开启tsdb导致的各种问题:canal默认开启tsdb功能,也就是会通过h2数据库缓存解析的表结构,但是实际情况下,如果上游变更了表结构,h2数据库对应的缓存是不会更新的,这个时候一般会出现神奇的解析异常,异常的信息一般如下:‘Caused by: com.alibaba.otter.canal.parse.exception.CanalParseException: column size is not match for table’,该异常还会导致一个可怕的后果:解析线程被阻塞,也就是binlog事件不会再接收和解析。目前认为比较可行的解决方案是:禁用tsdb功能,也就是canal.instance.tsdb.enable设置为false。如果不禁用tsdb功能,一旦出现了该问题,必须要「先停止」Canal服务,接着「删除」$CANAL_HOME/conf/目标数据库实例标识/h2.mv.db文件,然后「启动」Canal服务。目前我们是设置为禁用的。
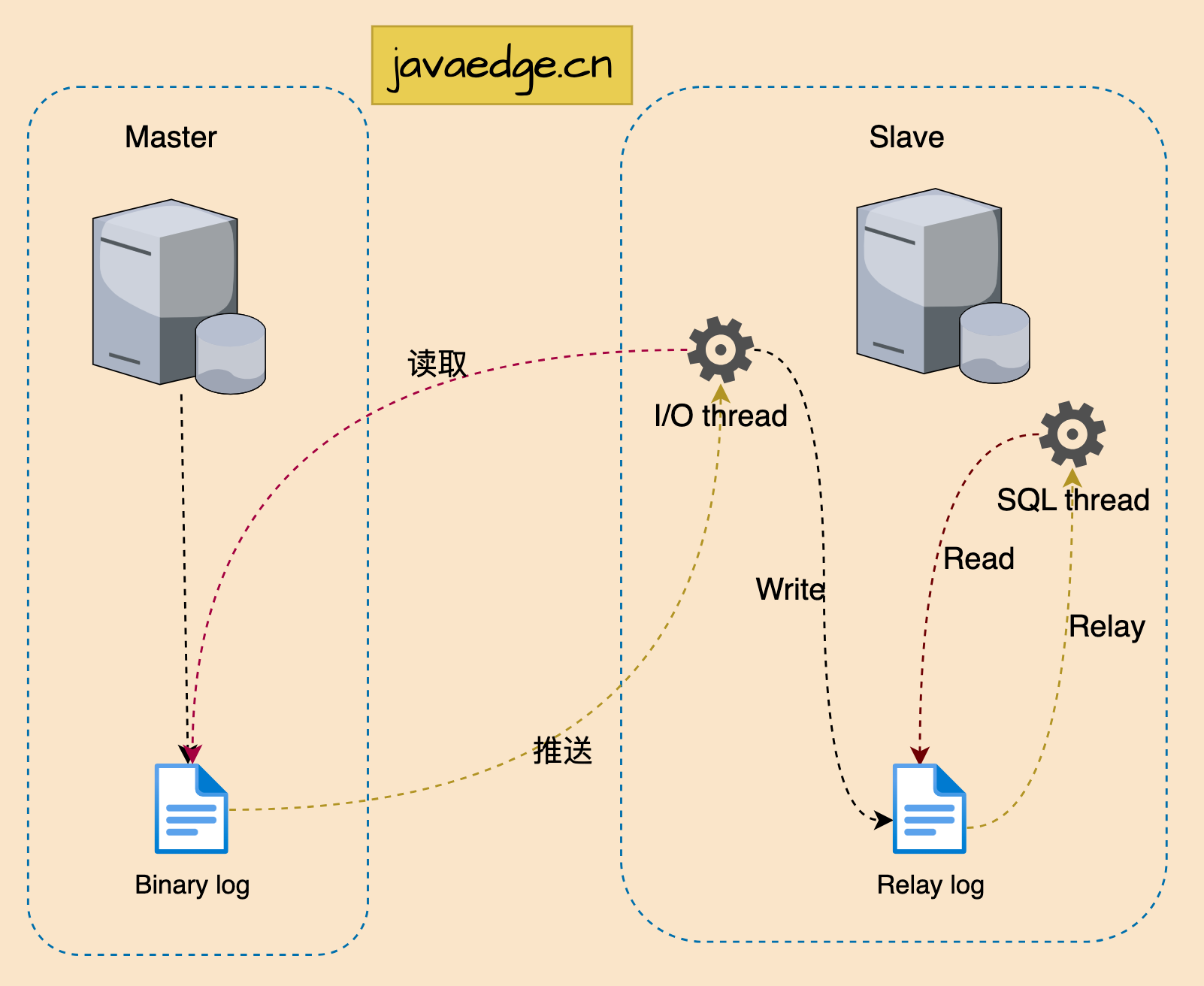
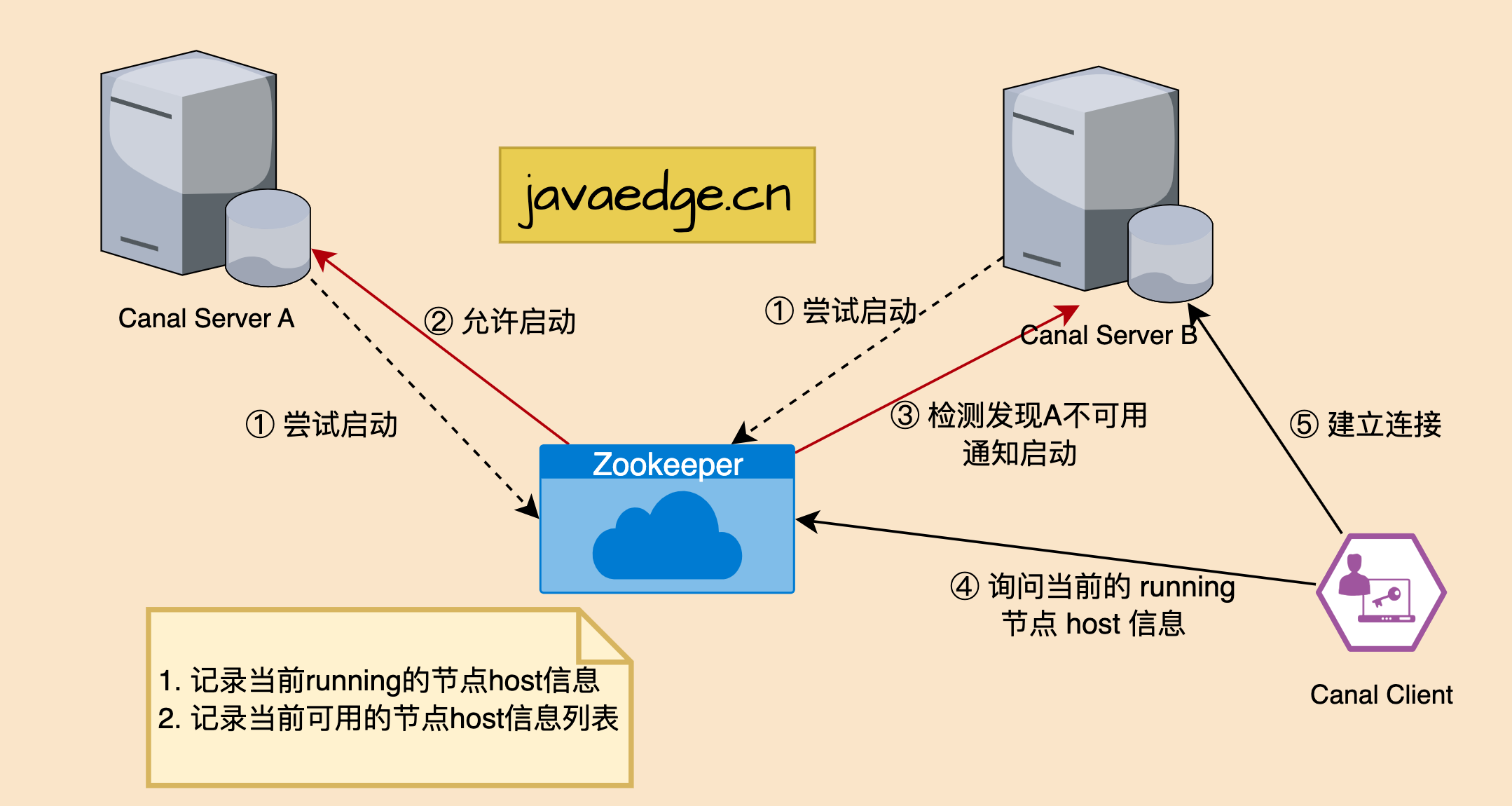
如果发现Canal Client 长时间获取不到binlog消息,可以去Canal Admin 后台去看一下Instance管理中的日志。大概率会出现“could not find first log file name in binary log index file”,这个是因为zk集群中缓存了binlog信息导致拉取的数据不对,包括定义了binlog position但是启动服务后不对也是同样的原因。
解决:
ES的Update By Query对应的就是关系型数据库的update set ... where...语句;该命令在ES上支持得不是很成熟,可能会导致的问题有:批量更新时非事务模式执行(允许部分成功部分失败)、大批量操作会超时、频繁更新会报错(版本冲突)、脚本执行太频繁时又会触发断路器等。我们的解决办法也比较简单,直接在生产环境放弃使用updateByQuery方法,配置成使用先查询出符合条件的数据,然后分发到MQ中单条分别更新的模式。
5 规划