
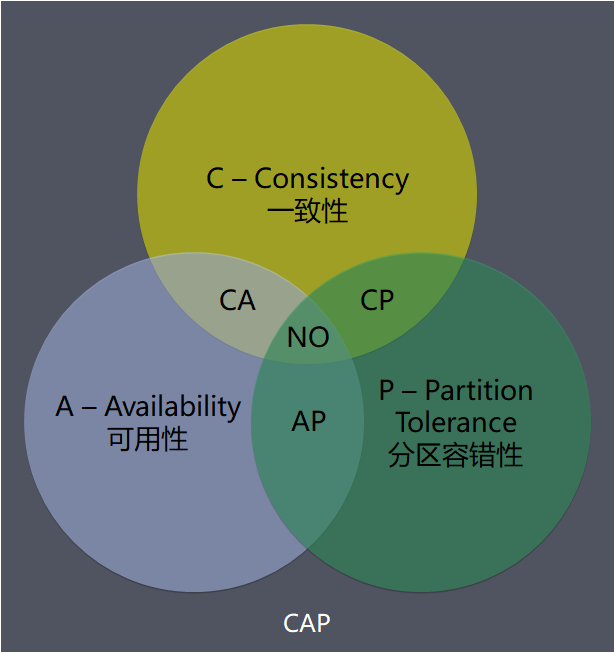
A read is guaranteed to return the most recent write for a given client.这里并不是强调同一时刻拥有相同的数据,对于系统执行事务来说,在事务执行过程中,系统其实处于一个不一致的状态,不同的节点的数据并不完全一致。
对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).这里强调的是合理的响应,不能超时,不能出错。注意并没有说“正确”的结果,例如,应该返回 100 但实际上返回了 90,肯定是不正确的结果,但可以是一个合理的结果。
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
The system will continue to function when network partitions occur.这里网络分区是指:
当出现网络分区后,系统能够继续“履行职责”。
为什么必须要选择P:因此,分布式系统理论上不可能选择 CA (一致性 + 可用性)架构,只能选择 CP(一致性 + 分区容忍性) 或者 AP (可用性 + 分区容忍性)架构,在一致性和可用性做折中选择。
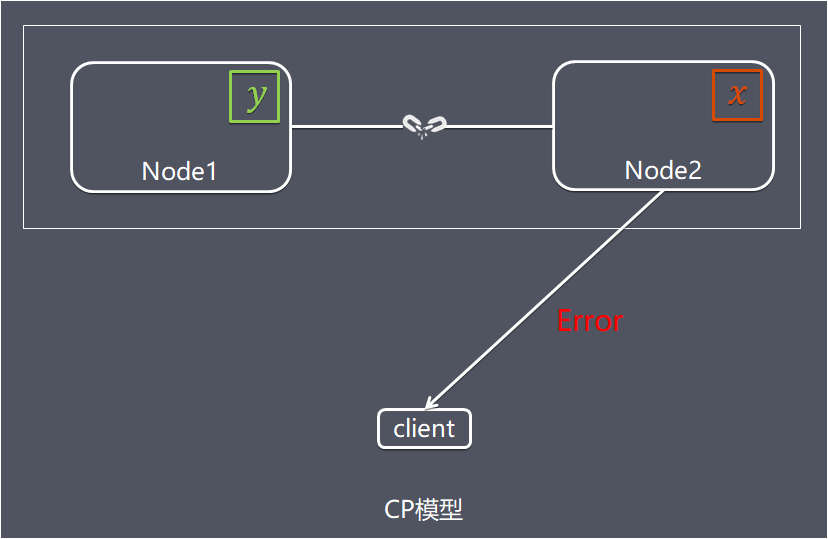
如果我们选择了 CA(一致性 + 可用性) 而放弃了 P(分区容忍性),那么当发生分区现象时,为了保证 C(一致性),系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A(可用性) 冲突了,因为 A(可用性)要求返回 no error 和 no timeout。
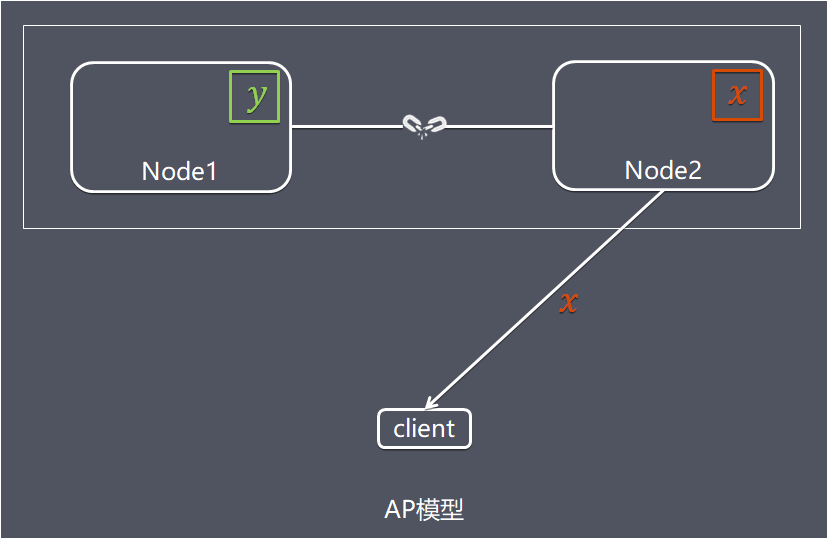
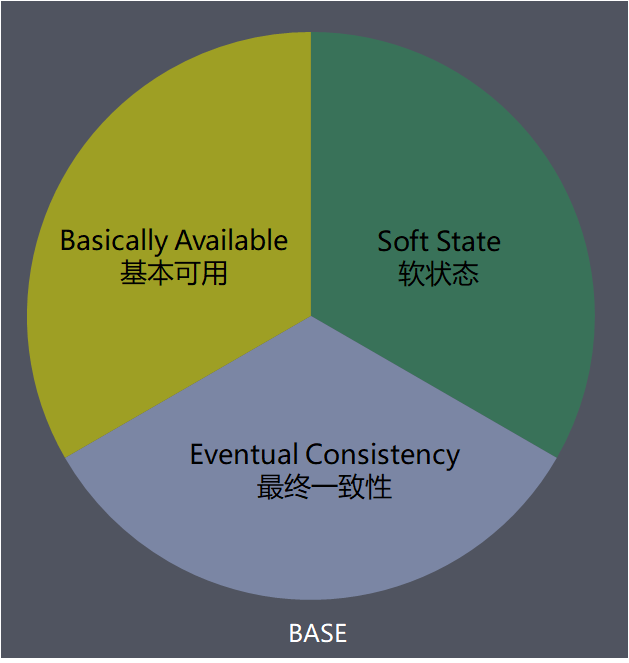
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。这里的关键词是“部分”和“核心”,实际实践上,哪些是核心需要根据具体业务来权衡。例如登录功能相对注册功能更加核心,注册不了最多影响流失一部分用户,如果用户已经注册但无法登录,那就意味用户无法使用系统,造成的影响范围更大。
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。这里的关键词是“一定时间” 和 “最终”,“一定时间”和数据的特性是强关联的,不同业务不同数据能够容忍的不一致时间是不同的。例如支付类业务是要求秒级别内达到一致,因为用户时时关注;用户发的最新微博,可以容忍30分钟内达到一致的状态,因为用户短时间看不到明星发的微博是无感知的。而“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
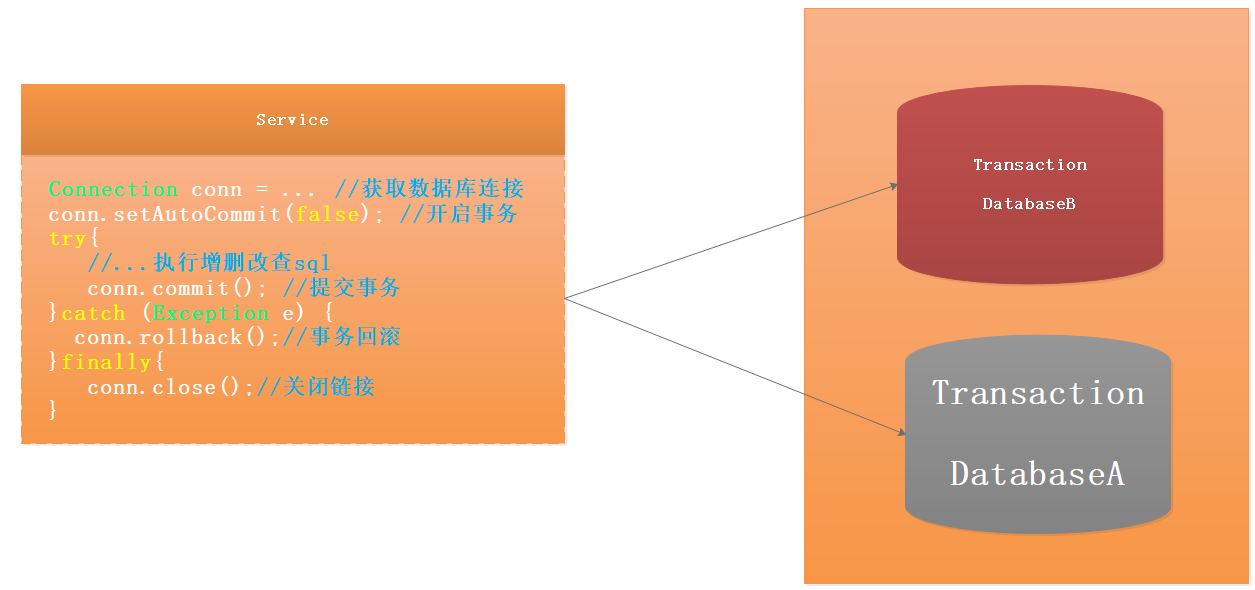
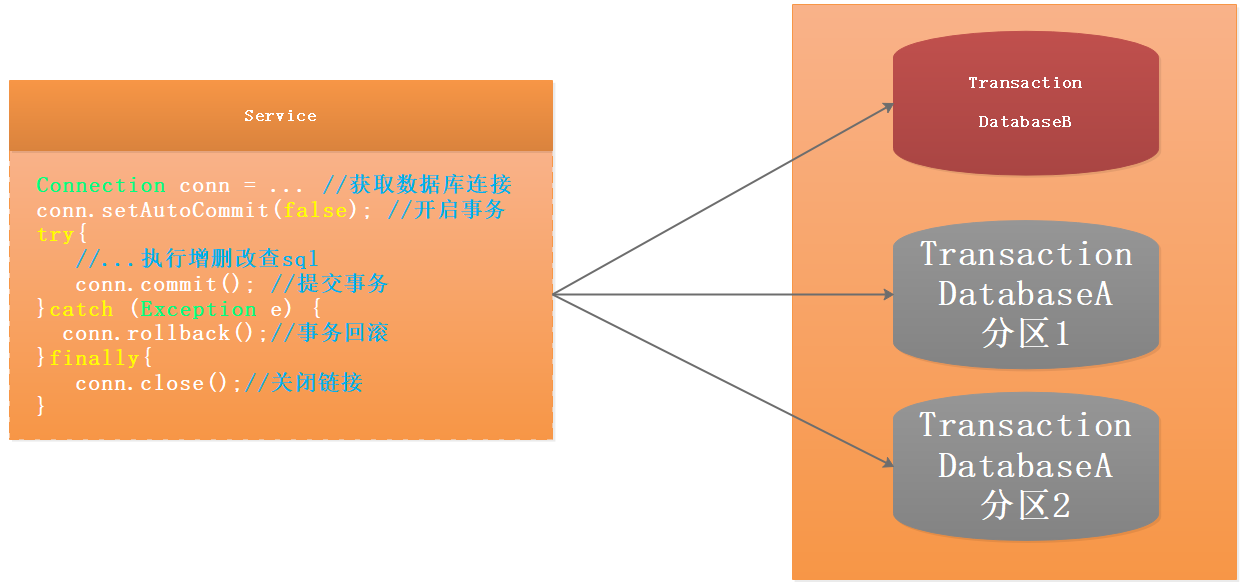
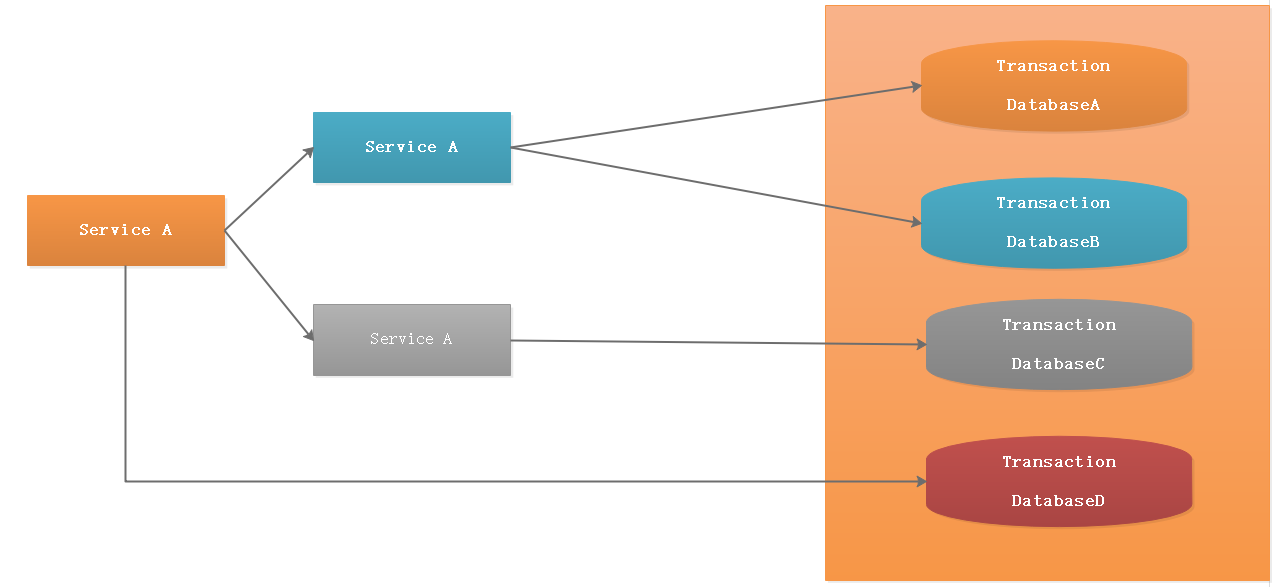
基于BASE理论的设计思想,柔性事务下,在不影响系统整体可用性的情况下(Basically Available 基本可用),允许系统存在数据不一致的中间状态(Soft State 软状态),在经过数据同步的延时之后,最终数据能够达到一致。并不是完全放弃了ACID,而是通过放宽一致性要求,借助本地事务来实现最终分布式事务一致性的同时也保证系统的吞吐。3 常用事务解决方案模型
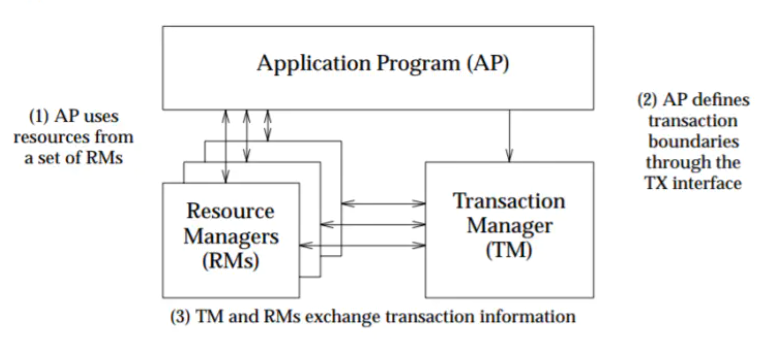
2PC、3PC,都是基于 XA 协议的方案简介
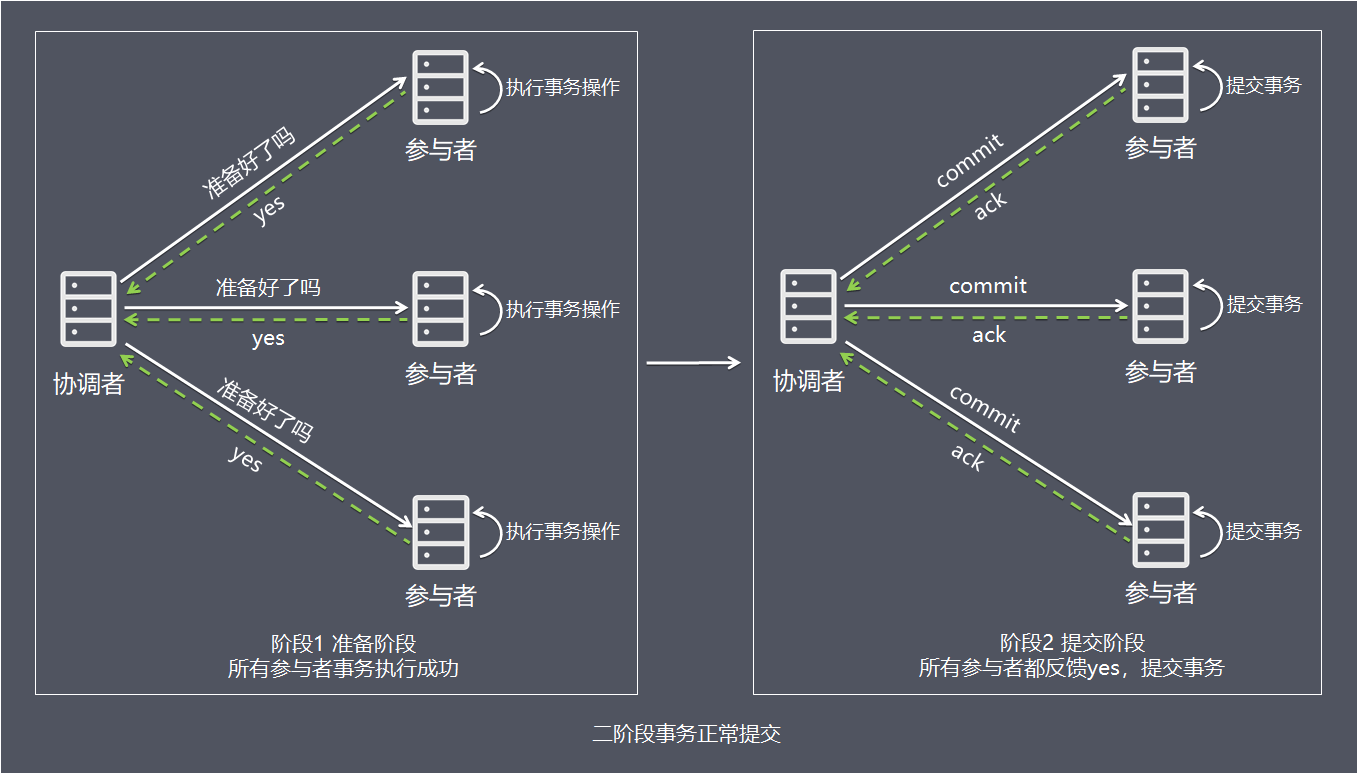
简单一点理解,可以把协调者节点比喻为带头大哥,参与者理解比喻为跟班小弟,带头大哥统一协调跟班小弟的任务执行。阶段1:准备阶段
阶段2:提交阶段
- 1、协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待所有参与者答复。
- 2、各参与者执行事务操作,将undo和redo信息记入事务日志中(但不提交事务)。
- 3、如参与者执行成功,给协调者反馈yes,即可以提交;如执行失败,给协调者反馈no,即不可提交。
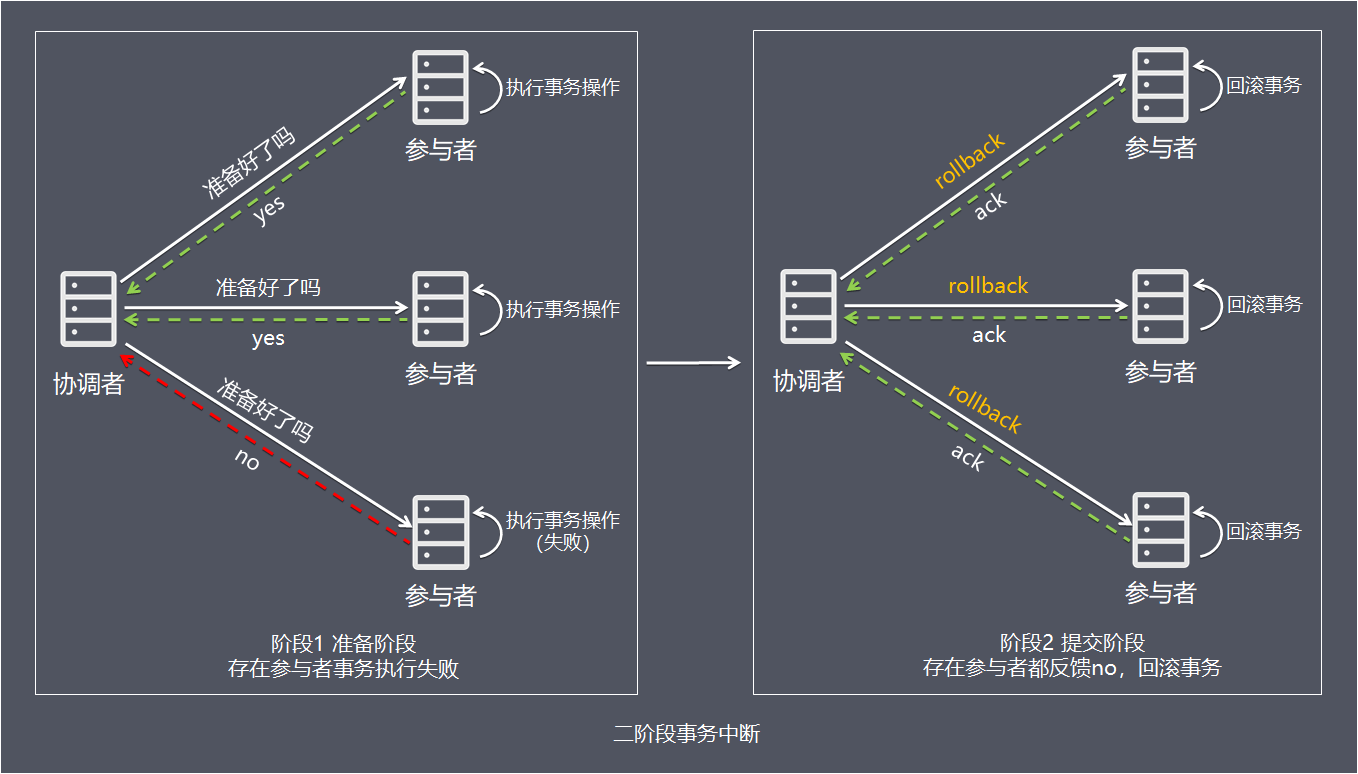
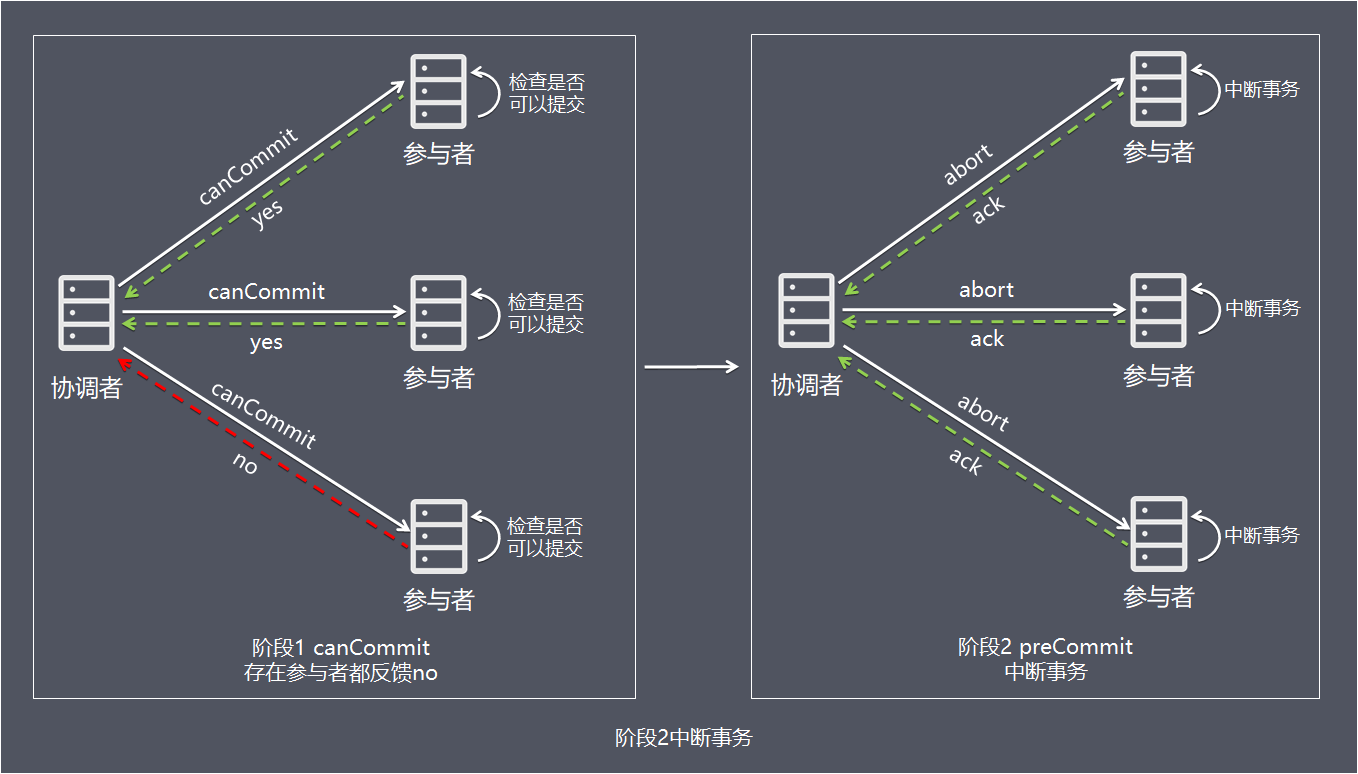
情况2,当任何阶段1一个参与者反馈no,中断事务:
- 1、协调者向所有参与者发出正式提交事务的请求(即commit请求)。
- 2、参与者执行commit请求,并释放整个事务期间占用的资源。
- 3、各参与者向协调者反馈ack(应答)完成的消息。
- 4、协调者收到所有参与者反馈的ack消息后,即完成事务提交。
方案总结
- 1、协调者向所有参与者发出回滚请求(即rollback请求)。
- 2、参与者使用阶段1中的undo信息执行回滚操作,并释放整个事务期间占用的资源。
- 3、各参与者向协调者反馈ack完成的消息。
- 4、协调者收到所有参与者反馈的ack消息后,即完成事务中断。
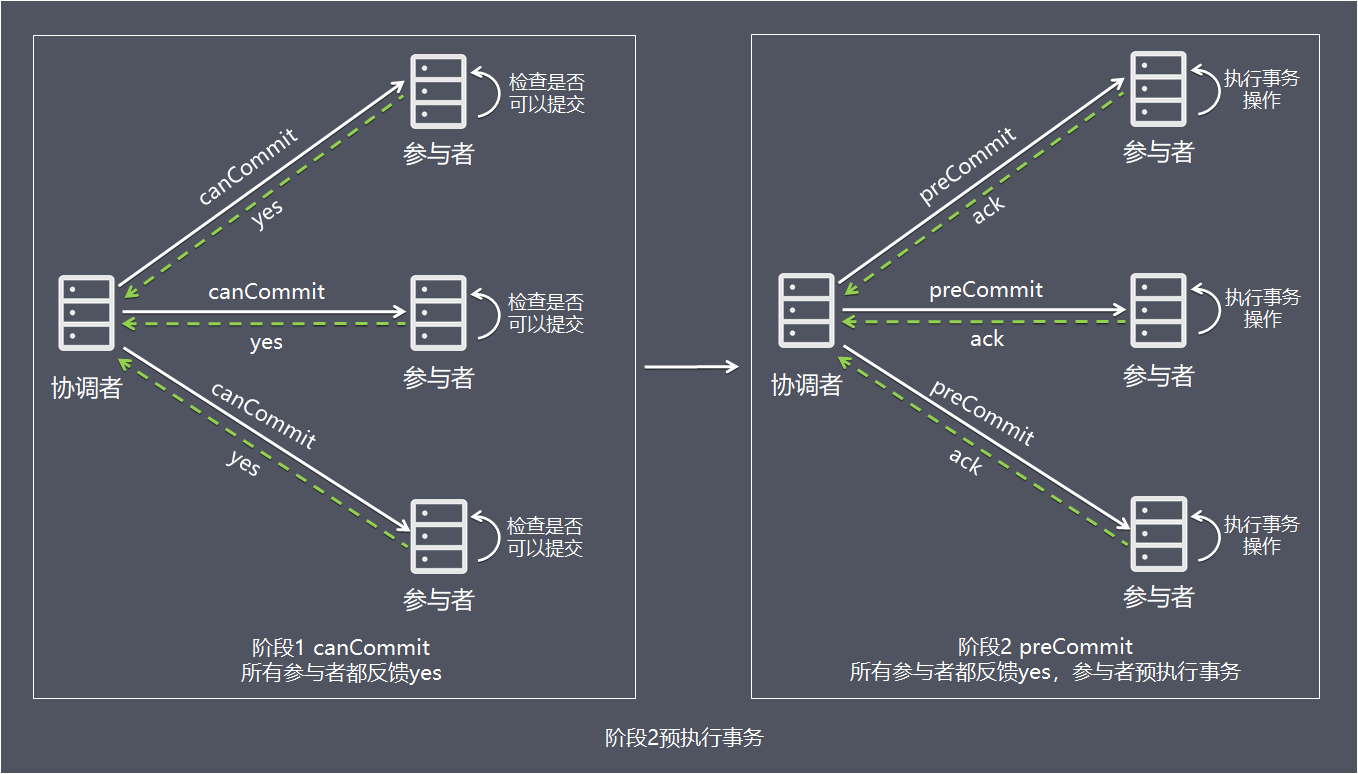
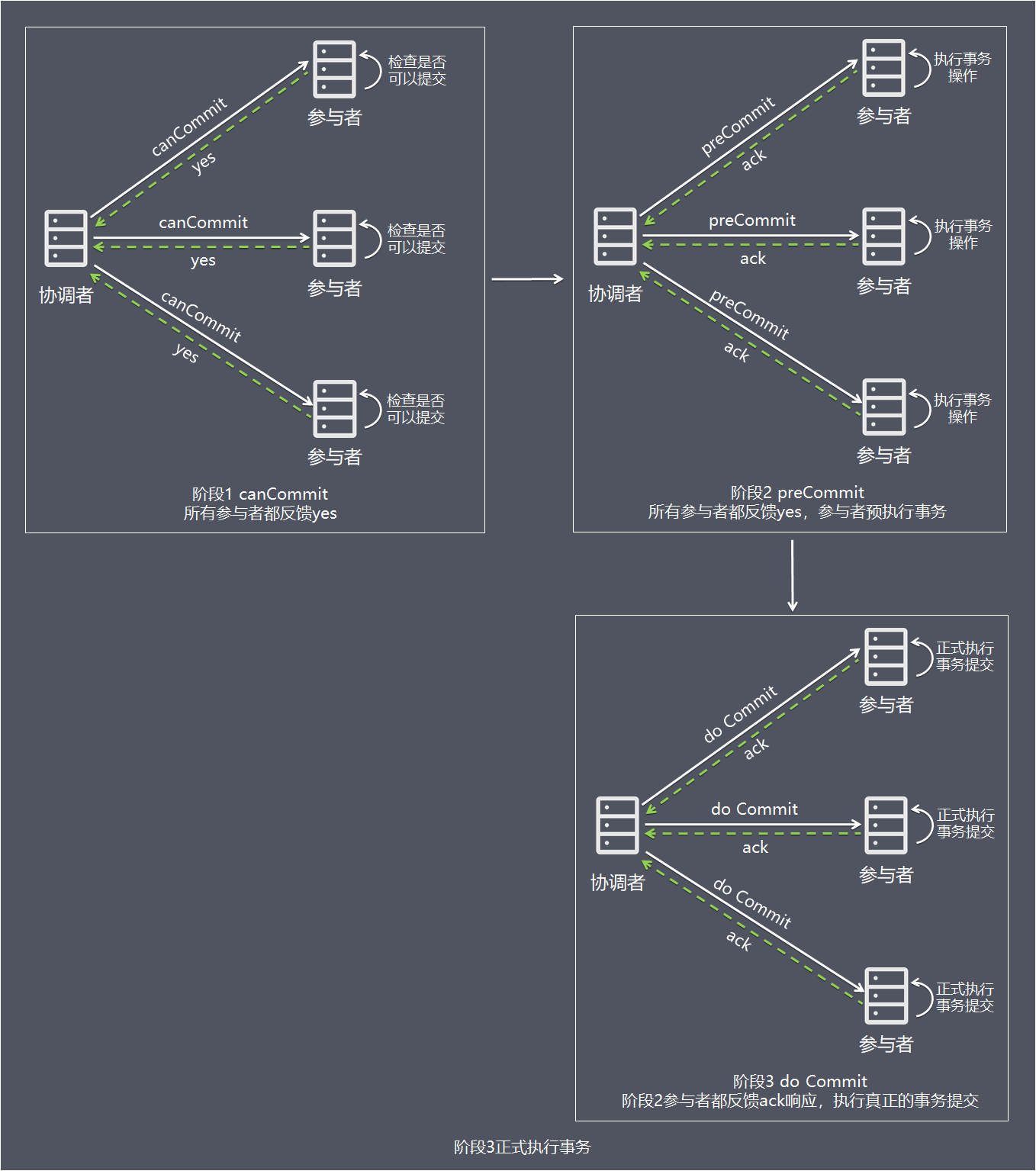
阶段2:preCommit
- 1、协调者向所有参与者发出包含事务内容的canCommit请求,询问是否可以提交事务,并等待所有参与者答复。
- 2、参与者收到canCommit请求后,如果认为可以执行事务操作,则反馈yes并进入预备状态,否则反馈no。
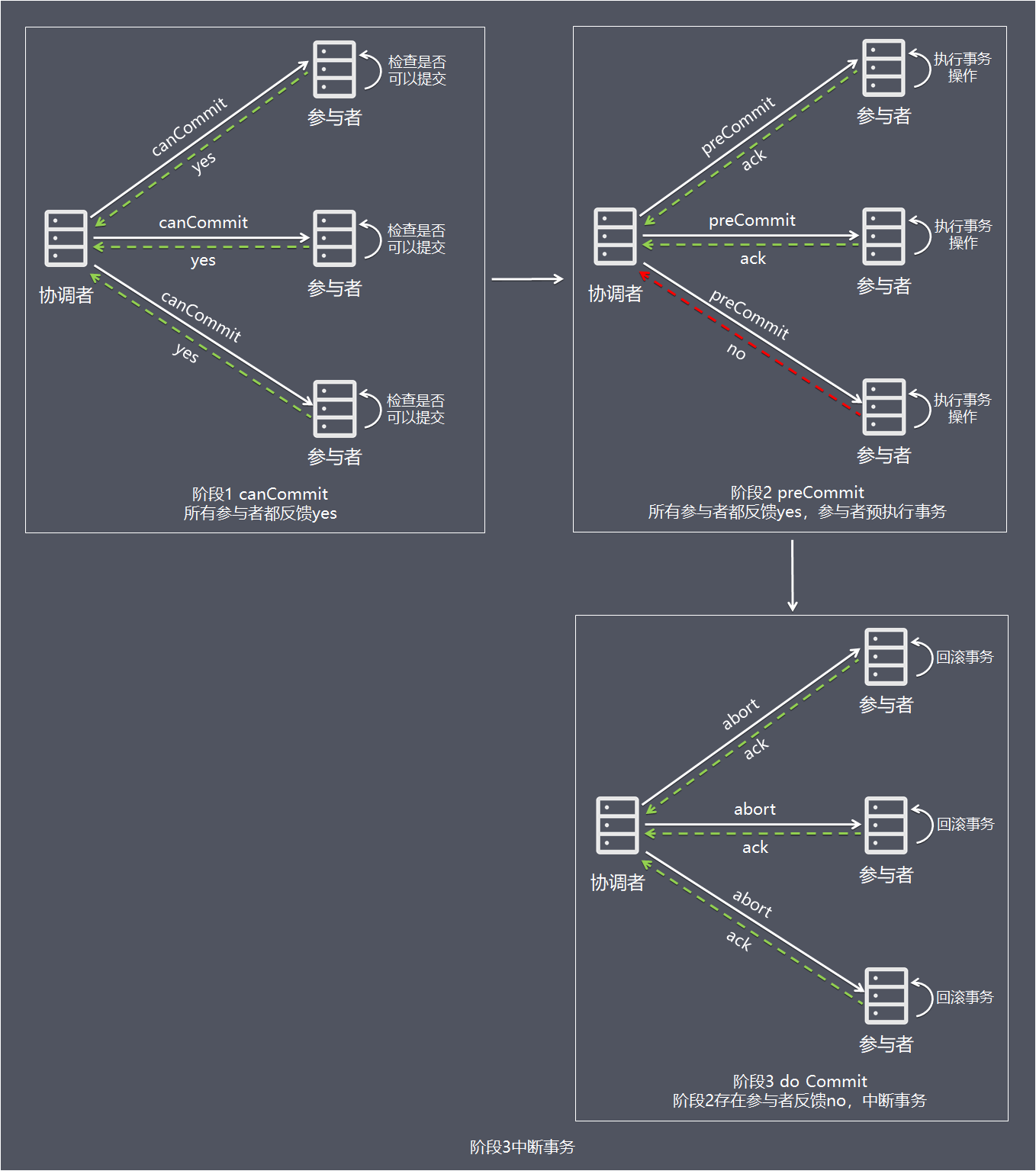
情况2,阶段1任何一个参与者反馈no,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务:
- 1、协调者向所有参与者发出preCommit请求,进入准备阶段。
- 2、参与者收到preCommit请求后,执行事务操作,将undo和redo信息记入事务日志中(但不提交事务)。
- 3、各参与者向协调者反馈ack响应或no响应,并等待最终指令。
阶段3:do Commit
- 1、协调者向所有参与者发出abort请求。
- 2、无论收到协调者发出的abort请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务。
该阶段进行真正的事务提交,也可以分为以下两种情况:情况1:阶段2所有参与者均反馈ack响应,执行真正的事务提交:
阶段2任何一个参与者反馈no,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务:
- 1、如果协调者处于工作状态,则向所有参与者发出do Commit请求。
- 2、参与者收到do Commit请求后,会正式执行事务提交,并释放整个事务期间占用的资源。
- 3、各参与者向协调者反馈ack完成的消息。
- 4、协调者收到所有参与者反馈的ack消息后,即完成事务提交。
注意:进入阶段3后,无论协调者出现问题,或者协调者与参与者网络出现问题,都会导致参与者无法接收到协调者发出的do Commit请求或abort请求。此时,参与者都会在等待超时之后,继续执行事务提交。
- 1、如果协调者处于工作状态,向所有参与者发出abort请求。
- 2、参与者使用阶段1中的undo信息执行回滚操作,并释放整个事务期间占用的资源。
- 3、各参与者向协调者反馈ack完成的消息。
- 4、协调者收到所有参与者反馈的ack消息后,即完成事务中断
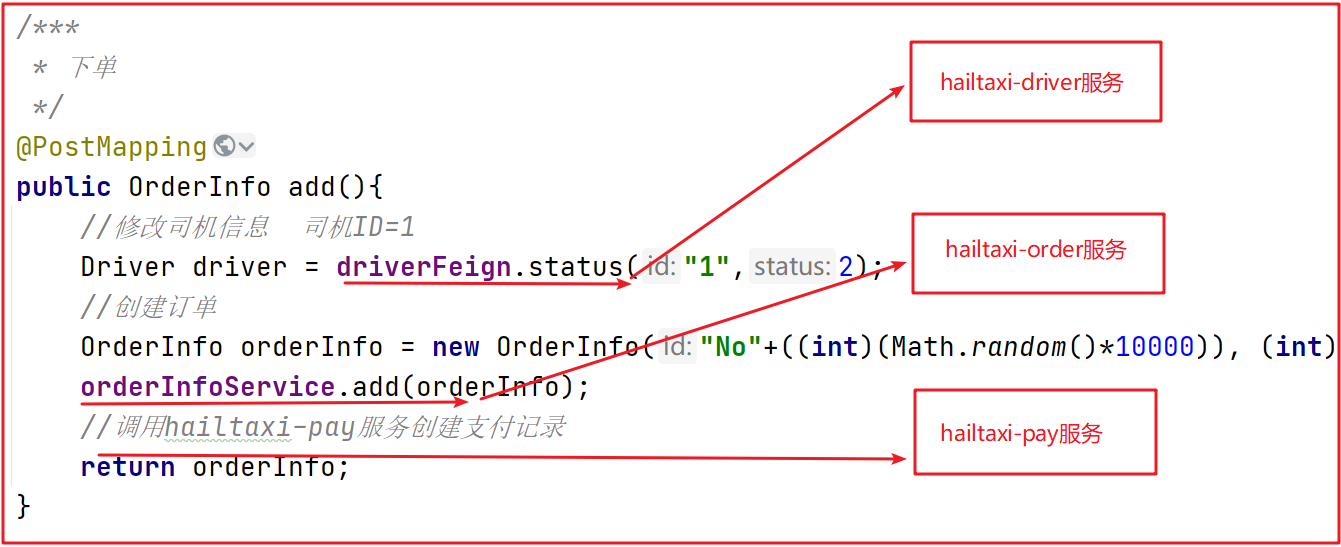
为了方便理解,下面以电商下单为例进行方案解析,这里把整个过程简单分为扣减库存,订单创建2个步骤,库存服务和订单服务分别在不同的服务器节点上。阶段1:Try 阶段
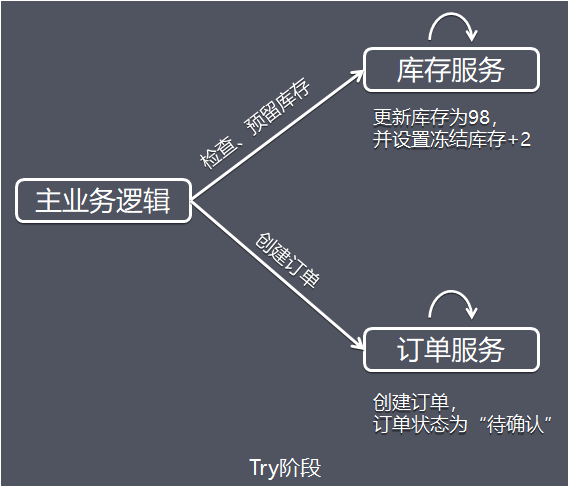
假设商品库存为100,购买数量为2,这里检查和更新库存的同时,冻结用户购买数量的库存,同时创建订单,订单状态为待确认。阶段2:Confirm / Cancel 阶段
根据Try阶段服务是否全部正常执行,继续执行确认操作(Confirm)或取消操作(Cancel)。Confirm:确认
Confirm和Cancel操作满足幂等性,如果Confirm或Cancel操作执行失败,将会不断重试直到执行完成。
当Try阶段服务全部正常执行, 执行确认业务逻辑操作
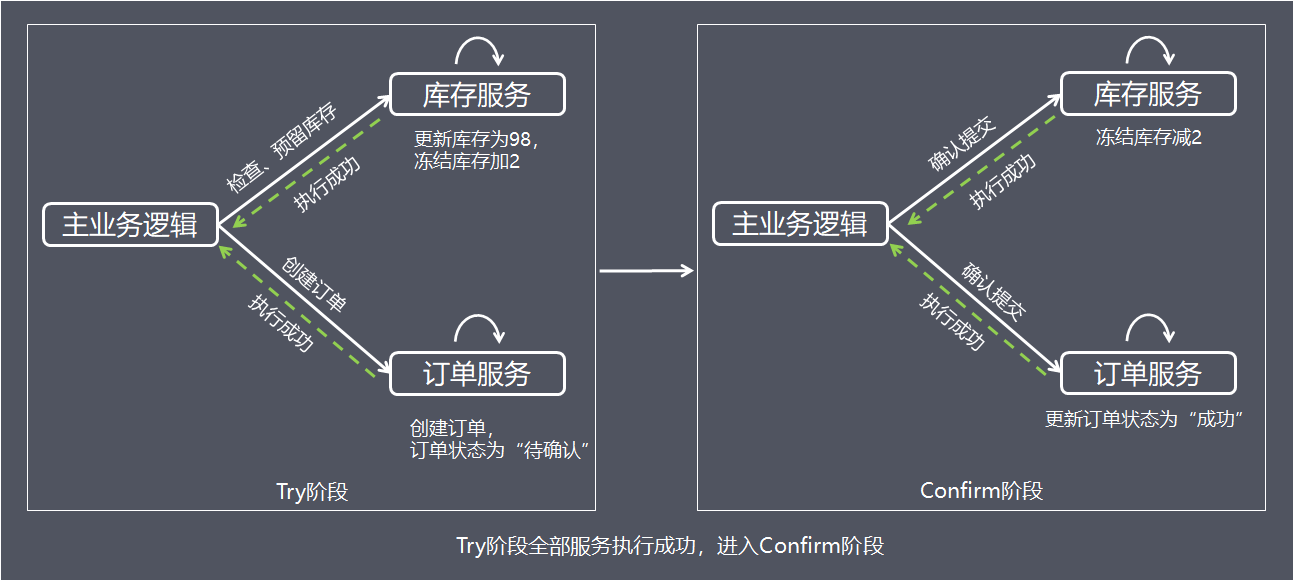
这里使用的资源一定是Try阶段预留的业务资源。在TCC事务机制中认为,如果在Try阶段能正常的预留资源,那Confirm一定能完整正确的提交。Confirm阶段也可以看成是对Try阶段的一个补充,Try+Confirm一起组成了一个完整的业务逻辑。Cancel:取消
当Try阶段存在服务执行失败, 进入Cancel阶段

Cancel取消执行,释放Try阶段预留的业务资源,上面的例子中,Cancel操作会把冻结的库存释放,并更新订单状态为取消。方案总结
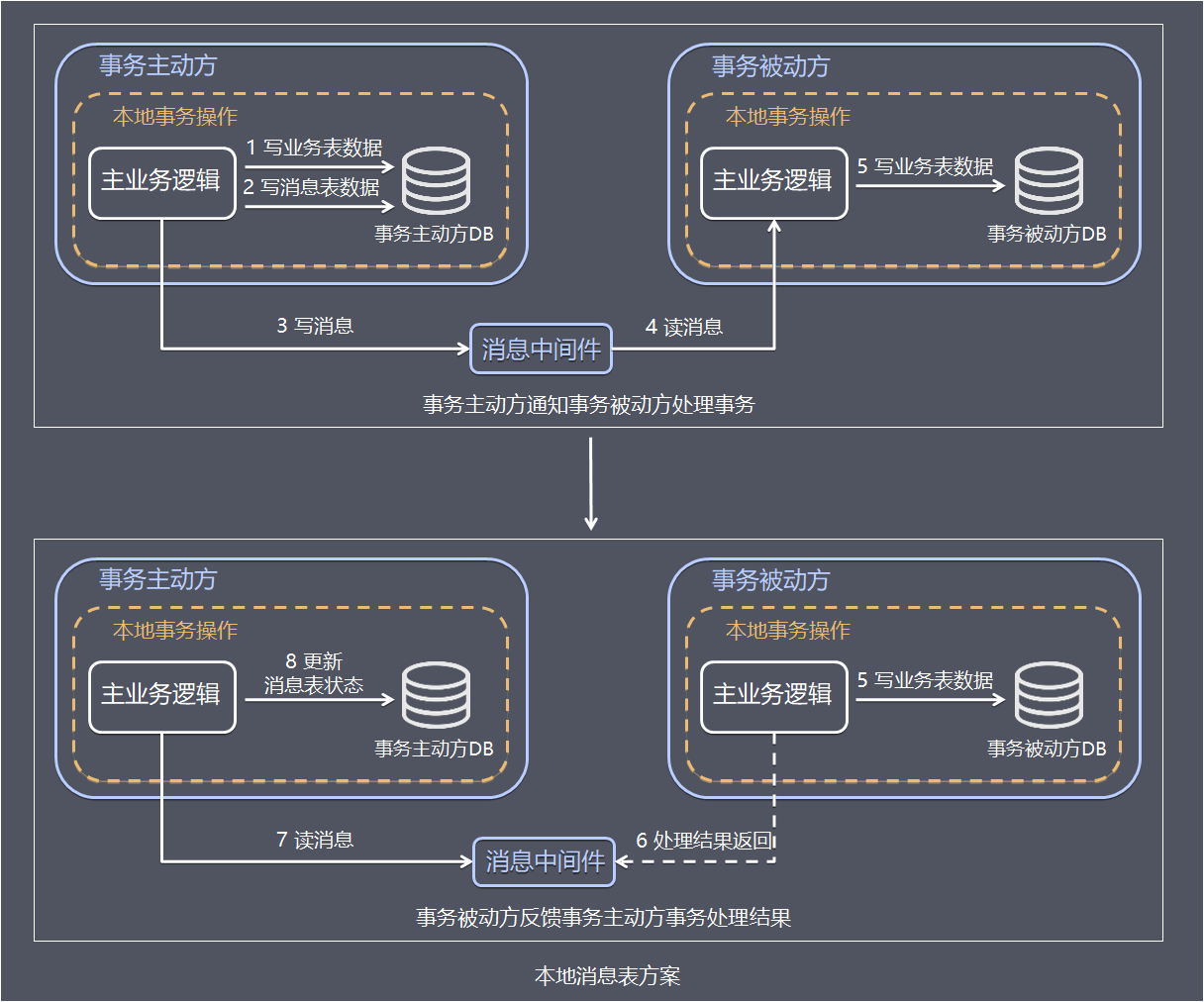
步骤1 事务主动方处理本地事务。为了数据的一致性,当处理错误需要重试,事务发送方和事务接收方相关业务处理需要支持幂等。具体保存一致性的容错处理如下:
事务主动方在本地事务中处理业务更新操作和写消息表操作。
上面例子中库存服务阶段在本地事务中完成扣减库存和写消息表(图中1、2)。
步骤2 事务主动方通过消息中间件,通知事务被动方处理事务通知事务待消息。
消息中间件可以基于Kafka、RocketMQ消息队列,事务主动方法主动写消息到消息队列,事务消费方消费并处理消息队列中的消息。
上面例子中,库存服务把事务待处理消息写到消息中间件,订单服务消费消息中间件的消息,完成新增订单(图中3 - 5)。
步骤3 事务被动方通过消息中间件,通知事务主动方事务已处理的消息。
上面例子中,订单服务把事务已处理消息写到消息中间件,库存服务消费中间件的消息,并将事务消息的状态更新为已完成(图中6 - 8)
1、当步骤1处理出错,事务回滚,相当于什么都没发生。方案总结
2、当步骤2、步骤3处理出错,由于未处理的事务消息还是保存在事务发送方,事务发送方可以定时轮询为超时消息数据,再次发送的消息中间件进行处理。事务被动方消费事务消息重试处理。
3、如果是业务上的失败,事务被动方可以发消息给事务主动方进行回滚。
4、如果多个事务被动方已经消费消息,事务主动方需要回滚事务时需要通知事务被动方回滚。
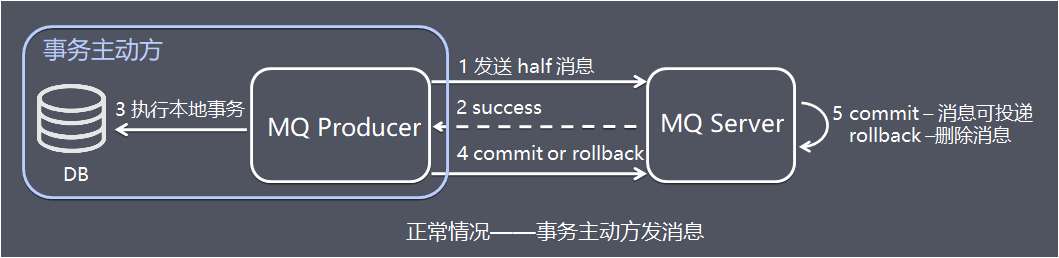
1、发送方向 MQ服务端(MQ Server)发送half消息。异常情况——事务主动方消息恢复
2、MQ Server 将消息持久化成功之后,向发送方 ACK 确认消息已经发送成功。
3、发送方开始执行本地事务逻辑。
4、发送方根据本地事务执行结果向 MQ Server 提交二次确认(commit 或是 rollback)。
5、MQ Server 收到 commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到 rollback 状态则删除半消息,订阅方将不会接受该消息。
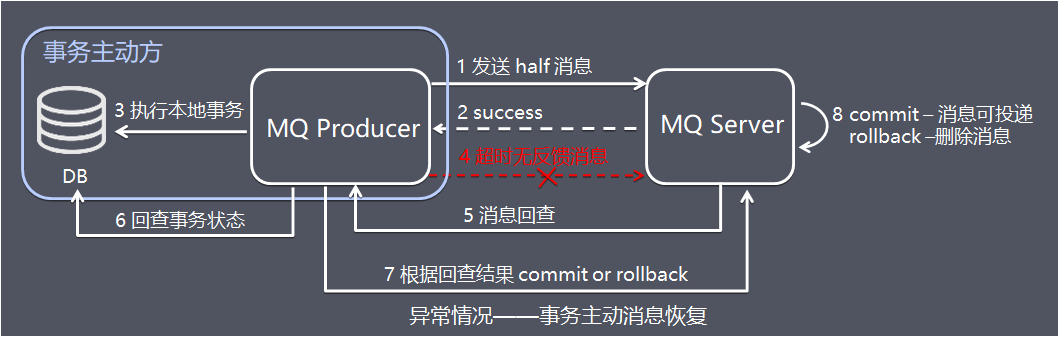
介绍完RocketMQ的事务消息方案后,由于前面已经介绍过本地消息表方案,这里就简单介绍RocketMQ分布式事务:
- 5、MQ Server 对该消息发起消息回查。
- 6、发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 7、发送方根据检查得到的本地事务的最终状态再次提交二次确认
- 8、MQ Server基于commit / rollback 对消息进行投递或者删除
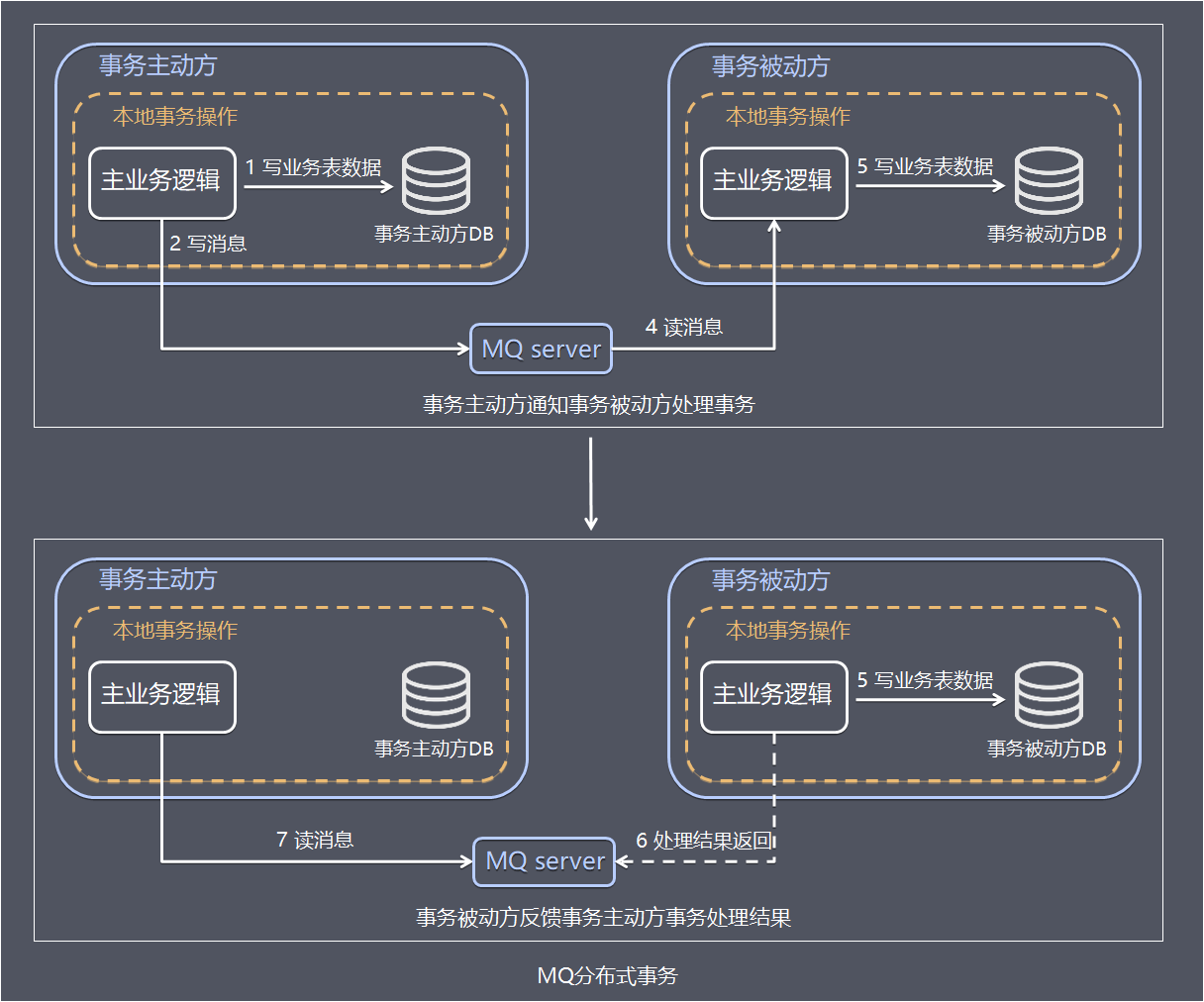
事务主动方基于MQ通信通知事务被动方处理事务,事务被动方基于MQ返回处理结果。方案总结
如果事务被动方消费消息异常,需要不断重试,业务处理逻辑需要保证幂等。
如果是事务被动方业务上的处理失败,可以通过MQ通知事务主动方进行补偿或者事务回滚。
本文由传智教育博学谷 - 狂野架构师教研团队发布
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力
转载请注明出处!
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |