栈(Stack)与堆(Heap)所有权规则
在像 Rust 这样的系统编程语言中,值是位于栈上还是堆上在更大程度上影响了语言的行为以及为何必须做出这样的抉择。
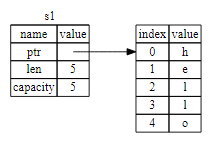
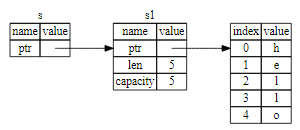
栈以放入值的顺序存储值并以相反顺序取出值,这也被称作 后进先出(last in, first out)。栈中的所有数据都必须占用已知且固定的大小。
在编译时大小未知或大小可能变化的数据,要改为存储在堆上。 堆是缺乏组织的:当向堆放入数据时,你要请求一定大小的空间。内存分配器(memory allocator)在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的 指针(pointer)。
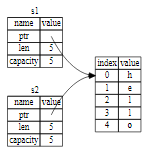
注意:在 C++ 中,这种 item 在生命周期结束时释放资源的模式有时被称作 资源获取即初始化(Resource Acquisition Is Initialization (RAII))。如果你使用过 RAII 模式的话应该对 Rust 的 drop 函数并不陌生。*这个模式对编写 Rust 代码的方式有着深远的影响,不过在更复杂的场景下代码的行为可能是不可预测的,比如当有多个变量使用在堆上分配的内存时。
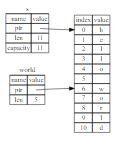
注意:字符串 slice range 的索引必须位于有效的 UTF-8 字符边界内,如果尝试从一个多字节字符的中间位置创建字符串 slice,则程序将会因错误而退出。出于介绍字符串 slice 的目的,本部分假设只使用 ASCII 字符集,后面会讨论 UTF-8 处理问题。重写 first_word 来返回一个 slice,“字符串 slice” 的类型声明写作 &str:
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |