提示:因为是面向软件开发者,所以会忽略掉一些电路设计、制造工艺等底层的硬件知识。同时也不会特别深入的介绍每个知识点,只是提供一个概览。CPU 指令集和运行原理
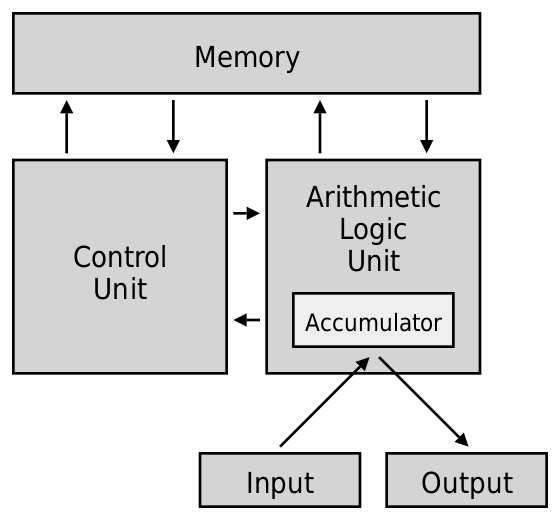
提示:还有一种不同的架构是哈佛架构,它是一种程序指令和数据分开的计算机结构。现在L1缓存中就是使用哈佛架构的思想将指令和数据缓存分开存储。CPU 结构
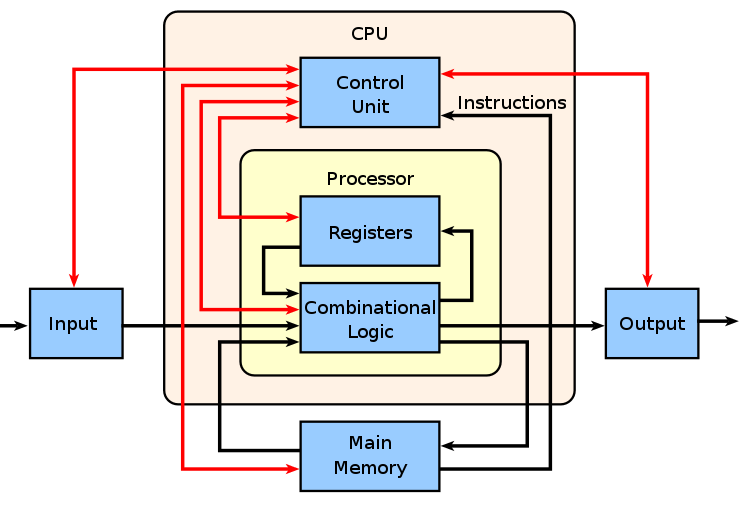
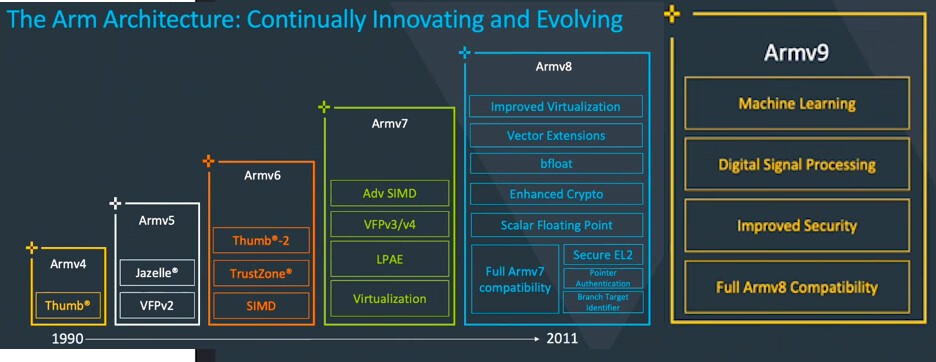
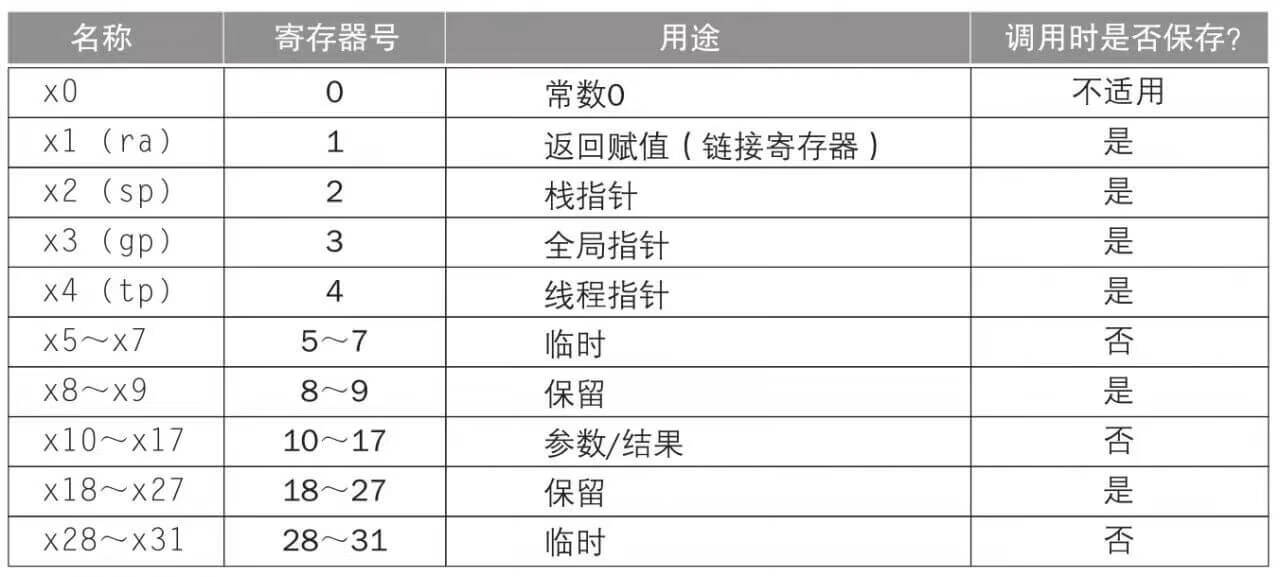
提示:这里只是一种简单的功耗工时,还需要考虑半导体制造工艺和漏电造成的影响。从功耗公式可以看出功耗和晶体管数量、电容、电压、时钟频率成正比,增加晶体管数量和提高频率都会增加处理器的功耗。
登纳德缩放定律:1974年罗伯特·登纳德发现,由于晶体管尺寸变小,在固定的芯片面积上增加晶体管的数量不会增加功耗。
摩尔定律:1965年戈登·摩尔预测,由于晶体管尺寸逐渐变小,同样面积的芯片上晶体管数量每隔一年翻一番,1975 年改为每隔两年翻一番。功耗墙
提示:以功耗公式来计算,1GHz=10亿。Intel 2006 年推出的Core 2 E6700处理器时钟频率2.66 GHz、2个核心、2.9亿个晶体管。所以增加1个核心带来的功耗提高比增加时钟频率1GHz低。CPU能效曲线
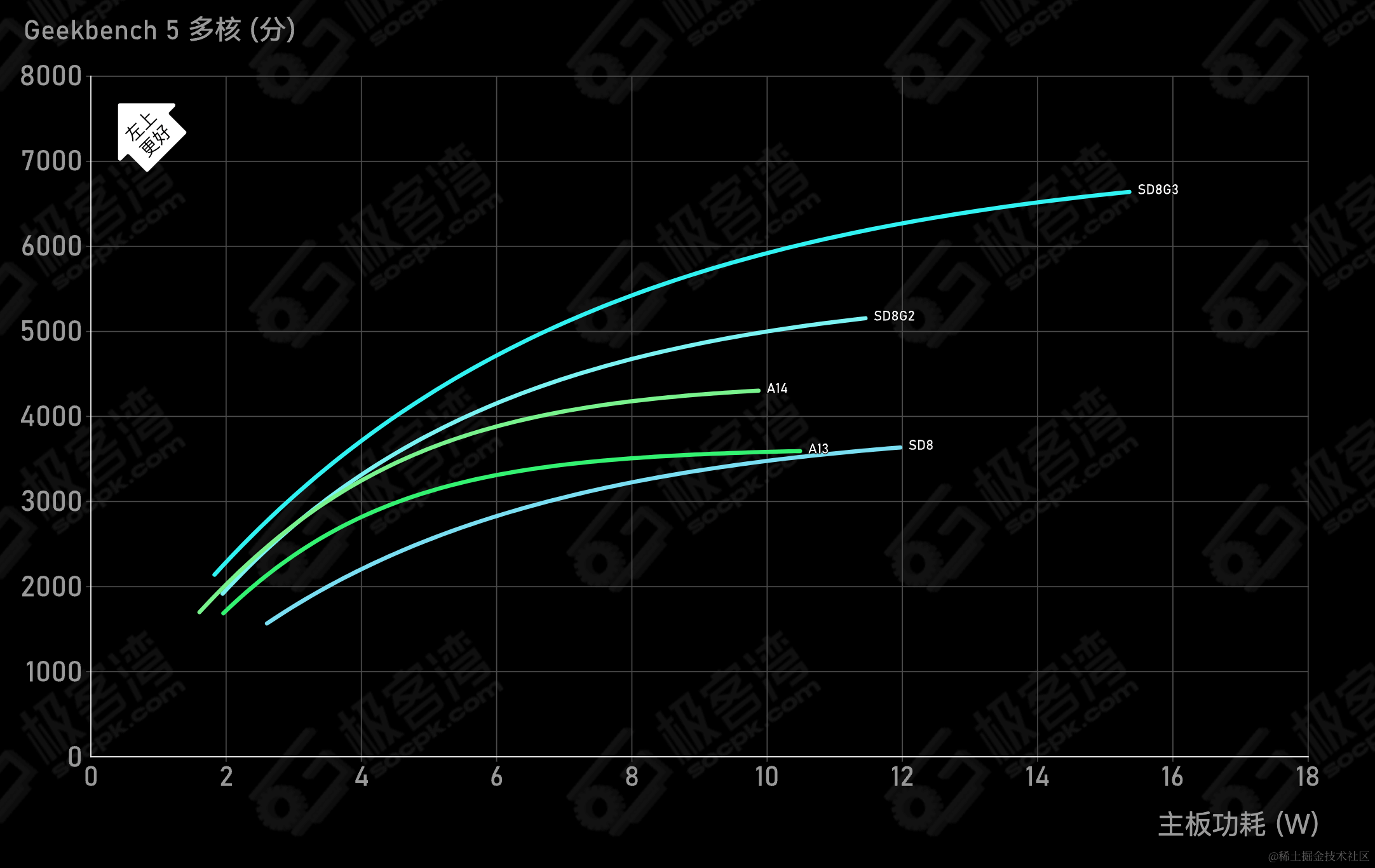
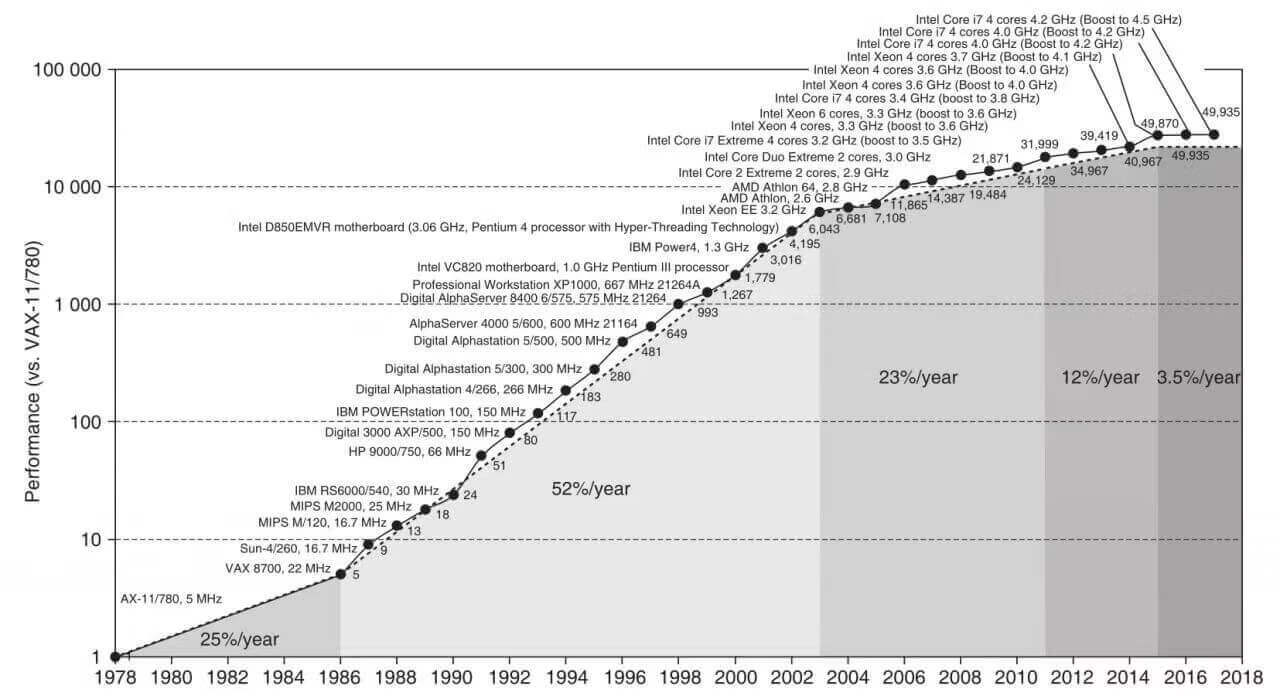
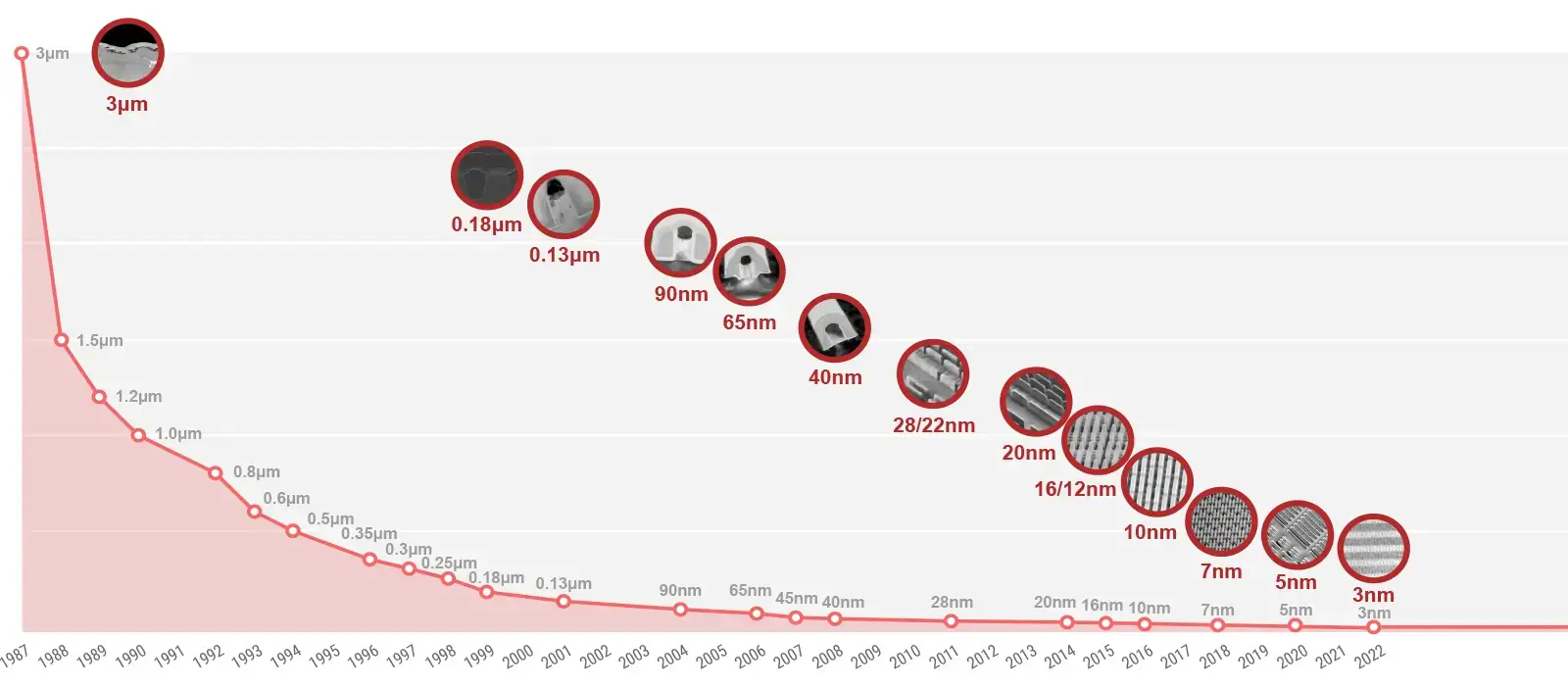
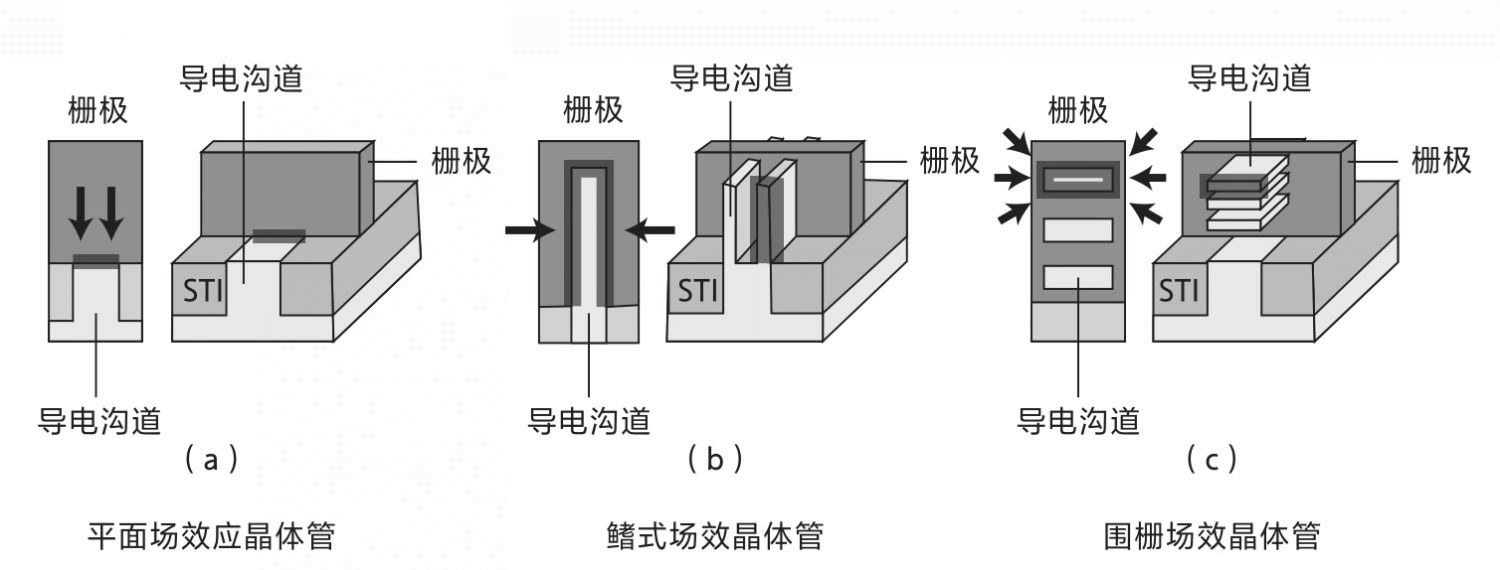
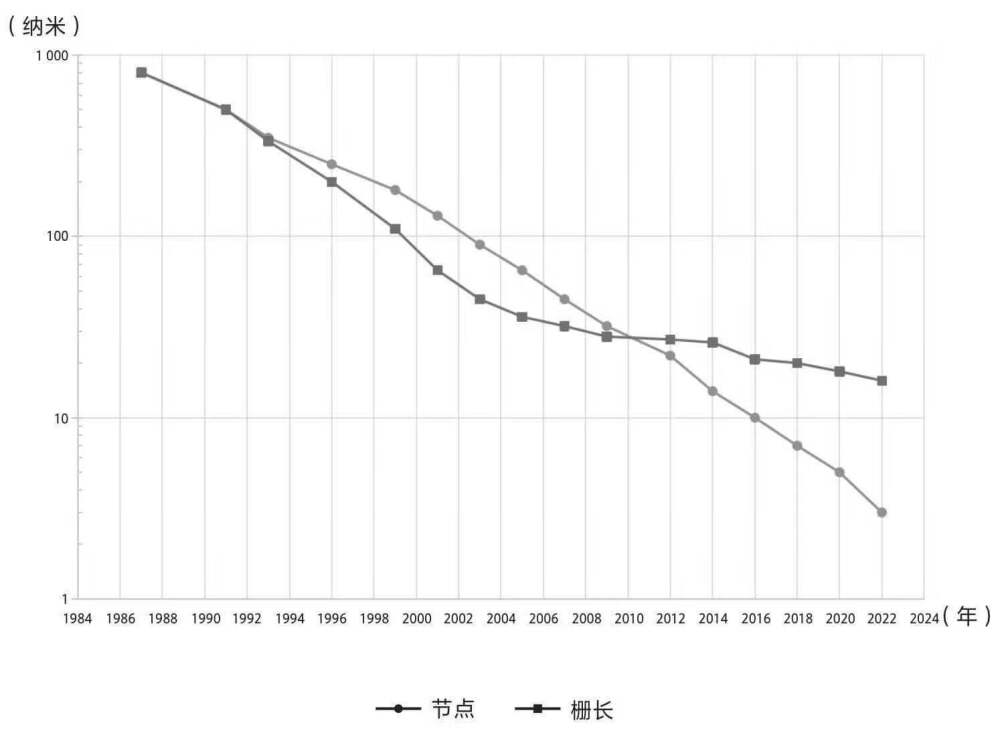

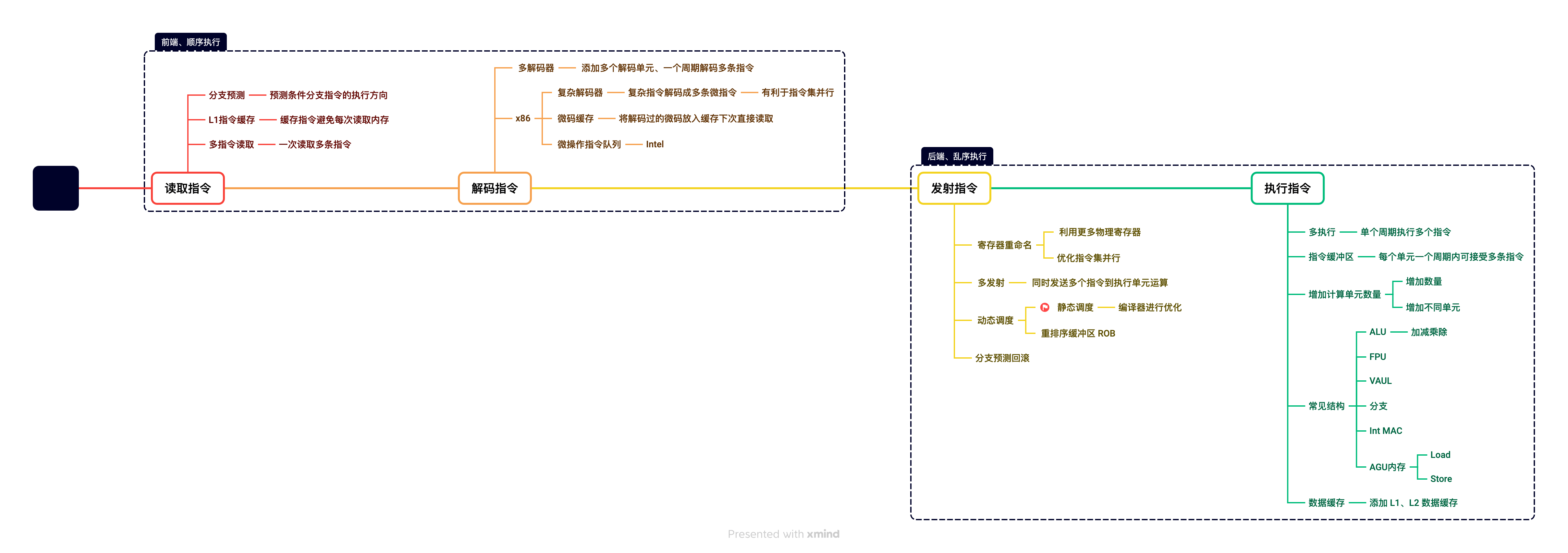
提示:Intel最早在2004年推出了30+级流水线的CPU,但是流水线数量太长会导致微架构设计非常复杂,同时分支预测失败惩罚更高。这些原因导致目前CPU通常使用10级左右的流水线。读取指令
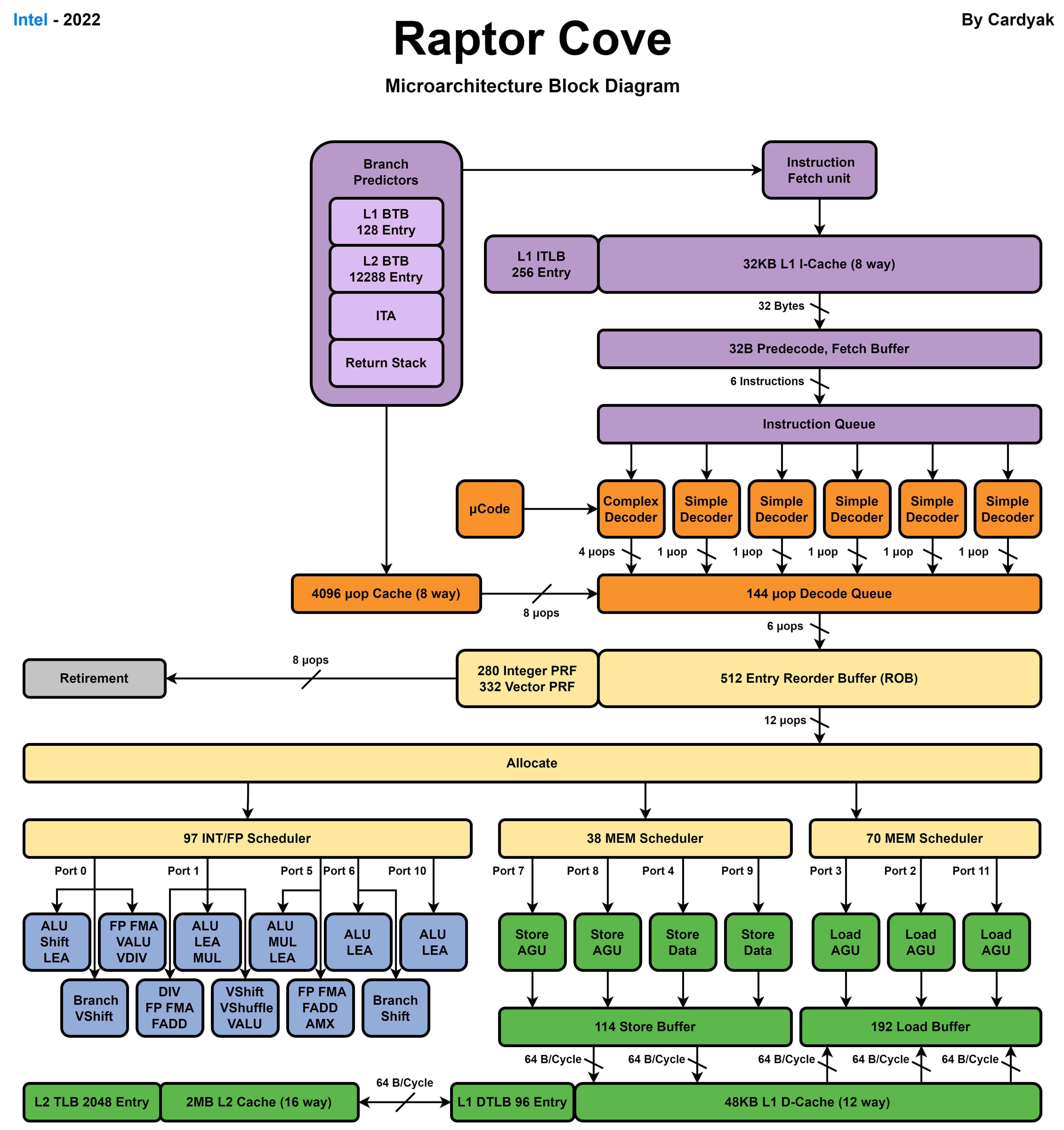
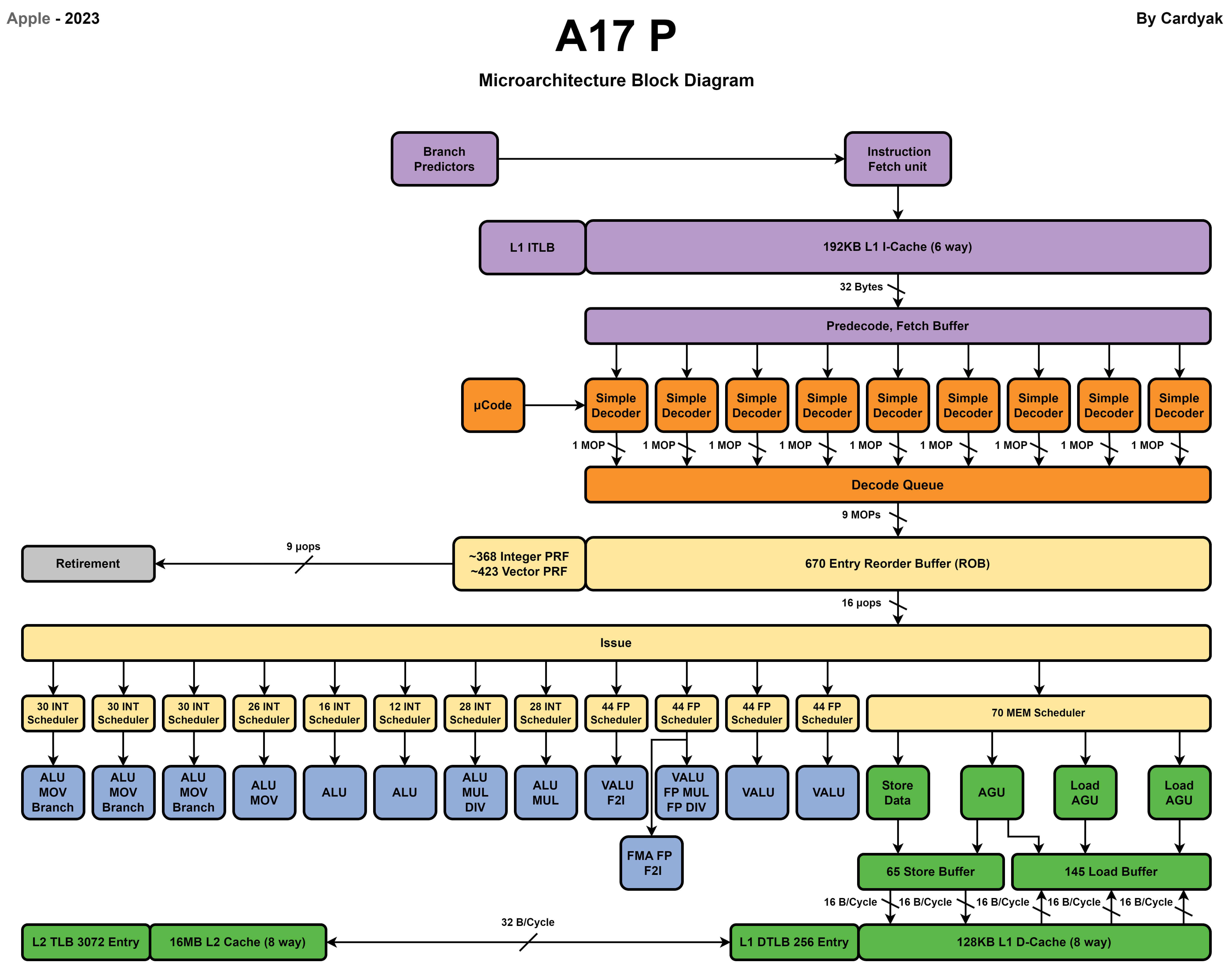
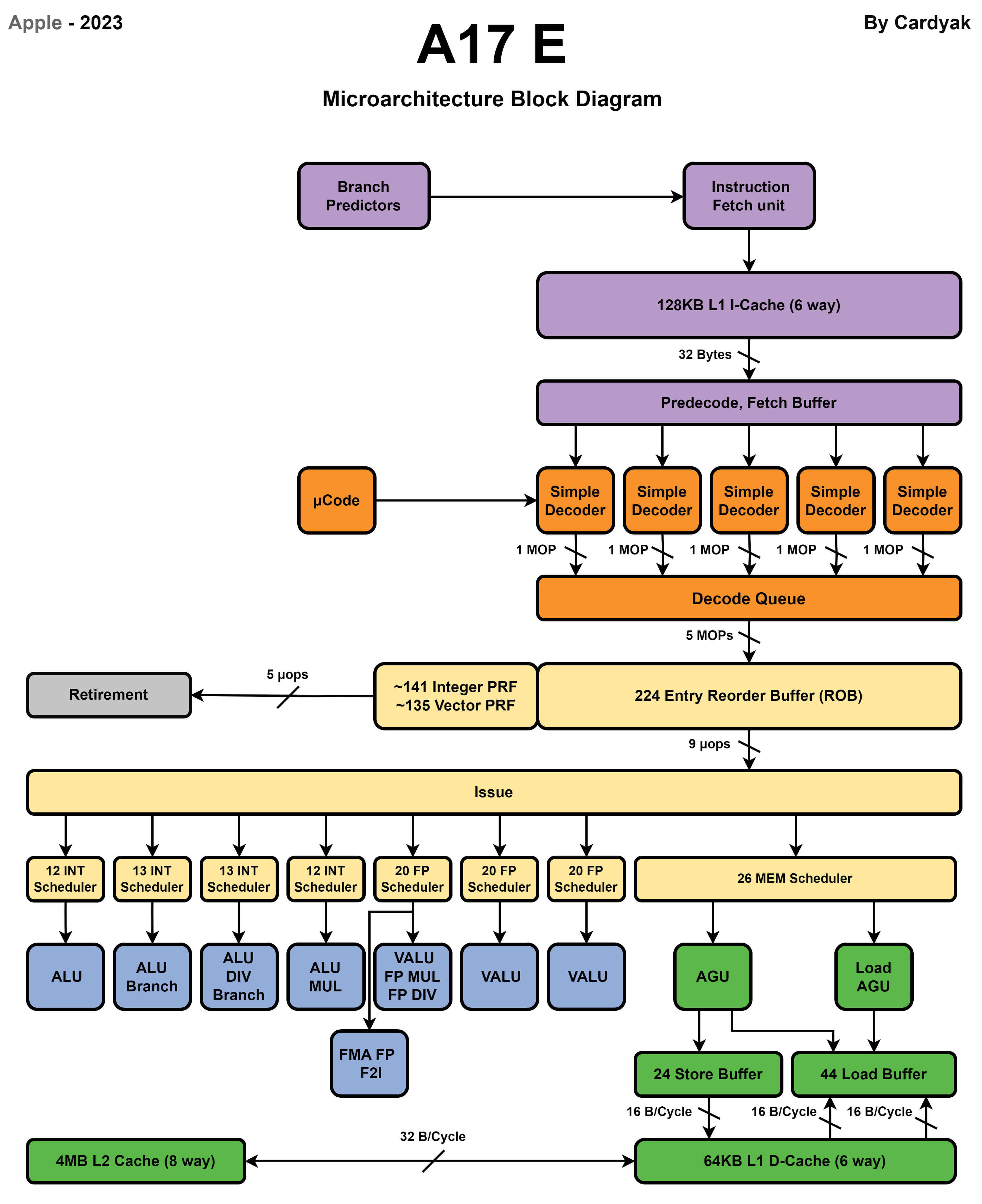
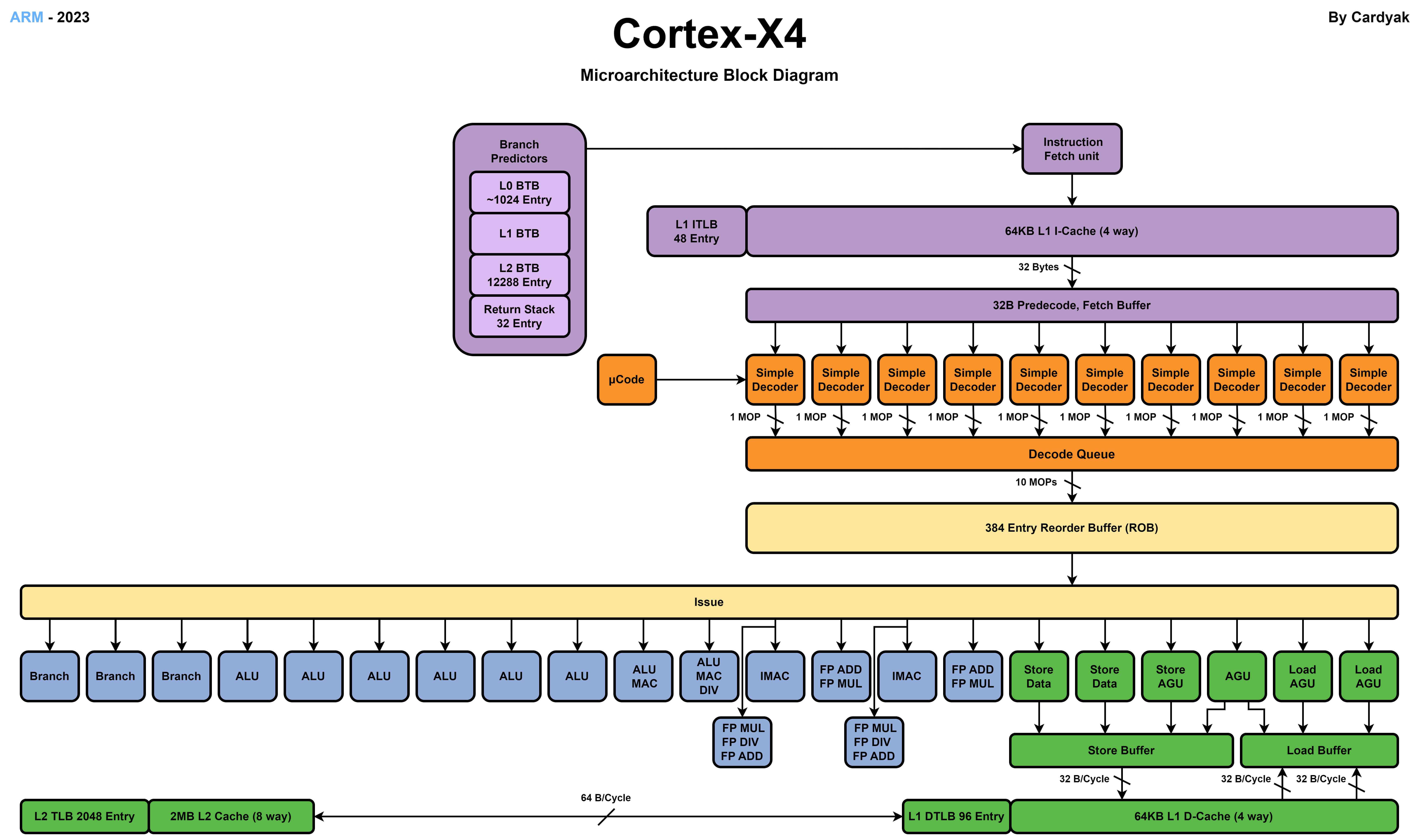
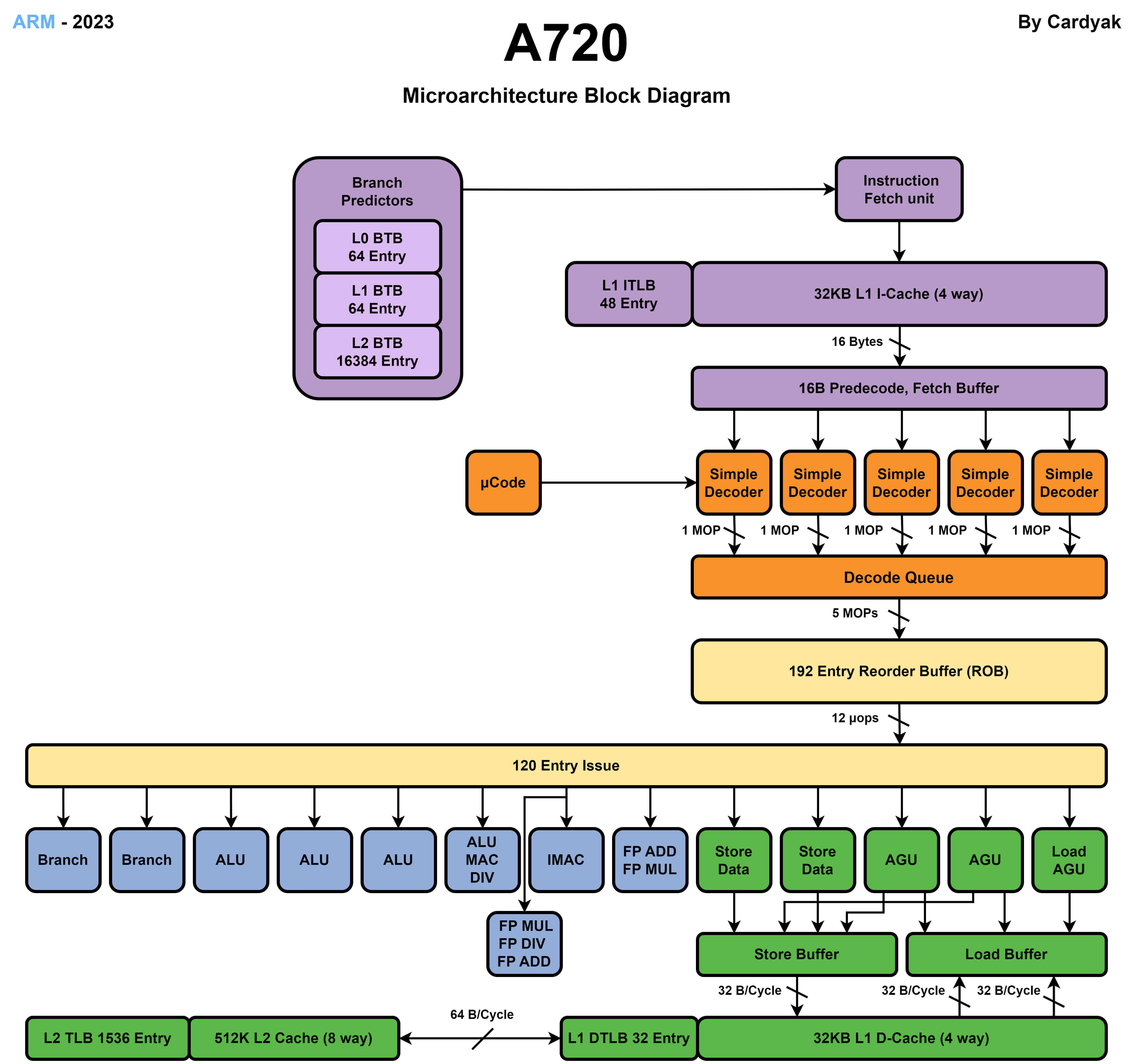
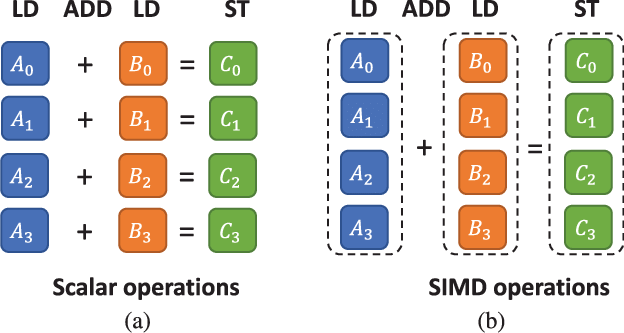
提示:IPC高的核心需要使用更高的时钟频率进行执行,主要是因为IPC高的核心有更复杂流水线设计和更积极的流水线调度避免流水线停顿,所以提高时钟频率可以提升性能。IPC低的核心会遇到更多的流水线停顿,提高频率也会导致很多周期流水线处于停顿等待内存读取或分支计算完成造成浪费。数据级并行:SIMD 和 GPU

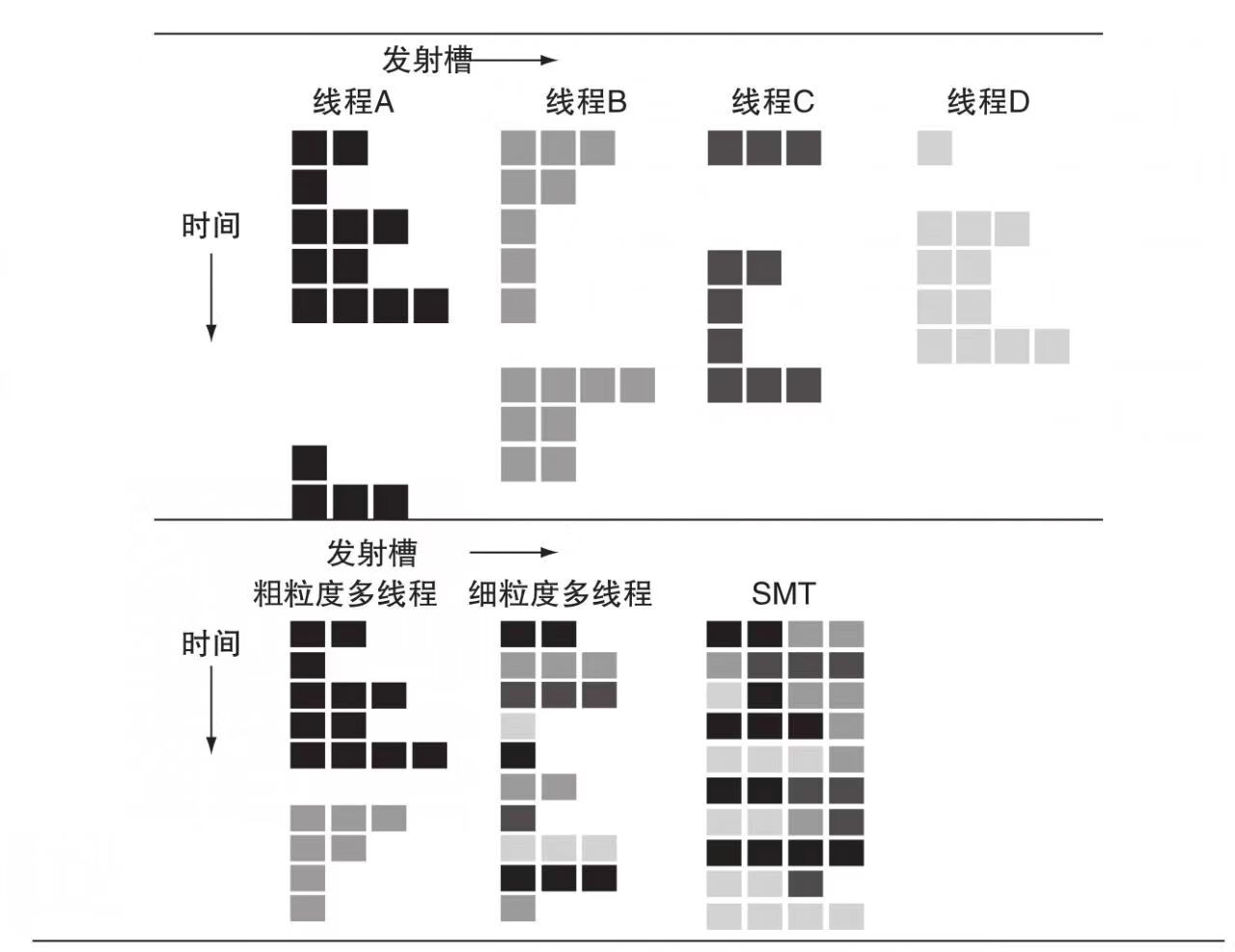
时间局部性- 被引用过一次的内存数据在未来会被多次引用。
空间局部性- 一个内存数据被引用,那么未来它临近的内存地址也会被引用。现代CPU多级缓存设计
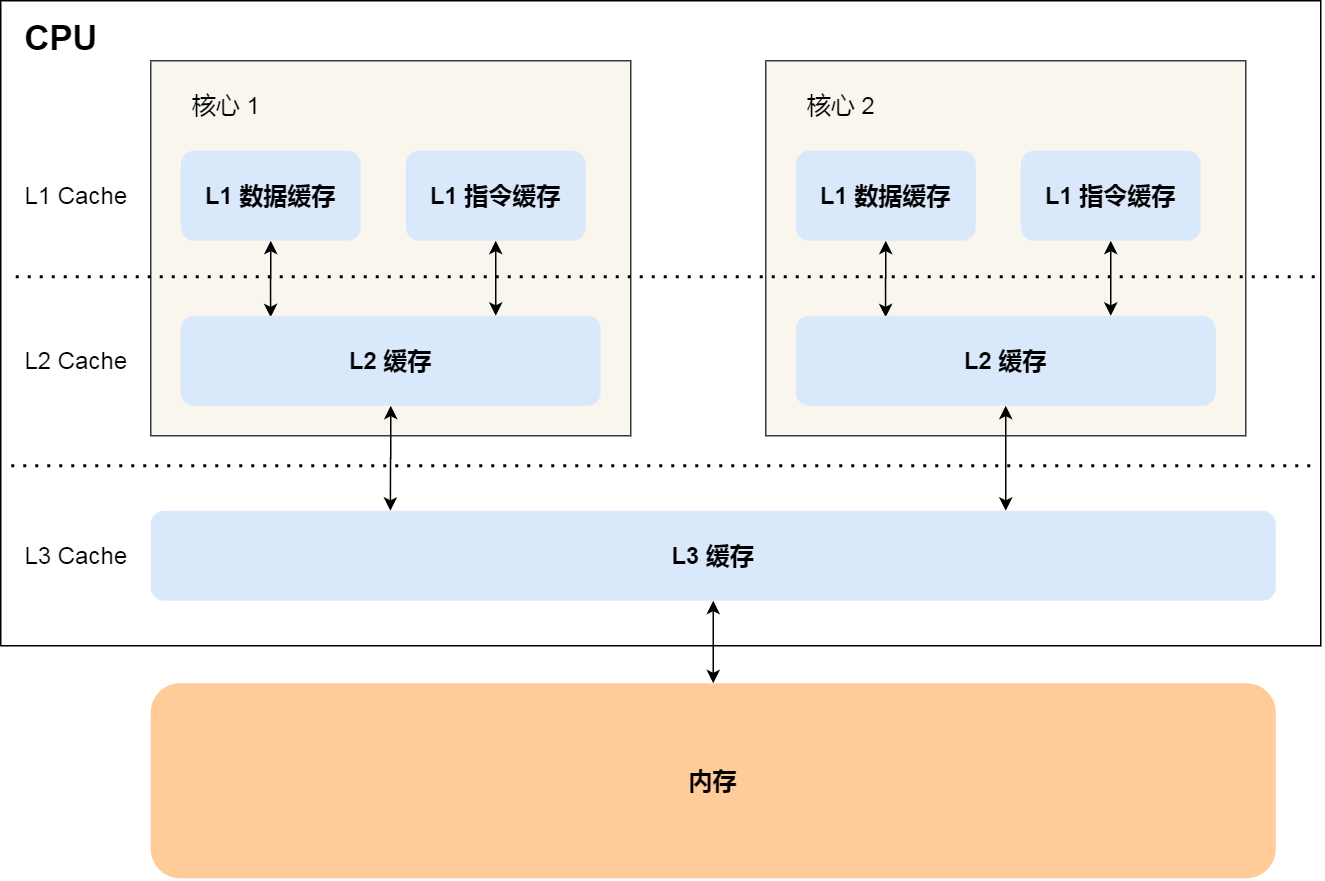
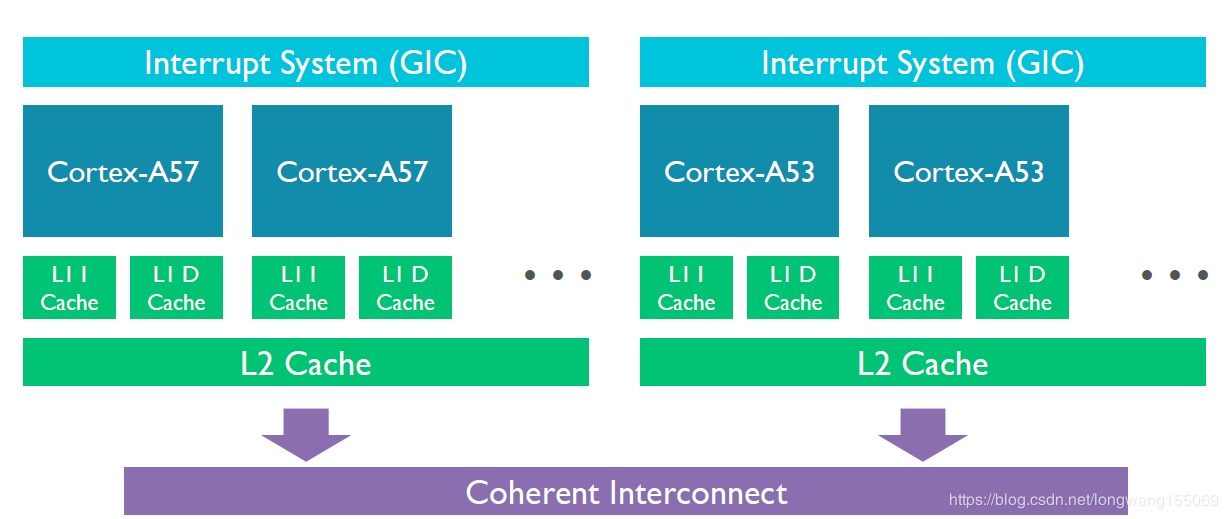
提示:通常L1缓存是单核心独占、L2缓存可能是单核心独占或多核心共享、L3缓存/内存是所有核心共享。通过MESI协议来解决缓存一致性的问题。多级缓存和内存性能

提示:增加缓存容量的成本很高。以A17 Pro芯片为例,总共 190 亿个晶体管,因为包含GPU、NPU等协处理器,CPU使用的晶体管数量不超过 30%。缓存大小L2 20MB + L1 192KB,以一个缓存位需要几个晶体管来计算,缓存大概需要耗费几亿个晶体管。内存技术每一代新标准在增加带宽、容量和能耗比上都有不错的提升,但是读取延迟降低缓慢很多。内存读取延迟导致的内存墙依然是限制处理器性能的主要因素之一。因为内存墙的限制,现在也有一种存算一体的探索方向,将内存和计算单元集成在一起减少数据传输延迟。
提示:从高速缓存和内存上看,更小的程序体积、更小的内存占用是可以增加程序的运行性能的。SOC、DSA 和 Chiplet


作者:京东零售 何骁
来源:京东云开发者社区 转载请注明来源
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |