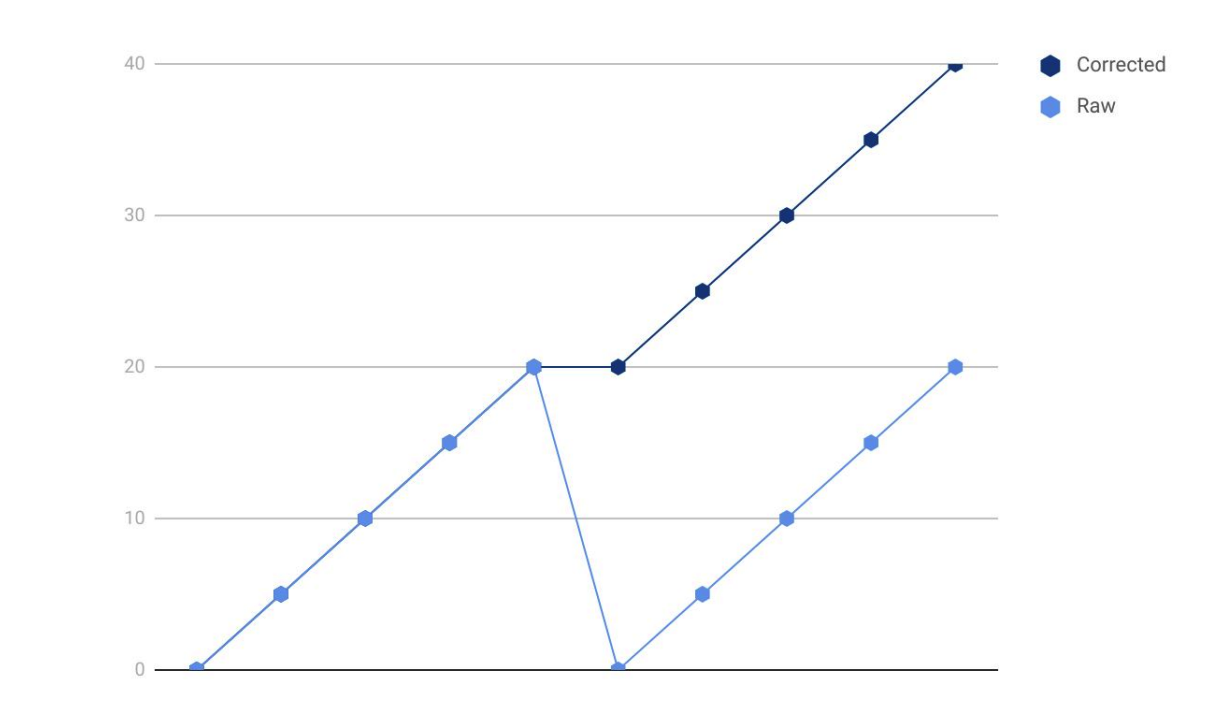
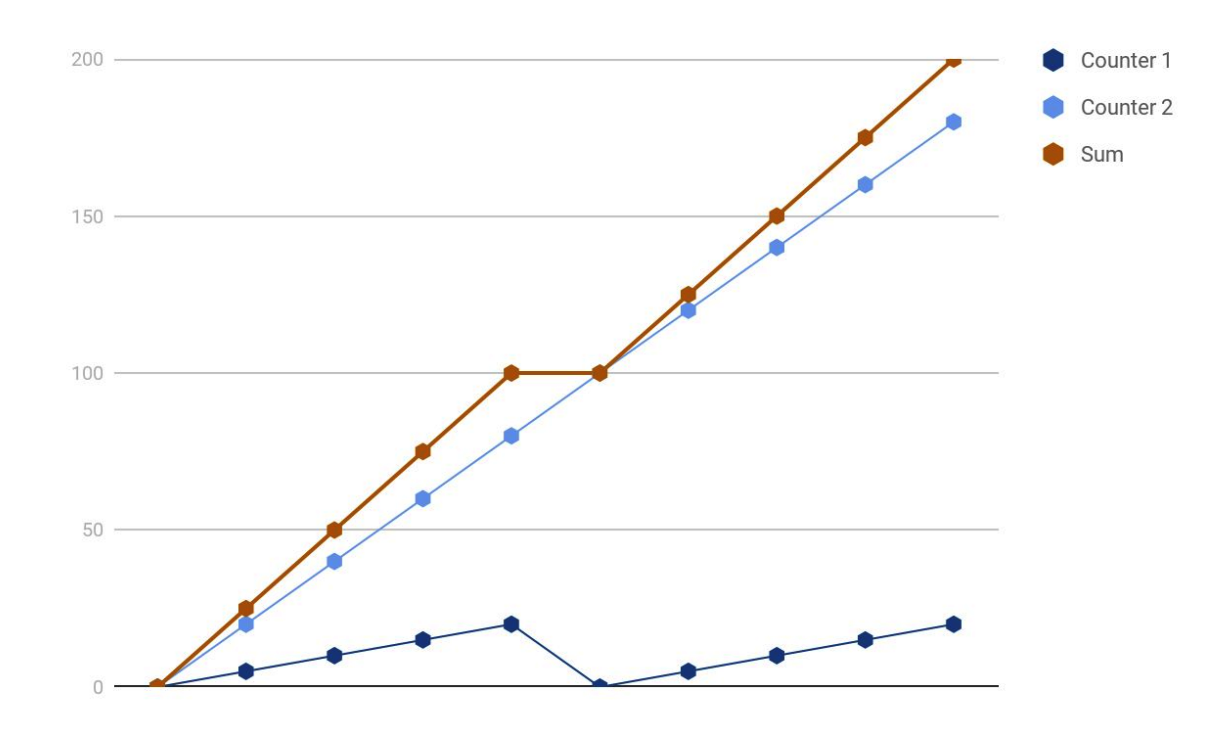
译者:秦晓辉,Open-Falcon、Nightingale、Categraf 等开源项目创始研发人员,极客时间专栏《运维监控系统实战笔记》作者,目前在创业,提供可观测性产品,微信 picobyte,欢迎加好友交流,加好友请备注公司。微信公众号不好贴外部链接,更好的阅读体验可以访问:https://flashcat.cloud/blog/prometheus-best-practices-and-beastly-pitfalls/
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |