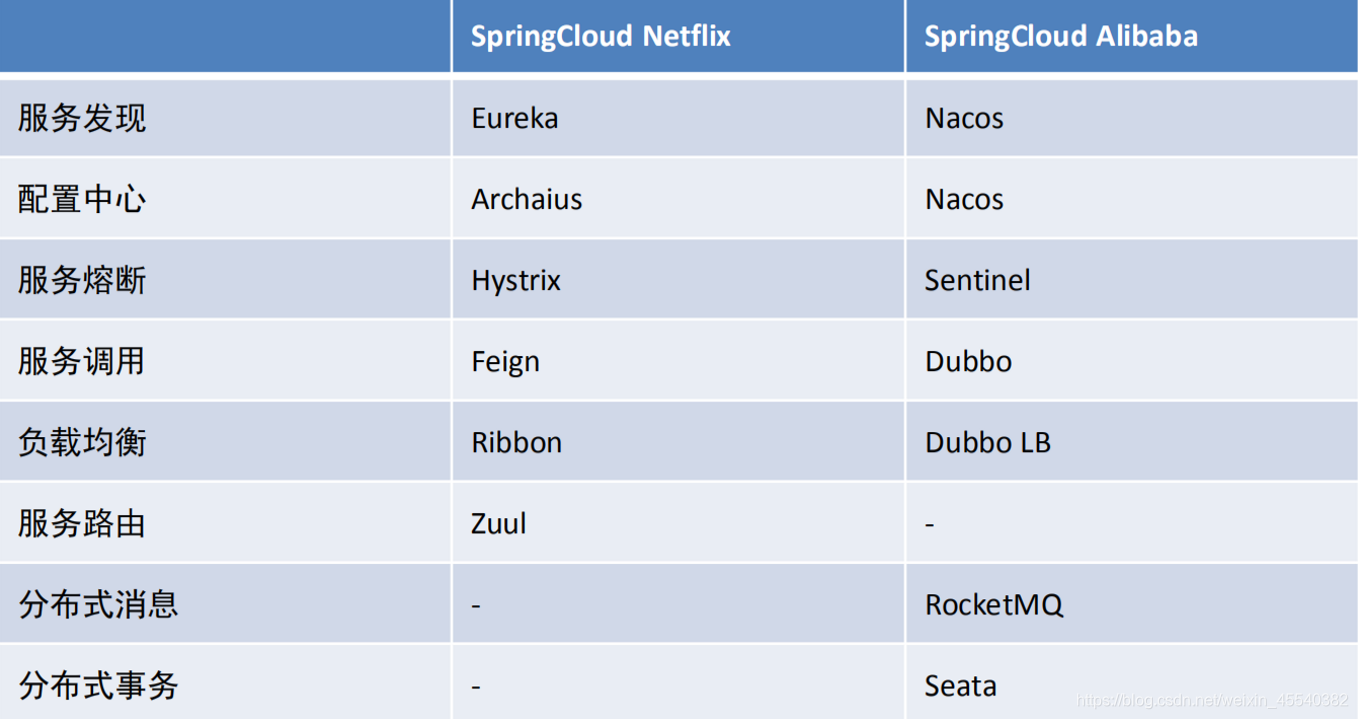
SpringCloud常用组件表
UserOrderFeign o = (UserOrderFeign)Proxy.newProxyInstance(EurekaClientBApplication.class.getClassLoader(), new Class[]{UserOrderFeign.class}, new InvocationHandler() {
Gateway:Spring Cloud API网关组件(非常详细) (biancheng.net)
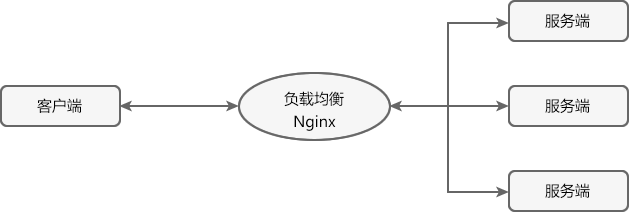
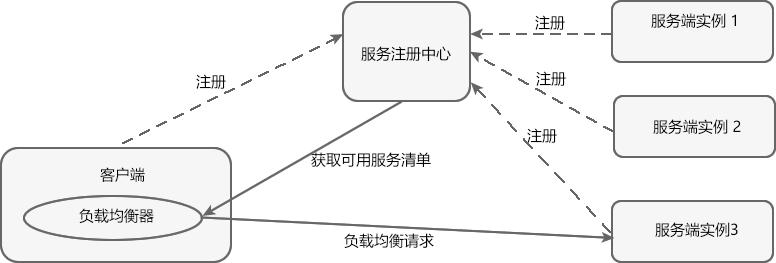
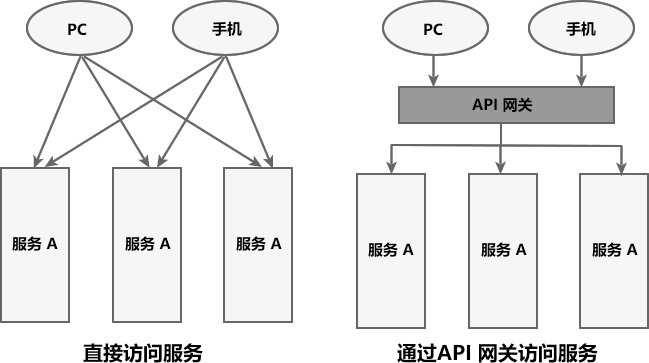
在微服务架构中,一个系统往往由多个微服务组成,而这些服务可能部署在不同机房、不同地区、不同域名下。这种情况下,客户端(例如浏览器、手机、软件工具等)想要直接请求这些服务,就需要知道它们具体的地址信息,例如 IP 地址、端口号等。
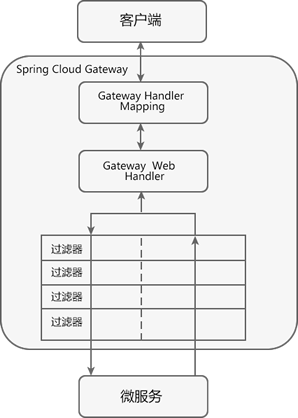
API 网关是一个搭建在客户端和微服务之间的服务,我们可以在 API 网关中处理一些非业务功能的逻辑,例如权限验证、监控、缓存、请求路由等。
API 网关就像整个微服务系统的门面一样,是系统对外的唯一入口。有了它,客户端会先将请求发送到 API 网关,然后由 API 网关根据请求的标识信息将请求转发到微服务实例。
所以可以猜测一下网关的功能应该需要有哪些


 144]How is the RateLimiter designed, and why?[/url],详细的算法实现参见源码。
144]How is the RateLimiter designed, and why?[/url],详细的算法实现参见源码。