着急的小伙伴可直接跳到最后MySQL常见面试题总结

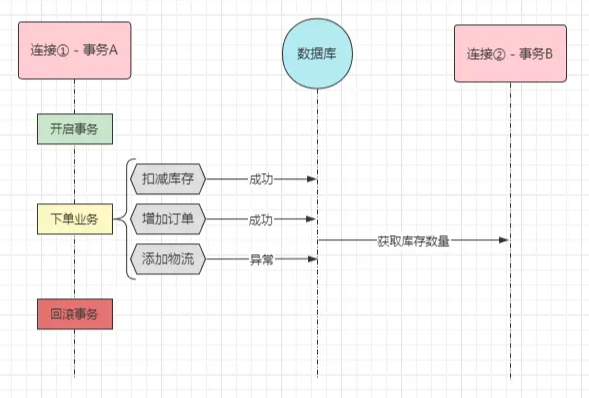
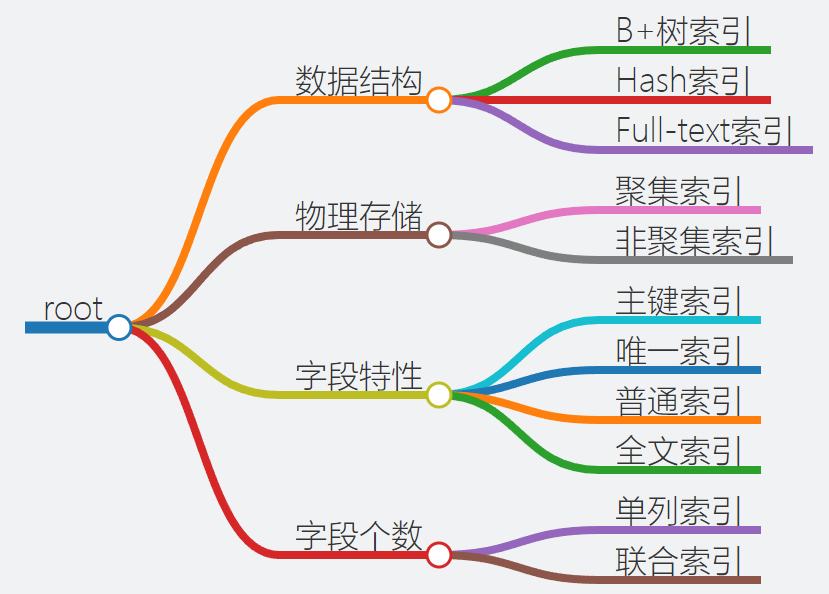
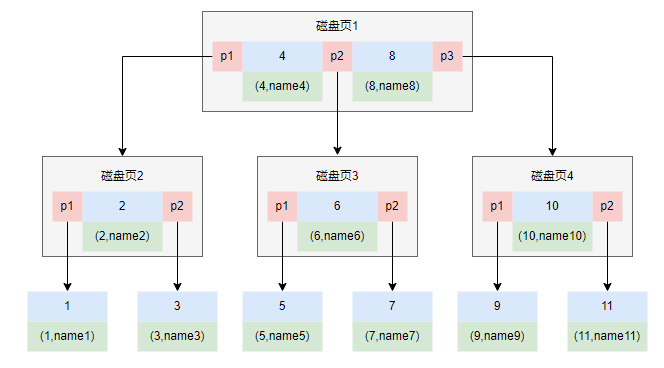
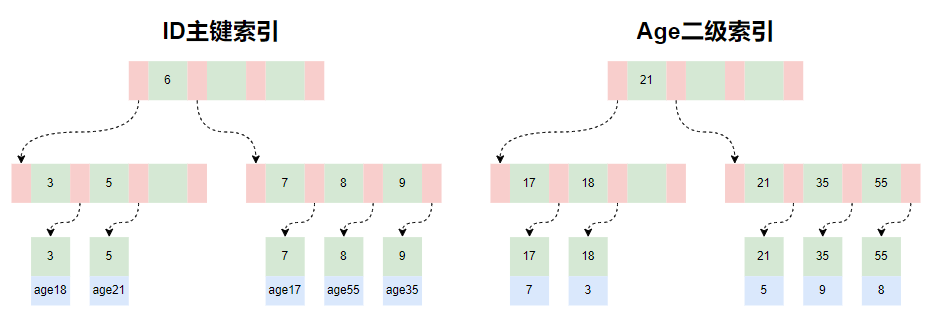
B树与B+树的区别MySQL中的InnoDB引擎会为每个表创建主键索引,如果表没有明确的主键索引,InnoDB会使用自动生成的隐藏的主键(RowId)来创建索引
- B树的所有节点都会存储数据,B+树仅把数据存在叶子节点,而非叶子节点可以存储更多的阶数指针,并且节点不存数据,磁盘IO也会更快
- B+树的范围查找,排序查找,分组查找以及去重查找更简单
- 数据记录之间通过链表连接,可以很方便的在数据查询后进行升序或降序操作

| 欢迎光临 IT评测·应用市场-qidao123.com (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |